首先声明:此小视频非彼小视频,大家心照不宣即可
目标:https://www.vmovier.com/ 这网站名字好像叫场库
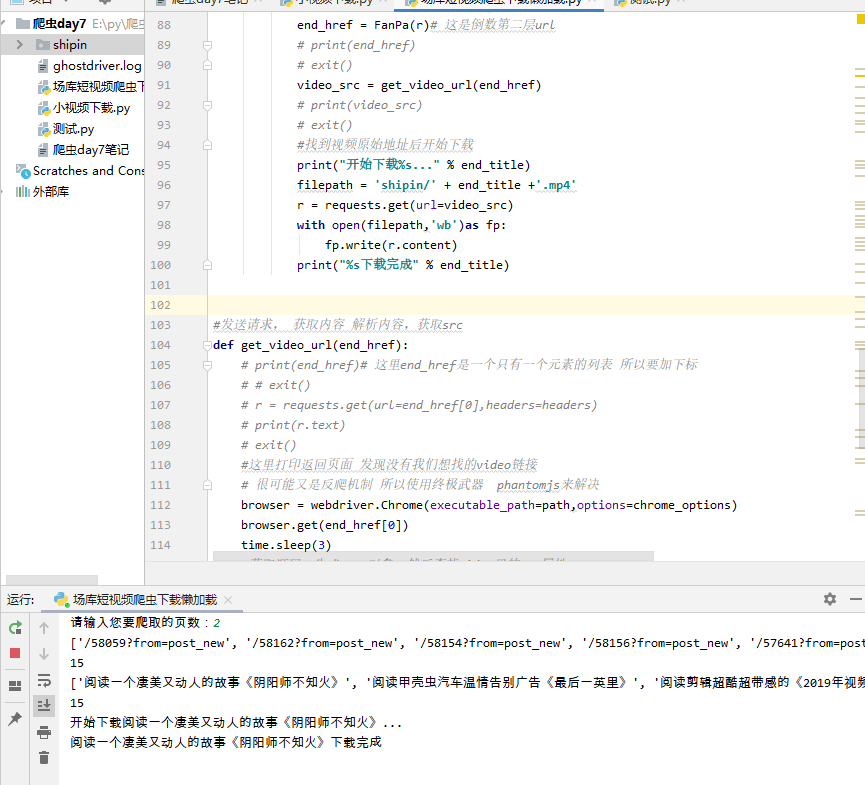
""" 首先向https://www.vmovier.com/发送请求 获取响应,解析响应 将所有标题和链接过滤出来 向过滤出的链接发请求下载视频 向src属性发送请求,获取响应,将内容保存到本地 注意:这是一个动态的页面 是js的数据 需要捕获接口 使用抓包工具Fiddler 接口信息:https://www.vmovier.com/post/getbytab?tab=new&page=1&pagepart=2&type=0&controller=index&last_postid=58197 """ import requests from bs4 import BeautifulSoup import time import json from lxml import etree import re from selenium import webdriver from selenium.webdriver.chrome.options import Options #创建一个参数对象,用来控制Chrome以无界面模式打开 chrome_options = Options() #开启无头模式 chrome_options.add_argument('--headless') #禁用GPU chrome_options.add_argument('--disable-gpu') #驱动路径 path =r'D:\chromedriver\chromedriver.exe' #添加头部 作为全局 headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36' } #此处有一个跳转 感觉像是反爬机制 所以我们要再过滤一次 过滤出跳转后的url这个函数用来处理此跳转 def FanPa(r): #正则获取src属性 match_obj = re.compile(r'<meta property="article:published_first" content="新片场,(.*)" />') url = re.findall(match_obj,r.text) # print(url) # exit() return url #解析首页,返回所有的标题链接 def handle_title(): #输入你想要的爬取的页数 page = int(input("请输入您要爬取的页数:")) print("开始爬取第%s页....." % page) #将捕获接口拿过来 因为是动态的页面 所以捕获接口 向接口发送数据 #page=页数 pagepart=每页的第几次刷新 每页有三次刷新分别是1 2 3 可以写一个循环 for T in range (1,4): url = "https://www.vmovier.com/post/getbytab?tab=new&page=% s&pagepart=%d" %(page,T) # print(url) # exit() r = requests.get(url=url,headers=headers) #解析内容,因为返回的是json数据 直接解析json格式即可 # 后来发现不是严格json格式 就使用json对象取出了data部分 用正则过滤出来的 #我们需要的标题和链接分别是h1标签下的title和href #将json数据转化为Python对象 obj = json.loads(r.text) # print(obj) # exit() #取出所有和视频相关的数据 标题和url 使用正则 data = obj['data'] #print(data) # # exit() match_obj_url = re.compile(r'<a href="(.*)" title=".*全文" target="_blank">阅读全文...</a>') url = re.findall(match_obj_url,data) # print(url) # print(len(url)) match_obj_title = re.compile(r'<a href=".*" title="(.*)全文" target="_blank">阅读全文...</a>') title = re.findall(match_obj_title,data) # print(title) # print(len(title)) # exit() #循环data列表 依次取出每一个视频信息 # 其中标题信息可以直接用 但是url拼接后不是最终url 还有2次跳转 for i in range (0,15):#两个列表各有15条数据 一一对应 end_title = title[i] #print(end_title) a_href = "https://www.vmovier.com" + url[i] # print(a_href) # exit() #这个不是最终视频url 需要处理一次跳转 r = requests.get(url=a_href,headers=headers) end_href = FanPa(r)# 这是倒数第二层url # print(end_href) # exit() video_src = get_video_url(end_href) # print(video_src) # exit() #找到视频原始地址后开始下载 print("开始下载%s..." % end_title) filepath = 'shipin/' + end_title +'.mp4' r = requests.get(url=video_src) with open(filepath,'wb')as fp: fp.write(r.content) print("%s下载完成" % end_title) #发送请求, 获取内容 解析内容,获取src def get_video_url(end_href): # print(end_href)# 这里end_href是一个只有一个元素的列表 所以要加下标 # # exit() # r = requests.get(url=end_href[0],headers=headers) # print(r.text) # exit() #这里打印返回页面 发现没有我们想找的video链接 # 很可能又是反爬机制 所以使用终极武器 无头浏览器来解决 browser = webdriver.Chrome(executable_path=path,options=chrome_options) browser.get(end_href[0]) time.sleep(3) #获取源码,生成tree对象,然后查找video里的src属性 # print(browser.page_source) # exit() soup = BeautifulSoup(browser.page_source,'lxml') video_src =soup.find('video',id="xpc_video")['src'] # print(video_src) # exit() return video_src def main(): #解析首页,返回所有的标题链接 handle_title() if __name__ == '__main__': main()
主要需要注意的问题是:
1、对于这种懒加载的网页 一般要捕获其接口,从接口返回信息中过滤出标题和url
2、这个网站有一个跳转过程,感觉像是反爬的机制,可以通过一步步输出HTML页面去判断是否是我们需要的页面
3、有一些地方 比如json返回的数据 不是严格的json格式 我们就把数据取出来 使用正则表达式去过滤
4、有的时候requests模块发送请求不能获得我们想要的页面 可能需要使用无界面浏览器驱动去获取页面内容
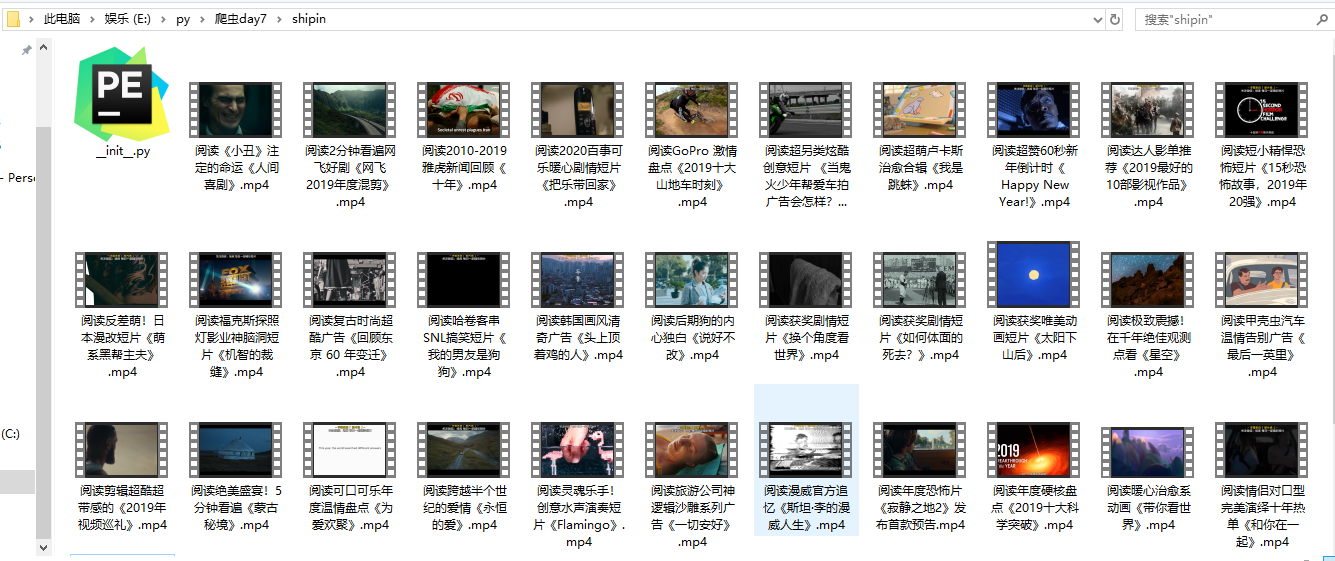
结果: