本文地址:ComNet: Combination of Deep Learning and Expert Knowledge in OFDM Receivers
前言
深度通信网络专栏: 快速上手: 2018-2019年最新深度学习用于无线通信(物理层)的论文整理,附论文核心思想总结与代码分析。一点拙见,如有偏颇,望不吝赐教,顺颂时祺。
文章中心思想
本文的思想如题目所述: 将深度学习与传统通信理论相结合。 相比于Power of deep learning for channel estimation and signal detection in OFDM systems中, 简单地将OFDM接收机视为一个黑箱子并用深度网络DNN来实现, 本文基于一些现有的传统通信理论,旨在简化网络模型和加快训练速度。这样的做法已经逐渐被应用到各种通信问题中,主要得益于几个重要优点:
- 通过传统通信中累积的大量前人工作来初始化网络, 可以极大地提升训练效率,减小数据依赖, 降低整体复杂度。
- 使得每个子网络有清晰的物理意义,从而更容易地进行调整,获得进一步增益。
用一句原文的话来说就是:
Instead of using straightforward FC-DNN as in [4] to estimate the transmitted data in a brute force manner, in the proposed ComNet receiver, the CE and SD subnets use traditional communication solutions as initializations and apply DL networks to refine the coarse inputs.
如文中所述,之前的方法可归为Data-Driven, 而本文方法可归为是Model-Driven。
全文概览
系统模型

由于有Power of deep learning for channel estimation and signal detection in OFDM systems珠玉在前,本文无时无刻不体现出与之的对比。 核心区别点就如题目所说: 结合传统理论来优化网络结构。为达到这一点,这个系统模型有两点重要不同:
- 既然要结合传统理论,就不能再将接收机视为简单的黑箱子。 因此, **本文的网络仍按照传统通信的方式,设置了两个subNet, 分别用于信道估计与信号检测。
- 这样分割的优势点就在于每个网络都有了鲜明的物理意义,同时,经典理论中的Sub-optimal solution就可以作为深度网络的初始点。众所周知,神经网络本质上是梯度下降法,有效的初始点可以极大提升收敛性能。 另外一个优势在于 估计出的信道不仅仅能用于数据检测,也有feedback回发送端之类的其他用途,这一点是黑箱子无法做到的。
- 作者不仅仅使用了WMMSE解作为了LS_Refine网络的初始点,更重要的是,相比于许多工作中简单将原始的接收数据输入到网络的方式,作者使用LS信道估计器及ZF接收机先对原始数据进行了预处理,再通过网络,这一点也体现了Model-Driven。
- 作者使用了双向LSTM网络来构建SD网络,不过相比于其核心思想,此处对网络的改进显得不甚重要。
训练流程
据此,总结一下网络的训练流程。 其实这张图片已经将大致过程准确体现了 (实线部分为深度学习流程,虚线为传统算法流程),这里给出一个文字版的总结:
-
导频数据 和 接收到的 ,作为CE subnet的输入,进行信道估计。 注意:
先使用LS估计器对信道进行预估计。再将其输入一个全连接层(无激活函数)进行处理。这里我持怀疑的一点在于,在没有任何其余信息的情况下,神经网络如何能够将LS的估计结果提升呢?原理是什么。 在我的理解中,将 也一并输入到网络中,更能获得提升。
-
估计出的信道与接收数据 作为输入数据输入到SD subnet中进行数据检测。首先,由一个ZF均衡器获得一个粗略检测的结果,然后将其与 , 联结后一并输入到检测网络中。如下图所示:
这个网络可能更符合我的理解,即将几乎所有能给网络的信息都给了网络。而 先前的信道估计网络则让我有点感觉到巧妇难为无米之炊的味道,实在不知增益应当从何而来。

-
由于作者定义了检测网络的输出即为通过sigmoid激活函数得到的(0,1)之间的数(由是否大于0.5判为0或1),损失函数也是非常自然的使用了最常见的MSE。优化器等其他配置与其他paper大致相似。
-
几点补充:
-
由于不使用激活函数,信道估计网络(LS_RefineNet)事实上就是一个线性变换矩阵。因此, 可以用传统算法中的WMMSE解来作为网络神经元的初始权重。
-
文章中使用了 Bi-directional long short-term memory (BiLSTM)-SD网络层来构建ZF_RefineNet, 仿真结果中体现了更好的性能。可以在一定程度上说明RNN在接收机中的能力,然而需要更进一步的对比才能下定论。
-
两个网络虽然共享了一个损失函数,但是作者并没有采取一起优化的策略。(可能是考虑到深度太大难以训练的问题?)作者使用的仿真是先固定SD网络,训练CE。 再固定CE,训练SD。 这个对Auto-Encoder网络的训练可能也具有指导意义。
-
关于如何在tensorflow中训练复数输入,本文没有新的改变,沿用了最常用的方式:将实部虚部独立拆分后拼接,如图所示:
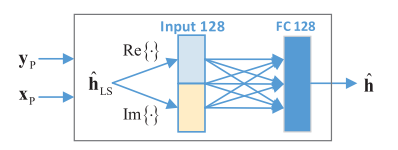
-
仿真结果
文章最后,给出了以下几种算法在多种情况下的性能:
算法
- LMMSE-MMSE: 使用LMMSE(线性最小均方误差)信道估计与MMSE信号检测(根据作者团队其他paper来看,也是LMMSE)。 **这一方法作为较为基本的传统方法的代表,与新的深度学习算法对比。
- FC-DNN: Power of deep learning for channel estimation and signal detection in OFDM systems 这篇paper的网络。
- 本文自己提出的两种结构,分别为: ComNet-FC和ComNet-BiLSTM。
- Y/H_true: 假定信道已知的最大似然解,可以说是传统算法的最优了。
这里的一个小疑问在于作者使用了64-QAM而非Power of deep learning for channel estimation and signal detection in OFDM systems中的4QAM符号,这样的对比是否有刻意之嫌?个人感觉用4QAM更具说服力
信道估计
由于有一个信道估计网络,所以可以比较其信道估计性能。

可以看到结论可概括为:
- ComNet性能全面压制传统算法,在不使用CP的情况下,性能堪称碾压。
信号检测
这里应该指的是使用CENet估计出的信道信息放进SDNet进行检测。

可以看到ComNet的性能是超过了Power of deep learning for channel estimation and signal detection in OFDM systems的。

这两张图则继承了神经网络算法一贯的传统:面对一些极端条件时性能很好,比如图中展示的无CP情况和无CR情况。
复杂度分析
作者使用了floating-point multiplication-adds (FLOPs) 来衡量网络的复杂度。需要注意的是, 这里的FLOPs不等同于以往的定义,如:
- FLOPS: floting-point operations per second
- FLOPs: floting-point operations
与作者的定义都不同。这里应该认为只统计乘法的复杂度。
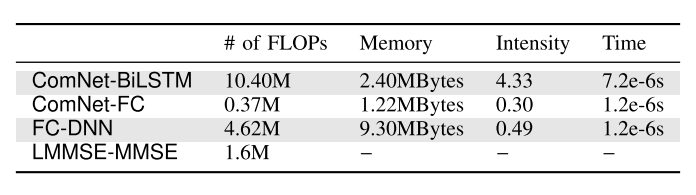
由于文章的篇幅限制,作者没有进一步给出表格中数据的具体计算过程,不得不说,因此很难准确确定作者的计算准则。
几点疑问
- 作者提出其算法对抗mismatched SNR具有鲁棒性,然而仿真中只画了一个点(红叉点)来表示。 事实上作者完全可以画出一条线或者多几个点,一个点的话很可能有所偏颇。
- 在Fig. 6中,作者没有画出ComNet-FC的图,个人觉得应该画一下,还是说和FC-DNN差不多,因此就省略了?
- 为什么选用了64QAM,是因为4QAM下不能跑出想要的结果么?
以及其CENet的设计,很可能增益单纯来自于对训练数据的过拟合,在实际应用中的效果有待商榷。加之作者没有给出源代码,这一实验结果需要持保留态度。 但无论如何,这一篇文章的思路也是值得借鉴的。
