优化算法:
1.mini-bitch:
如果数据集特别大,把所有的数据一起处理会使训练速度特别慢。mini-bitch就是把数据集平均分成几个部分,然后单独进行处理,选择合理的子数据集大小会使训练速度快很多。
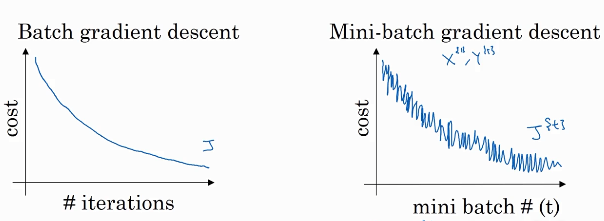
左图为未采用m-b的图像,右图是采用的。可以看出采用之后的J并不是一直下降的,但是整体下降速度快。

如果m-b的子集大小是整个训练集,那么和不采用m-b方法是一样的。如果子集为1,那么子集的个数就是训练样本的个数,这种方法叫随机梯度下降。合适的m-b大小往往是不大不小的。三种方法对应左下角的颜色分别为蓝、紫、绿。
2.指数加权平均
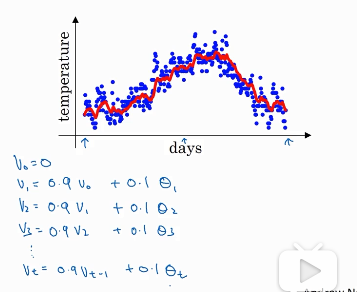
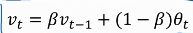
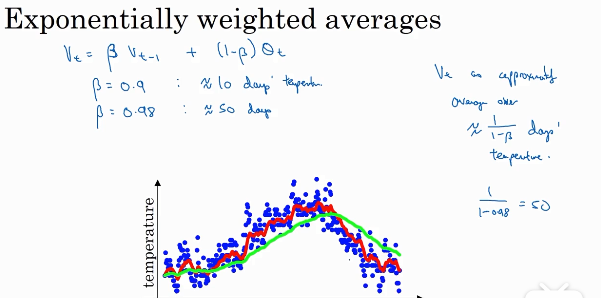
上图为一个例子,图中的蓝点为温度,横轴为日期。V0=0,V1=0.9V0+0.1*当日的温度,以此类推,得到了红色图像。右边这个式子就是指数加权平均的核心。Vt的值近似等于过去1/(1-β)天的平均温度。β越接近1,曲线越平滑。当β=0时,Vt=当天的温度。
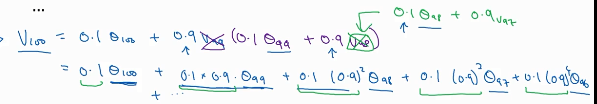 如果β=0.9,那么将V100展开就可得到左边这个式子。
如果β=0.9,那么将V100展开就可得到左边这个式子。
但是,由于Vt=0,所以初期的数据会比真实值小很多,为了修正这个误差,可以在以前式子的基础上加上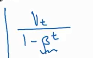 修正误差。但大部分人都不会对误差进行修正。
修正误差。但大部分人都不会对误差进行修正。
3.动量梯度下降法
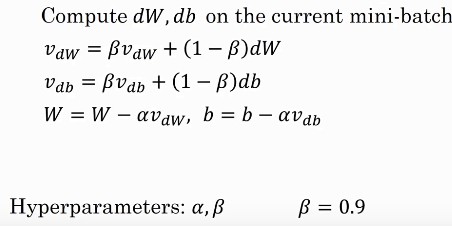
核心如上图。之前的梯度下降法不考虑之前迭代的梯度结果,W=W-adW 。而这种方法利用了指数加权平均,本次的梯度结果Vdw考虑了之前所有的梯度结果。一般贝塔取0.9。Vdw、Vdb的初始值设为0。动量梯度下降法明显好于一般的梯度下降法。
4.Rmsprop
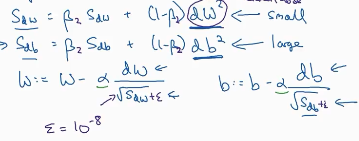 Rmsprop方法与动量梯度下降法类似,公式如左图。
Rmsprop方法与动量梯度下降法类似,公式如左图。
5.Adam
Adam优化算法把动量梯度下降法与Rmsprop方法相结合。

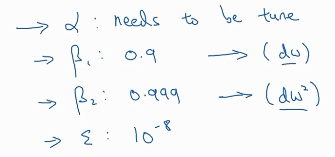
左图就是Adam算法的核心式子,注意上面Sdb的db后面少了个平方。correctd是指的修正偏差。 右图是超参数的常用值。
6.随时间减小学习率
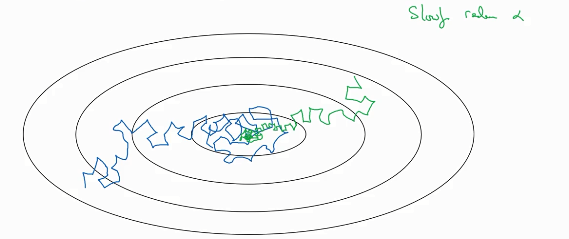
如果学习率是个定值的话,那么J的变化就是蓝色线,可以看出,虽然最后接近极小值,但是在最小值附近的摆动很大。如果学习率逐渐减小的话,就是绿色的,在最小值附近的摆动会很小。 这个和PID控制很像,一开始误差很大,所以比例k很大,在快速接近目标值之后,比例k会逐渐的减小。
 这是学习率衰减的一个方法,decay.。。是超参数,epoch.num是迭代次数。
这是学习率衰减的一个方法,decay.。。是超参数,epoch.num是迭代次数。
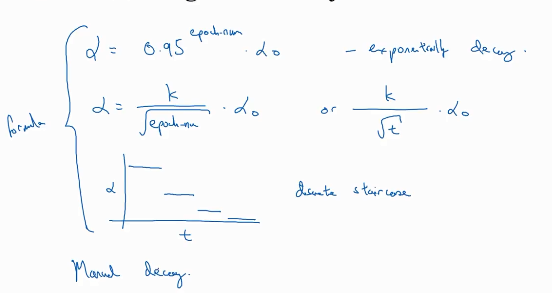 这是另外两种方法。
这是另外两种方法。