一、指数加权平均
说明:在了解新的算法之前需要先了解指数加权平均,这个是Momentum、RMSprop、Adam三个优化算法的基础。
1、指数加权平均介绍:
这里有一个每日温度图(华氏摄氏度℉),右边是每日温度,$\theta _{i}$表示第i天的温度:
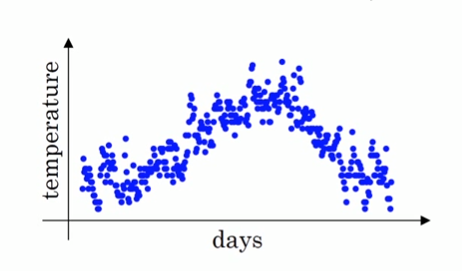
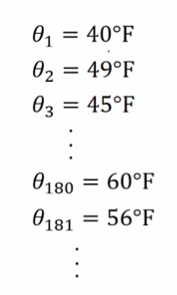
这个时候我们要用一个曲线来拟合这个散点图,则曲线某一天的$y$值可以用某一天的温度的局部平均值来替代,假设我们有前i-1天的温度,这时候要来估计第$i$天的温度$\theta _{i}$,我们可以用第$i$天的前$k$天的平均温度替代,如:$\theta _{i}^{'}=\frac{\theta _{i-1}+...+\theta _{i-k}}{k}$。
但是这样的数据容易出现一个问题,当前5天的数值为10、11、12、13、14、30,可以看到第五天的数据异常偏大,如果用一般均值计算的话会导致波动特别大,拟合值容易出错。
解决方法是我们计算均值的时候,考虑前面k天的影响,对前面的k天加上权值,就能够抵消由于异常值导致数据的过分误差,这就有了指数加权平均,公式如下:
$$V_{i}=\beta V_{i-1}+(1-\beta )\theta _{i}$$
$V_{i}$为第$i$天的温度的近似值,规定$V_{i}=0$,$\theta _{i}$是当天的实际温度,$\beta$是权重,一般设置为0.9,这里列出计算到第$i$天的近似值$V_{i}$的计算公式:
\begin{matrix}
& V_{0}=0 \\&V_{1}=\beta V_{0}+(1-\beta )\theta _{1} \\&V_{2}=\beta V_{1}+(1-\beta )\theta _{2} \\& ... \\& V_{i}=\beta V_{i-1}+(1-\beta )\theta _{i}
\end{matrix}
所以:
\begin{align*}
V_{i} &= \beta V_{i-1}+(1-\beta )\theta _{i}\\
&= \beta \left (\beta V_{i-2}+(1-\beta )\theta _{i-1} \right )+(1-\beta )\theta _{i}\\
&= \beta^{2}V_{i-2}+\beta(1-\beta )\theta _{i-1}+1(1-\beta )\theta _{i}\\
&= \beta^{2}\left (\beta V_{i-3}+(1-\beta )\theta _{i-2} \right )+\beta(1-\beta )\theta _{i-1}+\beta^{0}(1-\beta )\theta _{i}\\
&= \beta^{3}V_{i-3}+\beta^{2}(1-\beta )\theta _{i-2}+\beta(1-\beta )\theta _{i-1}+\beta^{0}(1-\beta )\theta _{i}\\
&= \beta^{i}V_{0}+\beta^{i-1}(1-\beta )\theta_{1}+...+\beta^{0}(1-\beta )\theta _{i}\\
\end{align*}
\begin{matrix}
\because V_{0}=0\\
\therefore V_{i} = \beta^{i-1}(1-\beta )\theta_{1}+\beta^{i-2}(1-\beta )\theta_{2}+...+\beta^{0}(1-\beta )\theta _{i}=\sum_{k=1}^{i}\beta^{i-k}(1-\beta )\theta_{k}
\end{matrix}
这样我们就得到了$V_{i}$的最终等式,把所有的点求解出来然后连线,可以得到一个拟合度较好的红色曲线:
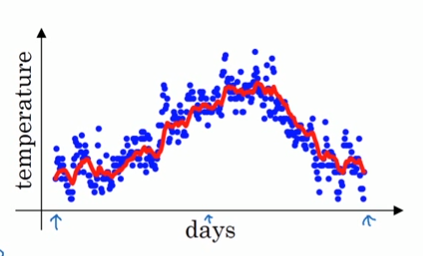
为什么这个方法会叫做指数加权平均呢?我们这里考虑$V_{i}$的值,