torch.autograd.backward(variables, grad_variables, retain_variables=False)
当前Variable对leaf variable求偏导。
计算图可以通过链式法则求导。如果Variable是 非标量(non-scalar)的,且requires_grad=True。那么此函数需要指定gradient,它的形状应该和Variable的长度匹配,里面保存了Variable的梯度。
此函数累积leaf variable的梯度。你可能需要在调用此函数之前将Variable的梯度置零。
参数说明:
-
variables (variable 列表) – 被求微分的叶子节点,即
ys。 -
grad_variables (
Tensor列表) – 对应variable的梯度。仅当variable不是标量且需要求梯度的时候使用。见下例中的c.backward(torch.ones(a.size())) -
retain_variables (bool) –
True,计算梯度时所需要的buffer在计算完梯度后不会被释放。如果想对一个子图多次求微分的话,需要设置为True。
# retain_variables用法
x = V(t.ones(3))
w = V(t.rand(3),requires_grad=True)
y = w.mul(x)
z = y.sum()
z.backward(retain_graph=True)
print(w.grad)
z.backward()#保留了上一次的结果,才能再一次backward()否则图也解散第二次backward()会报错:Trying to backward through the graph a second time, but the buffers have already been freed. Specify retain_graph=True when calling backward the first time 当然你也可以选择再构造一次图 y = w.mul(x) z = y.sum()然后再backward()也可以
print(w.grad)
Variable containing: 1 1 1 Variable containing:【第二次结果是进行了累加第一次】 2 2 2
在PyTorch中计算图的特点可总结如下:
叶子节点对象【用户自己创造的对象】是一个 AccumulateGrad Object 表示梯度累加对象。通过grad_fn.next_functions可得。
非叶子节点的梯度计算完之后即被清空,grad为None 用 retain_grad可保留中间梯度
a = V(t.ones(3,4),requires_grad=True) 叶子节点 grad_fn为None backward后grad有
b = V(t.zeros(3,4))requires_grad=False 叶子节点 grad_fn为None backward后grad无
c = a.add(b) 所有依赖a的节点requires_grad=True grad_fn为AddBackward1 backward后grad无
d = c.sum() 所有依赖a的节点 requires_grad=True grad_fn为sumBackward1 backward后grad无
d.backward() 这时候d是标量12,所以可以省略backward的grad_variable参数,默认(torch.FloatTensor([1]))
c.backward(torch.ones(a.size())) c 是向量,需定义backward的grad_variable参数,表示每一个都是1倍梯度。
- autograd根据用户对variable的操作
Function构建其计算图。对变量的操作抽象为Function。 - 对于那些不是任何函数(Function)的输出,由用户创建的节点称为叶子节点,叶子节点的
grad_fn为None。叶子节点中需要求导的variable,具有AccumulateGrad标识,因其梯度是累加的。 - variable默认是不需要求导的,即
requires_grad属性默认为False,如果某一个节点requires_grad被设置为True,那么所有依赖它的节点requires_grad都为True。 - variable的
volatile属性默认为False,如果某一个variable的volatile属性被设为True,那么所有依赖它的节点volatile属性都为True。volatile属性为True的节点不会求导,volatile的优先级比requires_grad高。已经被torch.no_grad()替代 - 多次反向传播时,梯度是累加的。反向传播的中间缓存会被清空,为进行多次反向传播需指定
retain_graph=True来保存这些缓存。 - 非叶子节点的梯度计算完之后即被清空,可以使用
autograd.grad或hook技术获取非叶子节点的值。 - variable的grad与data形状一致,应避免直接修改variable.data,因为对data的直接操作无法利用autograd进行反向传播
- 反向传播函数
backward的参数grad_variables可以看成链式求导的中间结果,如果是标量,可以省略,默认为1 - PyTorch采用动态图设计,可以很方便地查看中间层的输出,动态的设计计算图结构。
Variable类和计算图
简单的建立一个计算图,便于理解几个相关知识点:
-
requires_grad 是否要求导数,默认False,叶节点指定True后,依赖节点都被置为True
-
.backward() 根Variable的方法会反向求解叶Variable的梯度
-
.backward()方法grad_variable参数 形状与根Variable一致,非标量Variable反向传播方向指定
-
叶节点 由用户创建的计算图Variable对象,反向传播后会保留梯度grad数值,非叶子节点Variable会清空为None
-
grad_fn 指向创建Tensor的Function,如果某一个对象由用户创建叶子节点,则指向None
-
.is_leaf 是否是叶节点
-
.grad_fn.next_functions 本节点接收的上级节点的grad_fn,
# grad_fn.next_functions代表了本节点的输入节点信息,grad_fn表示了本节点的输出信息 -
.volatile 是否处于推理模式
作用于依赖路径全部的Variable。已经被torch.no_grad(),torch.set_grad_enabled(grad_mode)替代,在0.4版本中。【具体案例见下面volatile部分】
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
|
True False True True True True False False Variable containing: 1 1 1 1 1 1 1 1 1 1 1 1 [torch.FloatTensor of size 3x4] None None None
| 1 |
|
None None <AddBackward1 object at 0x000002A2F3D2EBA8> <SumBackward0 object at 0x000002A2F3D2ECC0>
.grad_fn.next_functions
# grad_fn.next_functions代表了本节点的输入节点信息,grad_fn表示了本节点的输出信息
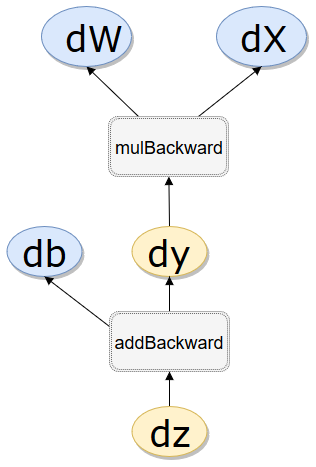
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
|
.is_leaf True True True False False .requires_grad False True True True True .grad_fn None None None <MulBackward1 object at 0x000002A2F57F5710> <AddBackward1 object at 0x000002A2F57F5630> .grad_fn.next_functions ((<AccumulateGrad object at 0x000002A2F57F5630>, 0), (None, 0))第一个参数是w,用户自己创造的叶子节点,梯度累加行AccumulateGrad,第二是x ((<MulBackward1 object at 0x000002A2F57F57B8>, 0), (<AccumulateGrad object at 0x000002A2F57F57F0>, 0))z.grad_fn.next_functions[0][0]==y.grad_fn Truez.grad_fn.next_functions[0][0],y.grad_fn <MulBackward1 object at 0x000002A2F57F57F0> <MulBackward1 object at 0x000002A2F57F57F0>
.volatile
volatile was removed and now has no effect. Use `with torch.no_grad():` instead
| 1 2 3 4 5 6 7 8 9 |
|
False True False True False True
.volatile已经被orch.no_grad(), torch.set_grad_enabled(grad_mode)替代,在0.4版本中。
>>> x = torch.zeros(1, requires_grad=True)
>>> with torch.no_grad():
... y = x * 2
>>> y.requires_grad
False
>>>
>>> is_train = False
>>> with torch.set_grad_enabled(is_train):
... y = x * 2#这样形成的y不求导
>>> y.requires_grad
False
>>> torch.set_grad_enabled(True) # this can also be used as a function
>>> y = x * 2
>>> y.requires_grad
True
>>> torch.set_grad_enabled(False)
>>> y = x * 2
>>> y.requires_grad
False附录、Variable类源码简介
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 |
|