这次爬取的网站结构较为简单,适用于初学爬虫!
这次学习需要先把python和pip的环境配好,还需要引入一些包**(re,lxml,os,requests)**
直接在cmd中进行 pip install 包名就可以成功安装啦。
一、观察和分析网站
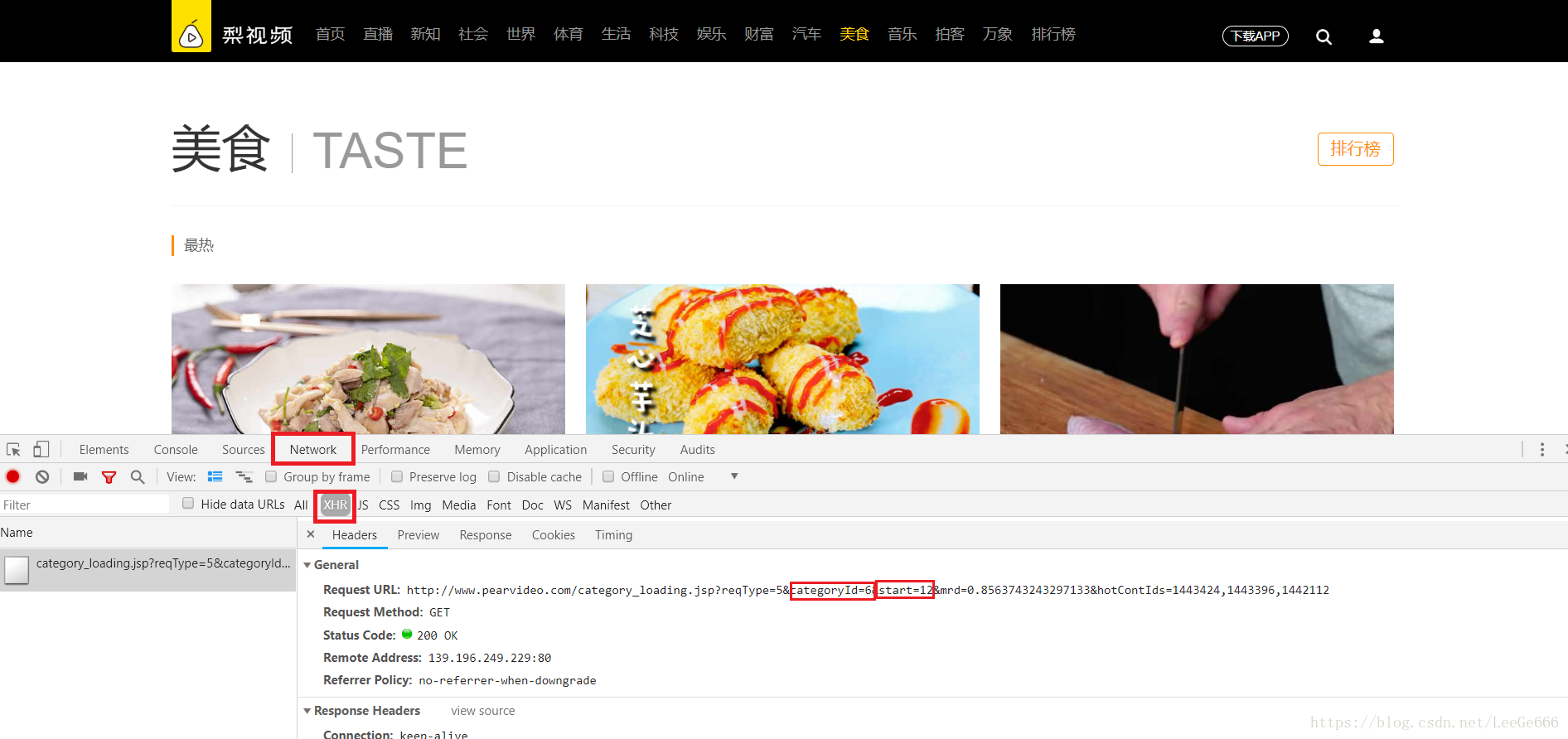
第一步、打开网站,转到美食的页面,之后按下f12,再选择network,选择XHR,这是ajax加载出来与页面相关的,按下f5刷新一些,可以看到这个Request URL,这个网址在浏览器中打开就是该页面的网址,ategoryId=6这个6代表的就是美食这一栏,也就是我们要爬取的页面,start=12代表是最开始的在页面上显示的12个视频。
网站地址:梨视频美食
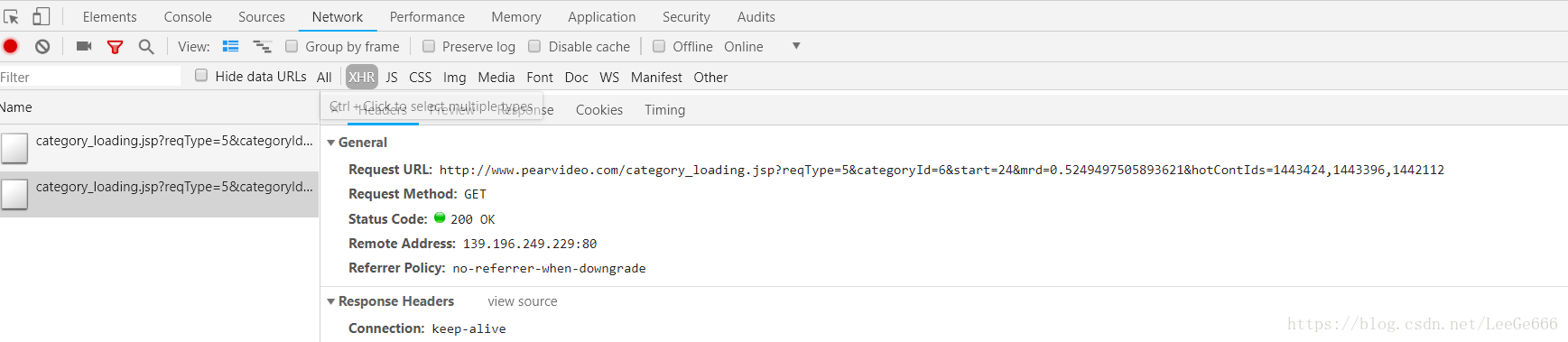
如果滚轮往下移,点击加载页面,就会发现多一个链接,他的Request URL中的start=24,也就是加载了24个视频
第二步、我们再在刚才的页面上右键检查页面源代码
找到第一个视频的代码位置,找到vedio-数字,再点开第该视频的播放页面,发现这个vedio-数字正好是对应的就是http://www.pearvideo.com/video_数字

二、获取视频信息
最开始先引入一些需要使用的包
import requests
from lxml import etree
import re
from urllib.request import urlretrieve
import os
第一步、首先写一个获取页面源代码的函数
def get_html(url):
response = requests.get(url)
if response.status_code == 200:#确认状态码为200
return response.text #如果成立就返回页面源代码,有误就是返回空
else:
return None
def main():
url = 'http://www.pearvideo.com/category_loading.jsp?reqType=5&categoryId=6&start=12
html = get_html(url)
print(html)
if __name__ == '__main__':
main()
第二步、解析主页面
用的是etree模块,用它来分析页面源代码,之后找到刚刚的vedio-数字,利用xpath把视频的id找出来,之后再把视频播放的地址给连接起来
其中的append是把刚刚拼接好的播放地址,存到一个list列表中,方便下面对每个地址进行遍历。
def get_vedio(url):
html = get_html(url) #调用上面的获取源代码的函数
html = etree.HTML(html) #解析页面
video_id = html.xpath('//div[@class="vervideo-bd"]/a/@href') #用过该标签的xpath找到视频id
video_url = [] #声明一个list
starturl = 'http://www.pearvideo.com/ #主视频地址
for id in video_id:
newurl = starturl + id # 拼接每一个视频播放的地址
video_url.append(newurl) #获取视频播放地址
print(newurl)
第三步、得到视频真正播放地址
打开页面源代码,找到如下链接,通过一个循环,将这个页面上的源代码获取出来,之后用正则匹配把视频真正的播放地址匹配出来。

for play_url in video_url:
html = get_html(play_url)
real_url = re.compile('srcUrl="(.*?)"') #增加效率
real_url = re.findall(real_url,html)
#获取视频名称
video_name = re.compile('<h1 class="video-tt">(.*?)</h1>')
video_name = re.findall(video_name,html)
print(video_name,real_url)
三、下载视频
通过urlretrieve方法下载视频
def download_vedio(real_url,video):
#自己设置一个路径
path = 'D:\\python Projects\\pyDownloadPictrues\\18-7-18梨视频\\{}.mp4'.format(video)
if not os.path.exists(path): #判断有没有这个路径,这个可以自己设置的,不一定要和我一样,设置为'D:\\vedios\\{}.mp4'.format(video)'也是可以的
print("正在下载:{}".format(video))
urlretrieve(real_url, path) # 下载url,下载文件夹
print('ok!!!!!')
else:
print('no!!!!!')
主函数设置一下循环:
def main():
sum = 0 #视频的总数量
while True: #一个while循环
if sum > 48: #如果获取到48个视频的时候就返回空,就是退出程序
return
url = 'http://www.pearvideo.com/category_loading.jsp?reqType=5&categoryId=6&start={}'.format(sum)
#最开始分析网站的的网址,format(sum),代表的就是视频的页面显示的总数
sum += 12 #分析的时候每次往下加载的时候增加12个视频
get_vedio(url) #调用上面获取视频的函数
if __name__ == '__main__': #判断是否为当前文件
main() #执行main函数
到这里我们爬取就结束了,其实还有很多操作都没有进行的,现在只是成功的把视频下载下来,后续还可以将视频的发布时间,点赞评论数给获取下来,存储到数据库,需要同学们自己慢慢挖掘了。