转自:https://www.sohu.com/a/149921578_610300
调整模型更新权重和偏差参数的方式时,你是否考虑过哪种优化算法能使模型产生更好且更快的效果?应该用梯度下降,随机梯度下降,还是Adam方法?
这篇文章介绍了不同优化算法之间的主要区别,以及如何选择最佳的优化方法。
什么是优化算法?
优化算法的功能,是通过改善训练方式,来最小化(或最大化)损失函数E(x)。
损失函数E(x):
模型内部有些参数,是用来计算测试集中目标值Y的真实值和预测值的偏差程度的,基于这些参数,就形成了损失函数E(x)。
比如说,权重(W)和偏差(b)就是这样的内部参数,一般用于计算输出值,在训练神经网络模型时起到主要作用。
在有效地训练模型并产生准确结果时,模型的内部参数起到了非常重要的作用。这也是为什么我们应该用各种优化策略和算法,来更新和计算影响模型训练和模型输出的网络参数,使其逼近或达到最优值。
优化算法分为两大类:
1. 一阶优化算法
这种算法使用各参数的梯度值来最小化或最大化损失函数E(x)。最常用的一阶优化算法是梯度下降。
函数梯度:
导数dy/dx的多变量表达式,用来表示y相对于x的瞬时变化率。往往为了计算多变量函数的导数时,会用梯度取代导数,并使用偏导数来计算梯度。梯度和导数之间的一个主要区别是函数的梯度形成了一个向量场。
因此,对单变量函数,使用导数来分析;而梯度是基于多变量函数而产生的(数学角度就是求偏导数)。更多理论细节在这里不再进行详细解释。
2. 二阶优化算法
二阶优化算法使用了二阶导数(也叫做Hessian方法)来最小化或最大化损失函数。由于二阶导数的计算成本很高,所以这种方法并没有广泛使用(我们下面不表,下面主要还是讲一阶梯度下降法)。如牛顿梯度下降。
详解各种神经网络优化算法 :梯度下降
在训练和优化智能系统时,梯度下降是一种最重要的技术和基础。
梯度下降的功能是:
通过寻找最小值,控制方差,更新模型参数,最终使模型收敛。
网络更新参数的公式为:θ=θ−η×∇(θ).J(θ) ,其中η是学习率,∇(θ).J(θ)是损失函数J(θ)的梯度。
这是在神经网络中最常用的优化算法。
如今,梯度下降主要用于在神经网络模型中进行权重更新,即在一个方向上更新和调整模型的参数,来最小化损失函数。
2006年引入的反向传播技术,使得训练深层神经网络成为可能。反向传播技术是以前向传播为基础的,
前向传播:
先在前向传播中计算输入信号的乘积及其对应的权重,然后将激活函数作用于这些乘积的总和。这种将输入信号转换为输出信号的方式,是一种对复杂非线性函数进行建模的重要手段,并引入了非线性激活函数,使得模型能够学习到几乎任意形式的函数映射。
然后,在网络的反向传播过程中回传相关误差,使用梯度下降更新权重值,通过计算误差函数E相对于权重参数W的梯度,在损失函数梯度的相反方向上更新权重参数。
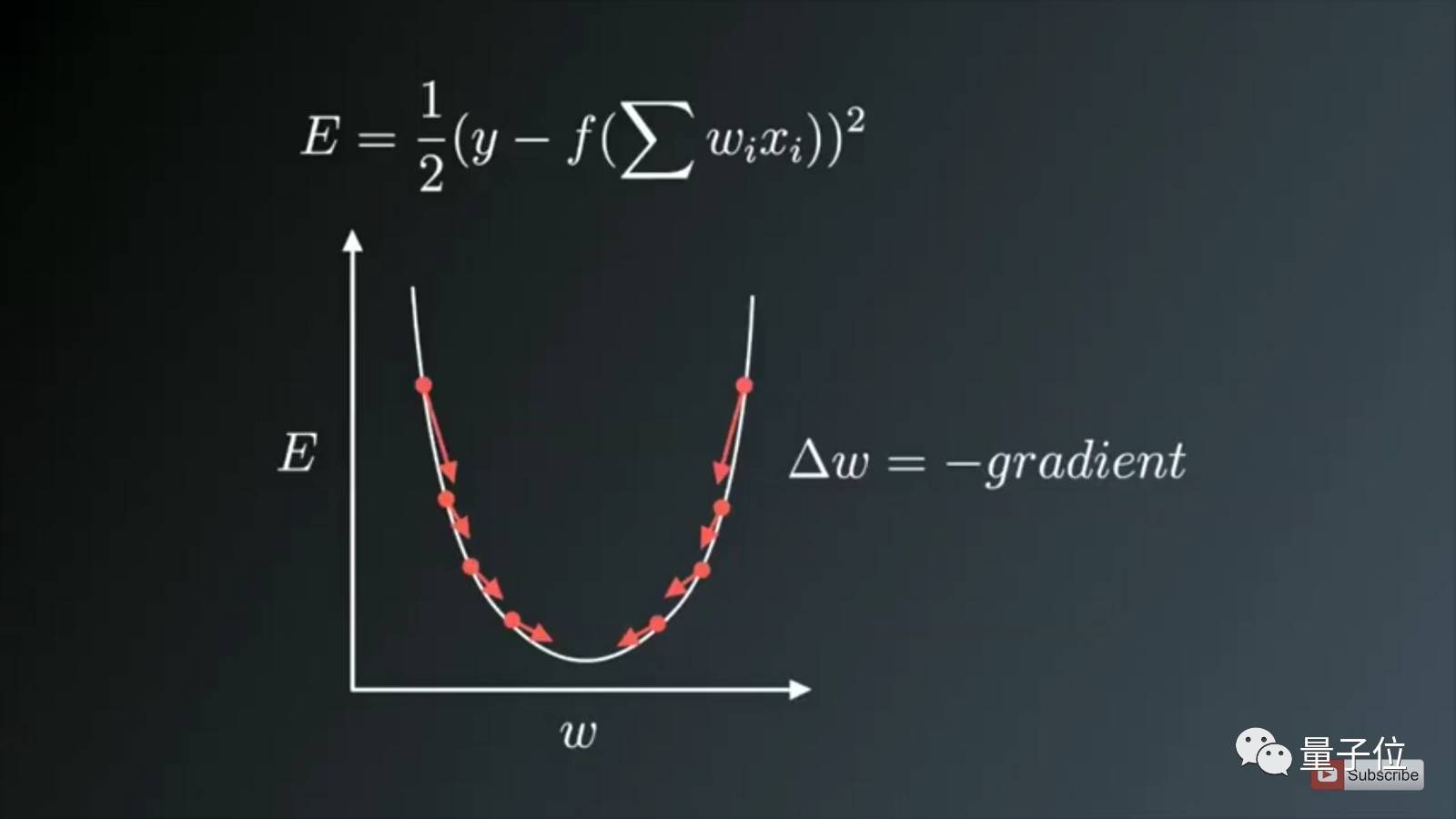
图1:权重更新方向与梯度方向相反。梯度下降法是为了使得损失函数最小,既然是梯度下降,自然就是取梯度的负方向了。
图1显示了权重更新过程与梯度矢量误差的方向相反,其中U形曲线为梯度。要注意到,当权重值W太小或太大时,会存在较大的误差,需要更新和优化权重,使其转化为合适值,所以我们试图在与梯度相反的方向找到一个局部最优值。
分析:
图中表示的是最常见的损失函数表达式,前面取1/2 是为了,一阶梯度的平方求偏导时候可以更加简便。
后面表示用预测值与真实值的误差的平方,表示模型的预测性能,误差值小说明模型预测精准。
里面的累加部分表示神经网络里面的所有参数经过计算后,再经过一系列的非线性函数f(.....)(即激活函数),才得到最终预测的结果。
在数学角度说f(...),我们是在训练一个预测的函数。函数里面包括很多变量(即参数),我们最终的目的就是训练好那些变量,使得预测函数值最小。说人话就是,预测的函数就是模型。我们为了模型更精准,那么模型的预测就越好。
y就是表示真实值。
一般神经网络会累加一个batch的所有数据的误差(而上面的公式表示一个数据的误差值),然后取平均值作为本次batch训练的误差值,然后进行一次反向传播来调节权重(即参数)。即后面的小批量梯度下降,现在通常用这种方法。
梯度下降的变体
传统的批量梯度下降将计算整个数据集梯度,但只会进行一次更新,因此在处理大型数据集时速度很慢且难以控制,甚至导致内存溢出。
权重更新的快慢是由学习率η决定的,并且可以在凸面误差曲面中收敛到全局最优值,在非凸曲面中可能趋于局部最优值。
使用标准形式的批量梯度下降还有一个问题,就是在训练大型数据集时存在冗余的权重更新(一般数据量越多,数据维度越大,那么应该对应增加神将网络的参数数目,才能学的更好,但整个数据一次输入去学习那么会有更多的维度,权重自然更多,那就冗余了)。
标准梯度下降的上述问题在随机梯度下降方法中得到了解决。
1. 随机梯度下降(SGD)
随机梯度下降(Stochastic gradient descent,SGD)对每个训练样本进行参数更新,每次执行都进行一次更新,且执行速度更快。
θ=θ−η⋅∇(θ) × J(θ;x(i);y(i)),其中x(i)和y(i)为训练样本。
频繁的更新使得参数间具有高方差,损失函数会以不同的强度波动。这实际上是一件好事,因为它有助于我们发现新的和可能更优的局部最小值。反过来也,有人认为,一次只以一个数据来调整整个网络权重,容易陷入局部最小值,更加难发现整体最小值,而且一个数据很难代表整个数据的分布。个人偏向后者观点。
但SGD的问题是,由于频繁的更新和波动,最终将收敛到最小限度,并会因频繁波动存在超调量(一个数据调节一次,那计算量太大了)。
虽然已经表明,当缓慢降低学习率η时,标准梯度下降的收敛模式与SGD的模式相同。

图2:每个训练样本中高方差的参数更新会导致损失函数大幅波动,因此我们可能无法获得给出损失函数的最小值。
另一种称为“小批量梯度下降”的变体,则可以解决高方差的参数更新和不稳定收敛的问题。
2. 小批量梯度下降
为了避免SGD和标准梯度下降中存在的问题,一个改进方法为小批量梯度下降(Mini Batch Gradient Descent),因为对一个批次中的n个训练样本,这种方法只执行一次梯度下降更新。
使用小批量梯度下降的优点是:
1)可以减少参数更新的波动,最终得到效果更好和更稳定的收敛。
2)还可以使用最新的深层学习库中通用的矩阵优化方法,使计算小批量数据的梯度更加高效。
3)通常来说,小批量样本的大小范围是从50到256,可以根据实际问题而有所不同。
4)在训练神经网络时,通常都会选择小批量梯度下降算法。
这种方法有时候还是被成为SGD。
使用梯度下降及其变体时面临的挑战。
1.很难选择出合适的学习率。太小的学习率会导致网络收敛过于缓慢,而学习率太大可能会影响收敛,并导致损失函数在最小值上波动,甚至出现梯度发散。
2.此外,相同的学习率并不适用于所有的参数更新。如果训练集数据很稀疏,且特征频率非常不同,则不应该将其全部更新到相同的程度,但是对于很少出现的特征,应使用更大的更新率。
3.在神经网络中,最小化非凸误差函数的另一个关键挑战是避免陷于多个其他局部最小值中。实际上,问题并非源于局部极小值,而是来自鞍点,即一个维度向上倾斜且另一维度向下倾斜的点。这些鞍点通常被相同误差值的平面所包围,这使得SGD算法很难脱离出来,因为梯度在所有维度上接近于零。