注意
为了大家方便,我没有屏蔽数据库,项目中用的数据源请各位码友不要乱搞~谢谢
缘起
日前项目中需要用到Lucene.且需要中文分词,看了下IK分词器,但是IK分词器貌似只支持到lucene的3.X。后期的版本就不支持了,在网上找了一部分资料,自己写了一个demo.因为中间有不少坑,所以特此记录。
关于Demo
demo采用的lucene的版本是6.4.0。demo基于springmvc+JPA+mybatis+maven。Lucene的高版本和低版本的API不尽相同。而且不同版本基于的IK分词器也不尽相同。使用过程需注意
项目所需JAR包
IKAnalyzer分词器因为不支持高版本的,故借鉴网上的资料写了一个支持高版本Lucene的分词器。下载链接。下载下来之后需要把jar包加入到你本地或者服务器的库文件中,关于怎么把本地jar包加入到maven库中,请移步(外链可能失效,失效请百度怎么把本地jar包加入到maven库中)
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>6.4.0</version>
</dependency>
<dependency>
<groupId>com.seaboat</groupId>
<artifactId>IKAnalyzer</artifactId>
<version>6.4.0</version>
</dependency>
因为只是一个简单的demo.所以并没有加入Lucene的关键字高亮显示包,如果需要高亮显示则还需要加入
<!-- https://mvnrepository.com/artifact/org.apache.lucene/lucene-highlighter -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-highlighter</artifactId>
<version>6.4.0</version>
</dependency>
示例代码
篇幅所限,本处只列出关键代码
user(对应数据库表)
public class User implements Serializable {
@Id
@Column(name = "id")
private Integer id;
@Column(name = "userName")
private String userName;
@Column(name = "password")
private String password;
@Column(name = "name")
private String name;
}
DataModel(lucene关键,采集的数据模型类)
public class DataModel {
private String id;
private String name;
}
DataManageService(数据采集类,关键代码)
package com.bxoon.service;
import com.bxoon.dao.UserDao;
import com.bxoon.domain.DataModel;
import com.bxoon.domain.User;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.*;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.*;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.wltea.analyzer.lucene.IKAnalyzer;
import java.io.File;
import java.nio.file.Path;
import java.util.ArrayList;
import java.util.List;
/**
* 数据管理Service
*/
@Service
public class DataManageService {
@Autowired
UserDao userDao;
/**
* 数据采集
*/
private List<DataModel> getData(){
List<User> list = userDao.findAll();
List<DataModel> dataModelList = new ArrayList<>(list.size());
for (User user:list){
DataModel dataModel = new DataModel();
dataModel.setId(user.getId()+"");
dataModel.setName(user.getName());
dataModelList.add(dataModel);
}
return dataModelList;
}
/**
* 创建索引
*/
public void createIndex(){
try {
List<DataModel> dataModelList = getData();
List<Document> documentList = new ArrayList<>();
dataModelList.forEach(e -> {
Document document = new Document();
Field idField = new TextField("id", e.getId(), Field.Store.YES);
Field nameFiled = new TextField("name", e.getName(), Field.Store.YES);
document.add(idField);
document.add(nameFiled);
documentList.add(document);
});
IKAnalyzer ikAnalyzer = new IKAnalyzer();
IndexWriterConfig indexWriterConfig = new IndexWriterConfig(ikAnalyzer);
File indexFile = new File("E:\\LuceneRepo\\");
Path path = indexFile.toPath();
Directory directory = FSDirectory.open(path);
IndexWriter writer = new IndexWriter(directory, indexWriterConfig);
writer.addDocuments(documentList);
writer.commit();
writer.close();
}catch (Exception ex){
ex.printStackTrace();
}
}
public void indexSearch(){
try {
// 创建query对象
// 使用QueryParser搜索时,需要指定分词器,搜索时的分词器要和索引时的分词器一致
// 第一个参数:默认搜索的域的名称
// QueryParser parser = new QueryParser("name", new IKAnalyzer());
// parser.setAllowLeadingWildcard(true);
// Query query = parser.parse("name:张");
Term aTerm = new Term("name", "张三");
Query query = new TermQuery(aTerm);
// 创建IndexSearcher
// 指定索引库的地址
File indexFile = new File("E:\\LuceneRepo");
Path path = indexFile.toPath();
Directory directory = FSDirectory.open(path);
DirectoryReader ireader = DirectoryReader.open(directory);
IndexSearcher searcher = new IndexSearcher(ireader);
// 通过searcher来搜索索引库
// 第二个参数:指定需要显示的顶部记录的N条
TopDocs topDocs = searcher.search(query, 100);
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
for (ScoreDoc scoreDoc:scoreDocs){
int scoreDocId = scoreDoc.doc;
Document document = searcher.doc(scoreDocId);
System.out.println("id:"+document.get("id"));
System.out.println("name:"+document.get("name"));
}
directory.close();
ireader.close();
}catch (Exception ex){
ex.printStackTrace();
}
}
}
copy IK分词器的配置文件进项目的resources目录
IK分词器需要两个配置文件。IKAnalyzer.cfg.xml,stopword.dic。我看网上的部分教程没有,不知道为什么反正我是需要,不然会不成功。本想给出链接直接下载,考虑到还要上传百度网盘什么的太麻烦了,所以直接给出内容。需要的朋友直接copy到文件里面然后改成对应的名字,然后copy到项目的resource目录下就可以了。
IKAnalyzer.cfg.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典
<entry key="ext_dict">ext.dic;</entry>
-->
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">stopword.dic;</entry>
</properties>
stopword.dic
a
an
and
are
as
at
be
but
by
for
if
in
into
is
it
no
not
of
on
or
such
that
the
their
then
there
these
they
this
to
was
will
with
查看索引库内容
分词完成了之后会在代码里面配置的路径下生产几个文件,就是分词之后形成的索引库文件,类似于
可以通过Lucene库文件查看工具Luke查看库的内容。LUKE的版本也需要跟Lucene的版本差不多,否则无法查看。下面给出下载链接
链接:https://pan.baidu.com/s/1TqIN25lA90eUUnvu2ghDyA
提取码:22lw
下载下来如果你是window系统那直接运行luke.bat文件,打开界面后选择你的lucene的索引库文件的路径就可以查看了。
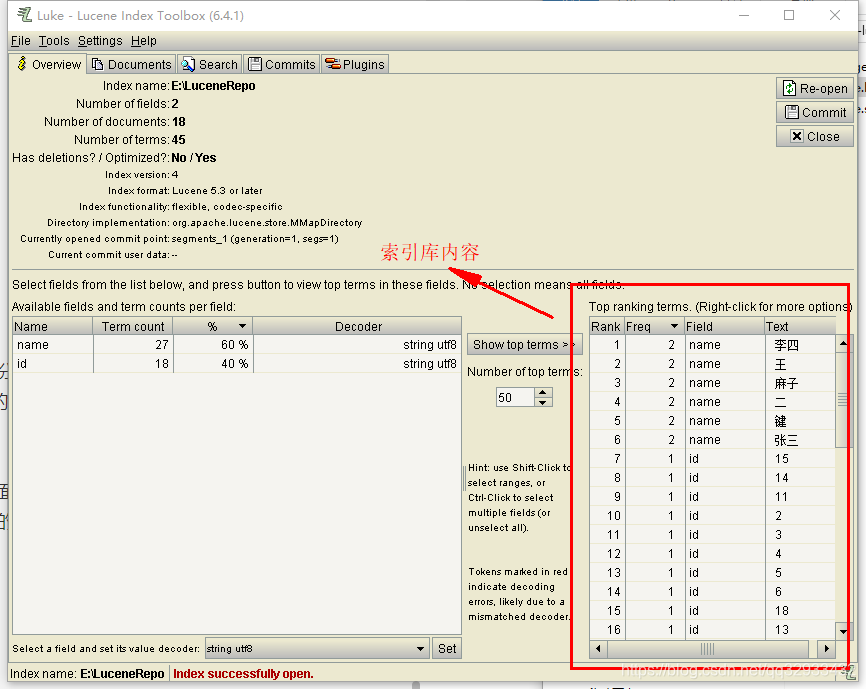
如果库里面看不到内容,那可能是版本不对,也可能是你的分词没有成功。
写在最后
东西写的比较简单,中间也是有很多坑。建议看我git上的一个LuceneDemo.
中间有几个坑是需要注意的,比如copy IK分词器的配置文件那一步,网上的部分教程没有。
另外,GIT上的部分码友写的IK分词器在使用maven命令mvn install打包过程中会遗失main2012.dic这个文件,导致项目中使用会有问题。需要在打好了包之后手动copy进去。
参考
https://blog.csdn.net/wangyangzhizhou/article/details/71487030