本博客为《利用Python进行数据分析》的读书笔记,请勿转载用于其他商业用途。
文章目录
1. 分层索引
分层索引是pandas的重要特性,允许你再一个轴向上拥有多个(两个或两个以上)索引层级。笼统地说,分层索引提供了一种更低维度的形式中处理更高维度数据的方式。例:
data = pd.Series(np.random.randn(9),
index=[['a', 'a', 'a', 'b', 'b', 'c', 'c', 'd', 'd'],
[1, 2, 3, 1, 3, 1, 2, 2, 3]])
data
#
a 1 0.084340
2 1.252705
3 -1.305060
b 1 0.629035
3 -1.099427
c 1 -0.785977
2 -0.524298
d 2 0.144326
3 0.945895
dtype: float64
我们看到的是一个以MultiIndex作为索引的Series的美化视图。索引中的“间隙”表示“直接使用上面的标签”:
data.index
#
MultiIndex(levels=[['a', 'b', 'c', 'd'], [1, 2, 3]],
codes=[[0, 0, 0, 1, 1, 2, 2, 3, 3], [0, 1, 2, 0, 2, 0, 1, 1, 2]])
通过分层索引对象,也可以成为部分索引,允许你简洁地选择出数据的子集:
data['b']
#
1 0.629035
3 -1.099427
dtype: float64
data['b': 'c']
#
b 1 0.629035
3 -1.099427
c 1 -0.785977
2 -0.524298
dtype: float64
data.loc[['b', 'd']]
#
b 1 0.629035
3 -1.099427
d 2 0.144326
3 0.945895
dtype: float64
在“内部”层级中进行选择也是可以的:
data.loc[:, 2]
#
a 1.252705
c -0.524298
d 0.144326
dtype: float64
分层索引在重塑数据和数组透视表等分组操作中扮演了重要角色。例如,你可以使用unstack方法将数据在DataFrame中重新排列:
data.unstack()
#
1 2 3
a 0.084340 1.252705 -1.305060
b 0.629035 NaN -1.099427
c -0.785977 -0.524298 NaN
d NaN 0.144326 0.945895
unstack的反操作是stack:
data.unstack().stack()
#
a 1 0.084340
2 1.252705
3 -1.305060
b 1 0.629035
3 -1.099427
c 1 -0.785977
2 -0.524298
d 2 0.144326
3 0.945895
dtype: float64
在DataFrame中,每个轴都可以拥有分层索引:
frame = pd.DataFrame(np.arange(12).reshape((4, 3)),
index=[['a', 'a', 'b', 'b'], [1, 2, 1, 2]],
columns=[['Ohio', 'Ohio', 'Colorado'],
['Green', 'Red', 'Green']])
frame
#
Ohio Colorado
Green Red Green
a 1 0 1 2
2 3 4 5
b 1 6 7 8
2 9 10 11
分层的层级可以有名称(可以是字符串或Python对象)。如果层级有名称,这些名称会在控制台输出中显示:
frame.index.names = ['key1', 'key2']
frame.columns.names = ['state', 'color']
frame
#
state Ohio Colorado
color Green Red Green
key1 key2
a 1 0 1 2
2 3 4 5
b 1 6 7 8
2 9 10 11
注意区分行标签中的索引名称’state’和’color’。
通过部分列索引,你可以选出列中的组:
frame['Ohio']
#
color Green Red
key1 key2
a 1 0 1
2 3 4
b 1 6 7
2 9 10
1.1 重排序和层级排序
有时,我们需要重新排列轴上的层级顺序,或者按照特定层级的值对数据进行排序。swaplevel接收两个层级序号或层级名称,返回一个进行了层级变更的新对象(但是数据是不变的):
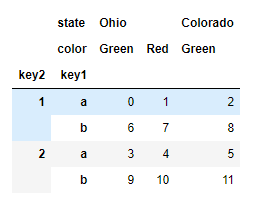
frame.swaplevel('key1', 'key2')
#
state Ohio Colorado
color Green Red Green
key1 key2
a 1 0 1 2
2 3 4 5
b 1 6 7 8
2 9 10 11
另一方面,sort_index只能在单一层级上对数据进行排序。在进行层级变换时,使用sort_index以是的结果按照层级进行字典排序也很常见:
frame.sort_index(level=1)
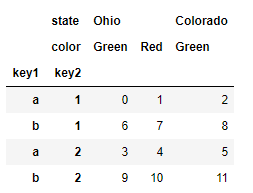
frame.swaplevel(0, 1).sort_index(level=0)
如果索引按照字典顺序从最外层开始排序,那么数据选择性能会更好——调用sort_index(level=0)或sort_index可以得到这样的结果。
1.2 按层级进行汇总统计
通常我们不会使用DataFrame中的一个或多个列作为行索引;反而你可能想要将行索引移动到DataFrame的列中。下面是一个示例:
frame = pd.DataFrame({'a': range(7), 'b': range(7, 0, -1),
'c': ['one', 'one', 'one', 'two', 'two',
'two', 'two'],
'd': [0, 1, 2, 0, 1, 2, 3]})
frame
#
a b c d
0 0 7 one 0
1 1 6 one 1
2 2 5 one 2
3 3 4 two 0
4 4 3 two 1
5 5 2 two 2
6 6 1 two 3
DataFrame的set_index函数会生成一个新的DataFrame,新的DataFrame使用一个或多个列作为索引:
frame2 = frame.set_index(['c', 'd'])
frame2
#
a b
c d
one 0 0 7
1 1 6
2 2 5
two 0 3 4
1 4 3
2 5 2
3 6 1
默认情况下这些列会从DataFrame中移除,你也可以将它们留在DataFrame中:
frame.set_index(['c', 'd'], drop=False)
#

另一方面,reset_index是set_index的反操作,分层索引的索引层级会被移动到列中:

2. 联合与合并数据集
包含在pandas对象的数据可以通过多种方式联合在一起:
pandas.merge根据一个或多个键将行进行连接。对于SQL或其他关系数据库的用户来说,这种方式比较熟悉,它实现的是数据库的连接操作。pandas.concat使对象在轴向上进行黏合或“堆叠”。combine_first实例方法允许将重叠的数据拼接在一起,以使用一个对象中的值填充一个对象中的缺失值。
2.1 数据库风格的DataFrame连接
合并 或 连接 操作通过一个或多个键连接行来联合数据集。这些操作时关系型数据库的核心内容(例如基于SQL的数据库)。pandas中的merge函数主要用于将各种join操作算法运用在数据上:
df1 = pd.DataFrame({'key': ['b', 'b', 'a', 'c', 'a', 'a', 'b'],
'data1': range(7)})
df2 = pd.DataFrame({'key': ['a', 'b', 'd'],
'data2': range(3)})
df1
#
key data1
0 b 0
1 b 1
2 a 2
3 c 3
4 a 4
5 a 5
6 b 6
df2
#
key data2
0 a 0
1 b 1
2 d 2
这是一个 多对一 的例子;df1的数据有多个行的标签为a和b,而df2在key列中每个值仅有一行。调用merge处理我们获得的对象:
pd.merge(df1, df2)
#
key data1 data2
0 b 0 1
1 b 1 1
2 b 6 1
3 a 2 0
4 a 4 0
5 a 5 0
请注意,我们并没有指定在哪一列上进行连接。如果连接的键信息没有指定,merge会自动将重叠列名作为连接的键。但是,显式地指定连接键才是好的实现:
pd.merge(df1, df2, on='key')
结果与之前相同。
如果每个对象的列名是不同的,可以分别为它们指定列名:
df3 = pd.DataFrame({'lkey': ['b', 'b', 'a', 'c', 'a', 'a', 'b'],
'data1': range(7)})
df4 = pd.DataFrame({'rkey': ['a', 'b', 'd'],
'data2': range(3)})
pd.merge(df3, df4, left_on='lkey', right_on='rkey')
#
lkey data1 rkey data2
0 b 0 b 1
1 b 1 b 1
2 b 6 b 1
3 a 2 a 0
4 a 4 a 0
5 a 5 a 0
我们可以发现结果中缺少‘c’和‘d’的值以及相关的数据。默认情况下merge做的是内连接,结果中的键是两张表的交集。其他可选的选项有‘left’、‘right’和‘outer’。外连接是键的交集,联合了左连接和右连接的效果:
pd.merge(df1, df2, how='outer')
#
key data1 data2
0 b 0.0 1.0
1 b 1.0 1.0
2 b 6.0 1.0
3 a 2.0 0.0
4 a 4.0 0.0
5 a 5.0 0.0
6 c 3.0 NaN
7 d NaN 2.0
表: how参数的不同连接类型
| 选项 | 行为 |
|---|---|
inner |
只对两张表都有的键的交集进行联合 |
left |
对所有左表的键进行联合 |
right |
对所有右表的键进行联合 |
outer |
对两张表都有的键的并集进行联合 |
尽管不是很直观,但 多对多 的合并有明确的行为。下面是一个例子:
df1 = pd.DataFrame({'key': ['b', 'b', 'a', 'c', 'a', 'a', 'b'],
'data1': range(7)})
df2 = pd.DataFrame({'key': ['a', 'b', 'd'],
'data2': range(3)})
df1
#
key data1
0 b 0
1 b 1
2 a 2
3 c 3
4 a 4
5 a 5
6 b 6
df2
#
key data2
0 a 0
1 b 1
2 d 2
pd.merge(df1, df2)
#
key data1 data2
0 b 0 1
1 b 1 1
2 b 6 1
3 a 2 0
4 a 4 0
5 a 5 0
多对多连接是行的笛卡尔积。由于在左边的DataFrame中有三个’b’行,而在右边有两行,因此在结果中有6个’b’行。连接方法仅影响结果中显示的不同键值:
pd.merge(df1, df2, on='key')
#
key data1 data2
0 b 0 1
1 b 1 1
2 b 6 1
3 a 2 0
4 a 4 0
5 a 5 0
使用多个键进行合并时,传入一个列名的列表:
left = pd.DataFrame({'key1': ['foo', 'foo', 'bar'],
'key2': ['one', 'two', 'one'],
'lval':[1, 2, 3]})
right = pd.DataFrame({'key1': ['foo', 'foo', 'bar', 'bar'],
'key2': ['one', 'one', 'one', 'two'],
'rval':[4, 5, 6, 7]})
pd.merge(left, right, on=['key1', 'key2'], how='outer')
结果如下:
key1 key2 lval rval
0 foo one 1.0 4.0
1 foo one 1.0 5.0
2 foo two 2.0 NaN
3 bar one 3.0 6.0
4 bar two NaN 7.0
决定哪些键联合出现在结果中,取决于合并方法的选择,把多个键看作一个元组数据来作为单个连接键使用(尽管实际上并不是以这种方法来实现的)。
警告:当你再进行列—列连接时,传递的DataFrame索引对象会被丢弃。
合并操作中最后一个要考虑的问题是如何处理重叠的列名。虽然你可以手动解决重叠问题,但是merge有一个suffixes后缀选项,用于在左右两边DataFrame对象的重叠列名后指定需要添加的字符串:
pd.merge(left, right, on='key1')
#
key1 key2_x lval key2_y rval
0 foo one 1 one 4
1 foo one 1 one 5
2 foo two 2 one 4
3 foo two 2 one 5
4 bar one 3 one 6
5 bar one 3 two 7
pd.merge(left, right, on='key1', suffixes=('_left', '_right'))
#
key1 key2_left lval key2_right rval
0 foo one 1 one 4
1 foo one 1 one 5
2 foo two 2 one 4
3 foo two 2 one 5
4 bar one 3 one 6
5 bar one 3 two 7
表:merge函数参数
| 参数 | 描述 |
|---|---|
| left | 合并时操作中左边的DataFrame |
| right | 合并时操作中右边的DataFrame |
| how | inner、outer、left、right之一;默认是inner |
| on | 需要连接的列名。必须是在两边的DataFrame对象都有的列名,并以left和right中的列名的交集作为连接键 |
| left_on | left DataFrame中用作连接键的列 |
| right_on | right DataFrame中用作连接键的列 |
| left_index | 使用left行索引作为它的连接键(如果是MultiIndex,则是多个键) |
| right_index | 使用right行索引作为它的连接键(如果是MultiIndex,则是多个键) |
| sort | 通过连接键字母顺序合并的数据进行排序;在默认情况下为True(在大数据集上某些情况下禁用该功能可以获得更好的性能) |
| suffixes | 在重叠情况下,添加到列名后的字符串元组;默认是(’_x’,’_y’)(例如如果待合并的DataFrame中都含有’data’列,那么结果中会出现’data_x’、‘data_y’) |
| copy | 如果为False,则在某些特殊情况下避免将数据复制到结果数据结构中;默认情况下总是复制 |
| indicator | 添加一个特殊的列_merge,只是每一行的来源;值将根据每行中连接数据的来源分别为left_only、right_only或both |
2.2 根据索引合并
在某些情况下,DataFrame中用于合并的键是它的索引。在这种情况下,你可以传递left_index=True或right_index=True(或者都传)来表示索引需要用来作为合并的键:
left1 = pd.DataFrame({'key': ['a', 'b', 'a', 'a', 'b', 'c'],
'value': range(6)})
right1 = pd.DataFrame({'group_val': [3.5, 7]}, index=['a', 'b'])
left1
#
key value
0 a 0
1 b 1
2 a 2
3 a 3
4 b 4
5 c 5
right1
#
group_val
a 3.5
b 7.0
pd.merge(left1, right1, left_on='key', right_index=True)
#
key value group_val
0 a 0 3.5
2 a 2 3.5
3 a 3 3.5
1 b 1 7.0
4 b 4 7.0
由于默认的合并方法是连接键相交,可以使用外连接来进行合并:
pd.merge(left1, right1, left_on='key', right_index=True, how='outer')
#
key value group_val
0 a 0 3.5
2 a 2 3.5
3 a 3 3.5
1 b 1 7.0
4 b 4 7.0
5 c 5 NaN
在多层索引数据的情况下,事情会更复杂,在索引上连接是一个隐式的多键合并:
lefth = pd.DataFrame({'key1': ['Ohio', 'Ohio', 'Ohio', 'Nevada', 'Nevada'],
'key2': [2000, 2001, 2002, 2001, 2002],
'data': np.arange(5.)})
righth = pd.DataFrame(np.arange(12).reshape((6, 2)),
index=[['Nevada', 'Nevada', 'Ohio','Ohio','Ohio','Ohio'],
[2001, 2000, 2000, 2000, 2001, 2002]],
columns=['event1', 'event2'])
lefth
#
key1 key2 data
0 Ohio 2000 0.0
1 Ohio 2001 1.0
2 Ohio 2002 2.0
3 Nevada 2001 3.0
4 Nevada 2002 4.0
righth
#
event1 event2
Nevada 2001 0 1
2000 2 3
Ohio 2000 4 5
2000 6 7
2001 8 9
2002 10 11
这种情况下,你必须以列表的方式指明合并所需多个列(请注意使用how='outer'处理重复的索引值):
pd.merge(lefth, righth, left_on=['key1', 'key2'],right_index=True)
#
key1 key2 data event1 event2
0 Ohio 2000 0.0 4 5
0 Ohio 2000 0.0 6 7
1 Ohio 2001 1.0 8 9
2 Ohio 2002 2.0 10 11
3 Nevada 2001 3.0 0 1
pd.merge(lefth, righth, left_on=['key1', 'key2'],right_index=True, how='outer')
#
key1 key2 data event1 event2
0 Ohio 2000 0.0 4.0 5.0
0 Ohio 2000 0.0 6.0 7.0
1 Ohio 2001 1.0 8.0 9.0
2 Ohio 2002 2.0 10.0 11.0
3 Nevada 2001 3.0 0.0 1.0
4 Nevada 2002 4.0 NaN NaN
4 Nevada 2000 NaN 2.0 3.0
使用两边的索引进行合并也是可以的:
left2 = pd.DataFrame([[1., 2.], [3., 4.], [5., 6.]],
index=['a', 'c', 'e'],
columns=['Ohio', 'Nevada'])
right2 = pd.DataFrame([[7., 8.], [9., 10.], [11., 12.], [13, 14]],
index=['b', 'c', 'd', 'e'],
columns=['Missouri', 'Alabama'])
left2
#
Ohio Nevada
a 1.0 2.0
c 3.0 4.0
e 5.0 6.0
right2
#
Missouri Alabama
b 7.0 8.0
c 9.0 10.0
d 11.0 12.0
e 13.0 14.0
pd.merge(left2, right2, how='outer', left_index=True, right_index=True)
#
Ohio Nevada Missouri Alabama
a 1.0 2.0 NaN NaN
b NaN NaN 7.0 8.0
c 3.0 4.0 9.0 10.0
d NaN NaN 11.0 12.0
e 5.0 6.0 13.0 14.0
DataFrame有一个方便的join实例方法,用于按照索引合并。该方法也可以用于合并多个索引相同或相似但没有重叠列的DataFrame对象:
left2.join(right2, how='outer')
#
Ohio Nevada Missouri Alabama
a 1.0 2.0 NaN NaN
b NaN NaN 7.0 8.0
c 3.0 4.0 9.0 10.0
d NaN NaN 11.0 12.0
e 5.0 6.0 13.0 14.0
最后,对于一些简单索引—索引合并,你可以向join方法传入一个DataFrame列表,这个方法可以替代使用更为通用的concat方法:
another = pd.DataFrame([[7., 8.], [9., 10.], [11., 12.], [16, 17]],
index=['a', 'c', 'e', 'f'],
columns=['New York', 'Oregon'])
another
#
New York Oregon
a 7.0 8.0
c 9.0 10.0
e 11.0 12.0
f 16.0 17.0
left2.join([right2, another])
#
Ohio Nevada Missouri Alabama New York Oregon
a 1.0 2.0 NaN NaN 7.0 8.0
c 3.0 4.0 9.0 10.0 9.0 10.0
e 5.0 6.0 13.0 14.0 11.0 12.0
left2.join([right2, another], sort=True, how='outer')
#
Ohio Nevada Missouri Alabama New York Oregon
a 1.0 2.0 NaN NaN 7.0 8.0
b NaN NaN 7.0 8.0 NaN NaN
c 3.0 4.0 9.0 10.0 9.0 10.0
d NaN NaN 11.0 12.0 NaN NaN
e 5.0 6.0 13.0 14.0 11.0 12.0
f NaN NaN NaN NaN 16.0 17.0
由于输出结果列表调整对齐实在是太复杂了,下一节开始,对于数据内容较多的表格,我们就用图片的模式来展示代码执行的结果。
2.3 沿轴向连接
另一种数据组合操作可互换地称为拼接、绑定或堆叠。Numpy的concatenate函数可以在Numpy数组上实现该功能:
arr = np.arange(12).reshape((3, 4))
arr
#
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
np.concatenate([arr, arr], axis=1)
#
array([[ 0, 1, 2, 3, 0, 1, 2, 3],
[ 4, 5, 6, 7, 4, 5, 6, 7],
[ 8, 9, 10, 11, 8, 9, 10, 11]])
在Series和DataFrame等pandas对象的上下文中,使用标记的轴可以进一步泛化数组连接。尤其是你还有许多需要考虑的事情:
- 如果对象在其他轴上的索引不同,我们是否应该将不同的元素组合在这些轴上,还是只使用共享的值(交集)?
- 连接的数据块是否需要在结果对象中被识别?
- “连接轴”是否包含需要保存的数据?在许多情况下,DataFrame中的默认整数标签在连接期间最好丢弃。
pandas的concat函数提供了一种一致性的方式来解决以上问题。我们将给出一些例子来表明它的工作机制。假设我们有三个索引不存在重叠的Series:
s1 = pd.Series([0, 1], index=['a', 'b'])
s2 = pd.Series([2, 3, 4], index=['c', 'd', 'e'])
s3 = pd.Series([5, 6], index=['f', 'g'])
用列表中的这些对象调用concat方法会将值和索引粘在一起:
pd.concat([s1, s2, s3])
#
a 0
b 1
c 2
d 3
e 4
f 5
g 6
dtype: int64
默认情况下,concat方法是沿着axis=0的轴向生效的,生成另一个Series。如果你传递axis=1,返回的结果则是一个DataFrame(axis=1时是列):
在运行的时候,Anaconda提示我们需要加上sort=True。

在这个案例中另一个轴向上并没有重叠,你可以看到排序后的索引合集('outer'join外连接)。你也可以传入join='inner':
s4 = pd.concat([s1, s3])
s4
#
a 0
b 1
f 5
g 6
dtype: int64
pd.concat([s1, s4], axis=1, sort=True)
#
0 1
a 0.0 0
b 1.0 1
f NaN 5
g NaN 6
pd.concat([s1, s4], axis=1, join='inner', sort=True)
#
0 1
a 0 0
b 1 1
在这个例子中,由于join='inner'的选项,'f’和’g’的标签消失了。
你甚至可以使用join_axes来指定用于连接其他轴向的轴:
pd.concat([s1, s4], axis=1, join_axes=[['a', 'c', 'b', 'e']])
#
0 1
a 0.0 0.0
c NaN NaN
b 1.0 1.0
e NaN NaN
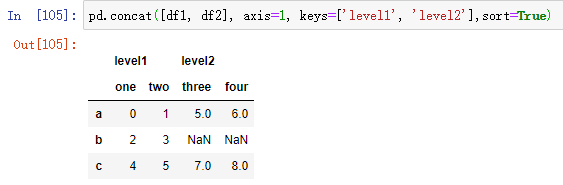
拼接在一起的各部分无法在结果中区分是一个潜在的问题。假设你想在连接轴向上创建一个多层索引,可以使用keys参数来实现:

沿着轴向axis=1连接Series的时候,keys则成为DataFrame的列头:

将相同的逻辑拓展到DataFrame对象:
df1 = pd.DataFrame(np.arange(6).reshape((3, 2)),index=['a', 'b', 'c'],
columns=['one', 'two'])
df2 = pd.DataFrame(5 + np.arange(4).reshape((2, 2)),index=['a', 'c'],
columns=['three', 'four'])
df1
#
one two
a 0 1
b 2 3
c 4 5
df2
#
three four
a 5 6
c 7 8
如果你传递的是对象的字典而不是列表的话,则字典的键会用于keys选项:

还有一些额外的参数负责多层索引生成。例如,我们可以使用names参数命名生成的轴层级:

最后需要考虑的是行索引中不包含任何相关数据的DataFrame:

在这个实例中,我们传入ignore_index=True:

| 参数 | 描述 |
|---|---|
| objs | 需要连接的pandas对象列表或字典;这是必选参数 |
| axis | 连接的轴向;默认是0(沿着行方向) |
| join | 可以是inner或outer(默认是outer);用于指定连接方式是内连接(inner)还是外连接(outer) |
| join_axes | 用于指定其他n-1轴的特定索引,可以替代内/外连接的逻辑 |
| keys | 与要连接的对象关联的值,沿着连接轴形成分层索引;可以是任意值的列表或数组,也可以是元组的数组,也可以是数组的列表(如果向levels参数传入多层数组) |
| leels | 在键值传递时,该参数用于指定多层索引的层级 |
| names | 如果传入了keys和/或levels参数,该参数用于多层索引的层级名称 |
| verify_intergrity | 检查连接对象中的新轴是否重复,如果是,则引发异常;默认(False)允许重复 |
| ingore_index | 不沿着连接轴保留索引,而产生一段新的(长度为total_length)索引 |
2.4 联合重叠数据
还有另一个数据联合场景,既不是合并操作,也不是连接操作。你可能有两个数据集,这两个数据集的索引全部或部分重叠。作为一个示例,考虑Numpy的where函数,这个函数可以进行面向数组的if-else等价操作:
a = pd.Series([np.nan, 2.5, 0.0, 3.5, 4.5, np.nan],
index=['f', 'e', 'd', 'c', 'b', 'a'])
b = pd.Series([0, np.nan, 2, np.nan, np.nan, 5.],
index=['a', 'b', 'c', 'd', 'e', 'f'])
a
#
f NaN
e 2.5
d 0.0
c 3.5
b 4.5
a NaN
dtype: float64
b
#
a 0.0
b NaN
c 2.0
d NaN
e NaN
f 5.0
dtype: float64
np.where(pd.isnull(a), b, a)
#
array([0. , 2.5, 0. , 3.5, 4.5, 5. ])
Series有一个combine_first方法,该方法可以等价于下面这种使用pandas常见数据对齐逻辑的轴向操作:
b.combine_first(a)
#
a 0.0
b 4.5
c 2.0
d 0.0
e 2.5
f 5.0
dtype: float64
我们可以发现,上述代码是将a中的数据传入b中,如果b的行中数据缺失,则使用a中的数据。如果已存在,则保留原来的数据。
在DataFrame中,combine_first逐列做相同的操作,因此你可以认为它是根据你传入的对象来“修补”调用对象的缺失值:
df1 = pd.DataFrame({'a': [1., np.nan, 5., np.nan],
'b': [np.nan, 2., np.nan, 6.],
'c': range(2, 18, 4)})
df2 = pd.DataFrame({'a': [5., 4., np.nan, 3., 7.],
'b': [np.nan, 3., 4., 6., 8.],})

8.3 重塑和透视
重排列表格类型数据有多种基础操作。这些操作被称为重塑或透视。
3.1 使用多层索引进行重塑
多层索引在DataFrame中提供了一种一致性方式用于重排列数据。以下是两个基础操作:
stack(堆叠) 该操作会“旋转”或将列中的数据透视到行
unstack(拆堆) 该操作会将行中的数据透视到列
下面考虑一个带有字符串数组作为行和列索引的小型DataFrame:

在这份数据上使用stack方法会将列透视到行,产生一个新的Series:

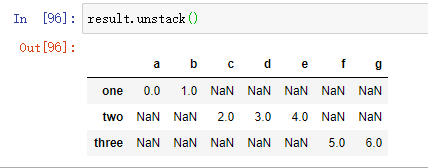
从一个多层索引序列中,你可以使用unstack方法将数据重新排列后放入一个DataFrame中:
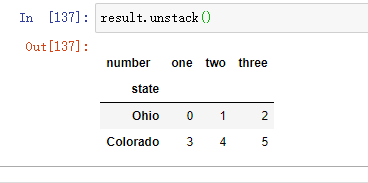
默认情况下,最内层是已拆堆的(与unstack方法一样)。你可以传入一个层级序列号或名称来拆分一个不同的层级:

如果层级中的所有值并未包含于每个子分组中时,拆分可能会引入缺失值:
s1 = pd.Series([0, 1, 2, 3], index=['a', 'b', 'c', 'd'])
s2 = pd.Series([4, 5, 6], index=['c', 'd', 'e'])
data2 = pd.concat([s1, s2], keys=['one', 'two'])

默认情况下,堆叠会过滤出缺失值,因此堆叠拆堆的操作时可逆的:

当你再DataFrame中拆堆时,被拆堆的层级会变为结果中最低的层级:
df = pd.DataFrame({'left': result, 'right': result + 5},
columns=pd.Index(['left', 'right'], name='side'))

在调用stack方法时,我们可以指明需要堆叠的轴向名称:

3.2 将“长”透视为“宽”
在数据库和CSV中存储多时间序列的方式就是所谓的长格式或堆叠格式。让我们载入一些实例数据,然后做少量的时间序列规整和其他的数据清洗操作:
data = pd.read_csv('macrodata.csv')


我们将在之后更深入讲解PeriodIndex。简单地说,PeriodIndex将year和quarter等列进行联合并生成了一种时间间隔类型。这种数据即所谓的多时间序列的长格式,或称为具有两个或更多个键的其他观测数据(这里,我们的键是data和item)。表中的每一行表示一个时间点上的单个观测值。
数据通常以这种方式存储在关系型数据库中,比如MySQL,因为固定模式(列名称和数据类型)允许item列中不同值的数量随着数据被添加到表中而改变。在之前的例子中,data和item通常是主键(使用关系型数据库的说法),提供了关系完整性和更简单的连接。在某些情况下,处理这种格式的数据更为困难,你可能更倾向于获取一个按date列时间戳索引的每个不同的item独立一列的DataFrame。DataFrame的pivot方法就是进行这种转换的。
pivoted = ldata.pivot('date', 'item', 'value')
pivoted

传递的前两个值分别用作行和列索引的列,然后是可选的数值列以填充DataFrame。假设你有两个数列值,你想同时进行重塑:
ldata['value2'] = np.random.randn(len(ldata))
ldata[:10]

如果遗漏最后一个参数,你会得到一个含有多层列的DataFrame:
pivoted = ldata.pivot('date', 'item')
pivoted[:5]

pivoted['value'][:5]

请注意,pivot方法等价于使用set_index创建分层索引,然后调用unstack:
unstacked = ldata.set_index(['date', 'item']).unstack('item')
unstacked[:7]

3.3 将“宽”透视为“长”
在DataFrame中,pivot方法的反操作时pandas.melt。与将一列变换为新的DataFrame中的多列不同,它将多列合并成一列,产生一个新的DataFrame,其长度比输入更长。例:
df = pd.DataFrame({'key': ['foo', 'bar', 'baz'],
'A': [1, 2, 3],
'B': [4, 5, 6],
'C': [7, 8, 9]})
df
#
key A B C
0 foo 1 4 7
1 bar 2 5 8
2 baz 3 6 9
‘key’列可以作为分组标签,其他列均为数据值。当使用pandas.melt时,我们必须指明哪些列是分组指标(如果有的话)。此处,让我们使用’key’作为唯一的组指标:
melted = pd.melt(df, ['key'])
melted

使用pivot方法,我们可以将数据重塑回原先的布局:
reshaped = melted.pivot('key', 'variable', 'value')
reshaped

由于pivot的结果根据作为行标签的列生成了索引,我们可能会将想要使用reset_index来将数据回移一列:
reshaped.reset_index()

你也可以指定列的子集作为列值:
pd.melt(df, id_vars=['key'], value_vars=['A', 'B'])

pandas.melt的使用也可以无须任何分组指标:

