学习时间:2019/11/03 周日晚上23点半开始,计划1110学完
学习目标:Page218-249,共32页;目标6天学完(按每页20min、每天1小时/每天3页,需10天)
实际反馈:实际XXX学完,耗时X天,X小时,平均每页X分钟。
实际应用中,数据可能分散在许多文件或数据库中,存储的形式也不利于分析。本章关注可以聚合、合并、重塑数据的方法。
8.1 层次化索引
层次化索引(hierarchical indexing)是pandas的一项重要功能,它使得能在一个轴上拥有多个(两个以上)索引级别。抽象点说,它使得能以低维度形式处理高维度数据。
看以下例子,创建一个Series并用一个由列表或数组组成的列表作为索引:
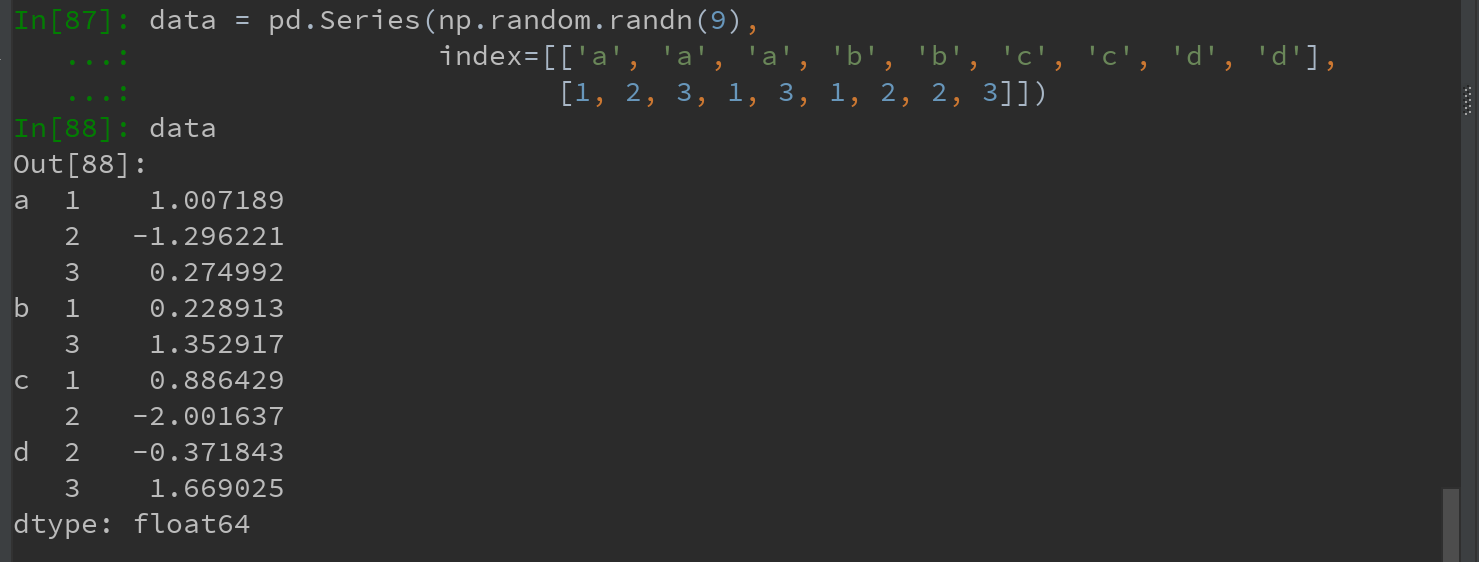
Ps:以上结果是经过美化的带有MultiIndex索引的Series的格式。

1)对于一个层次化索引的对象,可使用所谓的部分索引,使用它选取数据子集的操作更简单:
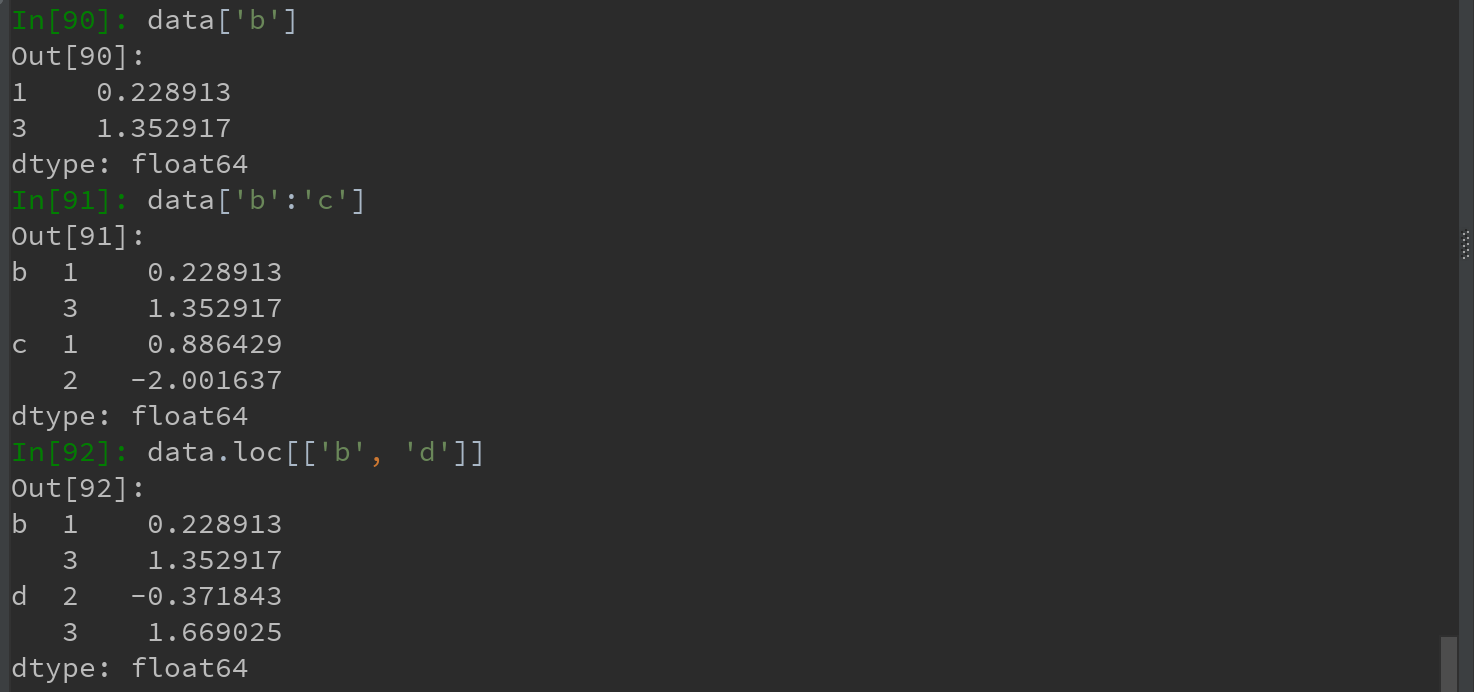
还可以在"内层"中进行选取:

2)层次化索引在数据重塑和基于分组的操作(如透视表生成)中扮演着重要的角色。如,可通过unstack方法将这段数据重新安排到一个DataFrame中:

其中,unstack的逆运算时stack:

8.1.1 重排与分级排序
8.1.2 根据级别汇总统计
8.1.3 使用DataFrame的列进行索引
8.2 合并数据集
8.2.1 数据库风格的DataFrame合并
8.2.2 索引上的合并
8.2.3 轴向连接
8.2.4 合并重叠数据
8.3 重塑和轴向旋转
8.3.1 重塑层次化索引
8.3.2 将"长格式"旋转为"宽格式"
8.3.3 将"宽格式"旋转为"长格式"
8.4 总结
至此,已经掌握了pandas数据导入、清洗、重塑,可进一步学习matplotlib数据可视化。稍后会回到pandas,学习更高级的分析。