mini-batch梯度下降法
相信有一定深度学习常识的人都知道梯度下降
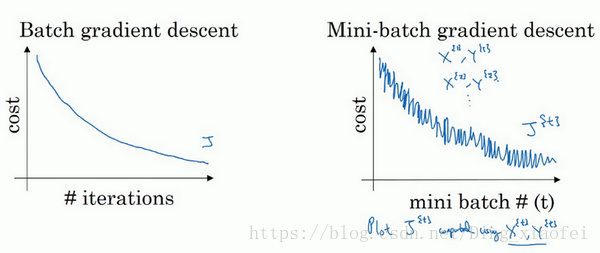
使用batch梯度下降法时,每次迭代你都需要历遍整个训练集,可以预期每次迭代成本都会下降,所以如果成本函数J是迭代次数的一个函数,它应该会随着每次迭代而减少,如果J在某次迭代中增加了,那肯定出了问题,也许你的学习率太大。
使用mini-batch梯度下降法,如果你作出成本函数在整个过程中的图,则并不是每次迭代都是下降的,如果你要作出成本函数J的图,你很可能会看到这样的结果,走向朝下,但有更多的噪声。
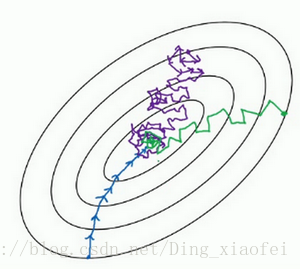
在随机梯度下降法(SGD)中,从某一点开始,我们重新选取一个起始点,每次迭代,你只对一个样本进行梯度下降,大部分时候你向着全局最小值靠近,有时候你会远离最小值,因为那个样本恰好给你指的方向不对,因此随机梯度下降法是有很多噪声的,平均来看,它最终会靠近最小值,不过有时候也会方向错误,因为随机梯度下降法永远不会收敛,而是会一直在最小值附近波动,但它并不会在达到最小值并停留在此。如下图,紫色的线条。

如果使用随机梯度下降法,如果你只要处理一个样本,那这个方法很好,这样做没有问题,通过减小学习率,噪声会被改善或有所减小,但随机梯度下降法的一大缺点是,你会失去所有向量化带给你的加速,因为一次性只处理了一个训练样本,这样效率过于低下,所以实践中最好选择不大不小的mini-batch尺寸,实际上学习率达到最快。你会发现两个好处,一方面,你得到了大量向量化。
这边深有体会的是batch_size的设置对算法的训练速度有很大的影响,如果你的GPU显存够大,size设置大一些,不然训练会非常地慢,这就是和向量化有关的。
下图是三种梯度下降的示意图:
当你使用小批次梯度下降的时候,如果出现小范围的波动,尝试调小学习率。
batch_size的选择
如果训练集较小,直接使用batch梯度下降法,样本集较小就没必要使用mini-batch梯度下降法,你可以快速处理整个训练集,所以使用batch梯度下降法也很好,这里的少是说小于2000个样本,这样比较适合使用batch梯度下降法。不然,样本数目较大的话,一般的mini-batch大小为64到512,考虑到电脑内存设置和使用的方式,如果mini-batch大小是2的n次方,代码会运行地快一些,64就是2的6次方,以此类推,128是2的7次方,256是2的8次方,512是2的9次方。所以我经常把mini-batch大小设成2的次方。
要看自己设备的性能来决定batch_size,如果你处理的mini-batch和CPU/GPU内存不相符,不管你用什么方法处理数据,你会注意到算法的表现急转直下变得惨不忍睹,所以我希望你对一般人们使用的mini-batch大小有一个直观了解。事实上mini-batch大小是另一个重要的变量,你需要做一个快速尝试,才能找到能够最有效地减少成本函数的那个,我一般会尝试几个不同的值,几个不同的2次方,然后看能否找到一个让梯度下降优化算法最高效的大小。
指数加权平均数
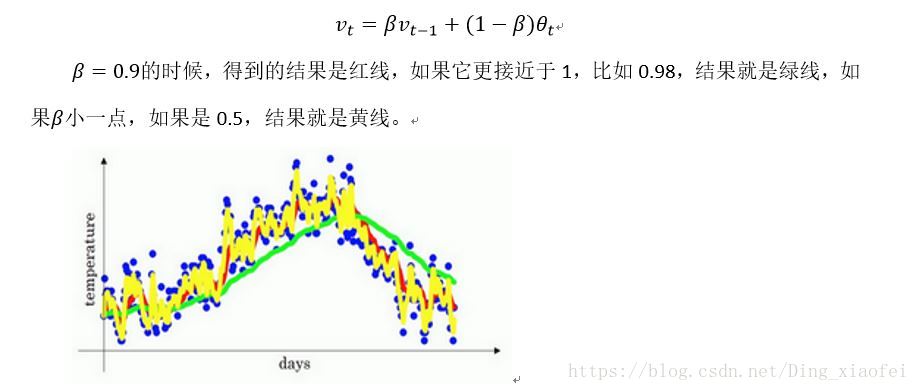
指数加权平均的天数是由B决定的,1/(1-B),如果B=0.9,就是10天的平均。
更多内容请参考吴恩达的deeplearning.ai笔记
为什么要使用指数加权平均数呢?举个简单的例子
如果你要计算移动窗,你直接算出过去10天的总和,过去50天的总和,除以10和50就好,如此往往会得到更好的估测。但缺点是,如果保存所有最近的温度数据,和过去10天的总和,必须占用更多的内存,执行更加复杂,计算成本也更加高昂。
动量梯度下降法(Gradient descent with Momentum)针对于梯度的优化算法
一种算法叫做Momentum,或者叫做动量梯度下降法,运行速度几乎总是快于标准的梯度下降算法,简而言之,基本的想法就是计算梯度的指数加权平均数,并利用该梯度更新你的权重
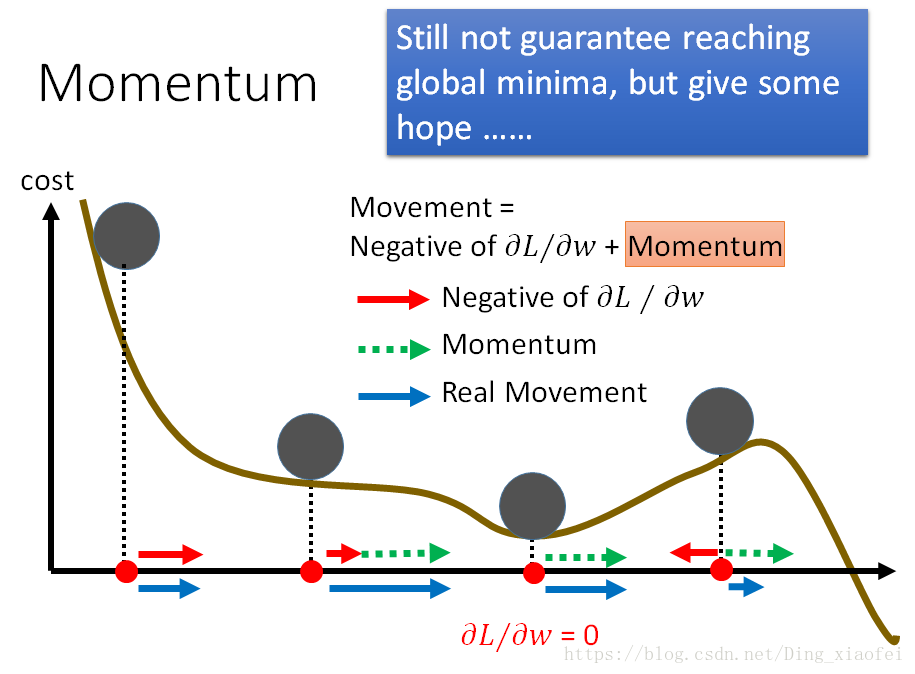
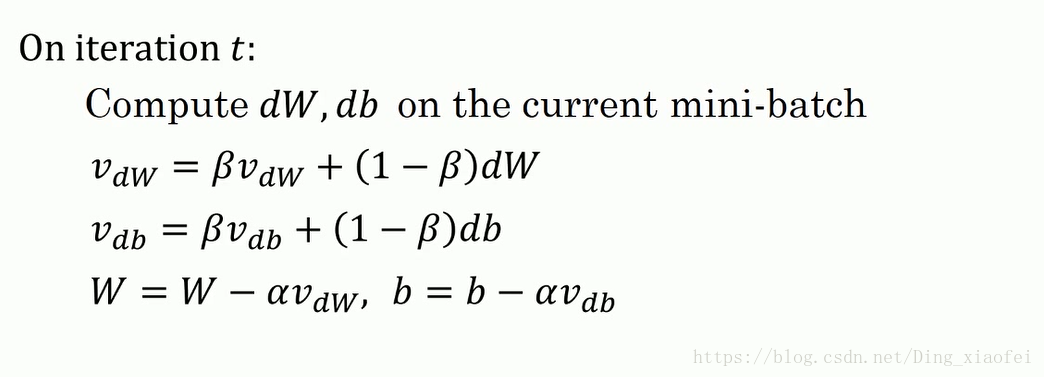
这里可以看到是典型的梯度的加权指数平均,很像物理学中的动量惯性,前面的一些梯度此时刻的梯度产生了一定的影响。
所以你有两个超参数,学习率a以及参数β,β控制着指数加权平均数。β最常用的值是0.9,我们之前平均了过去十天的温度,所以现在平均了前十次迭代的梯度。实际上β为0.9时,效果不错,你可以尝试不同的值,可以做一些超参数的研究,不过0.9是很棒的鲁棒数。
RMSprop


Adam


学习率衰减
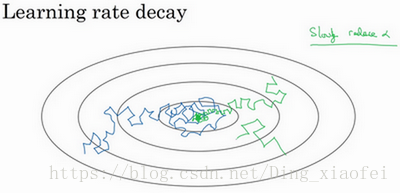
在我们利用 mini-batch 梯度下降法来寻找Cost function的最小值的时候,如果我们设置一个固定的学习速率α,则算法在到达最小值点附近后,由于不同batch中存在一定的噪声,使得不会精确收敛,而一直会在一个最小值点较大的范围内波动,如下图中蓝色线所示。
但是如果我们使用学习率衰减,逐渐减小学习速率α,在算法开始的时候,学习速率还是相对较快,能够相对快速的向最小值点的方向下降。但随着α的减小,下降的步伐也会逐渐变小,最终会在最小值附近的一块更小的区域里波动,如图中绿色线所示。

局部最优
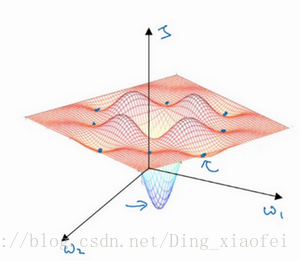
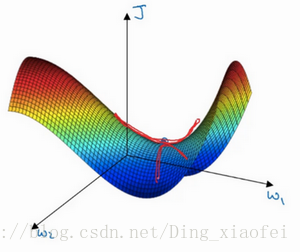
使用adam能够有所改善
参考
https://www.jianshu.com/p/61741ef524b3