版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/Jakob_Hu/article/details/88784810
重塑和旋转
1. 重塑索引
重排索引使用的是pandas模块的 stack和 unstack方法,

stack方法
1)基本使用
对DataFrame使用stack方法可以看做将各列堆叠成竖直方向的索引,生成层次化索引,生成的是一个多层索引的Series,
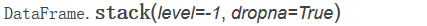

2)dropna参数
stack方法会默认过滤掉缺失值,除非将dropna参数设置为False,

生成两个Series对象,水平方向拼接(拼接可参考教程),并制定索引名为"one"和"two",生成具有缺失值的DataFrame,

3)level参数
如果存在多层列名索引,可以使用 level参数,指定哪一层列索引进行堆叠, level参数默认为 -1,即最后一层列索引,传入的可以是编码,也可以是列名。
unstack方法
1)基本使用
unstack方法则是将多层索引的Series转换为Dataframe,但是与stack不同的是,unstack可以指定将那一层索引去除堆叠,
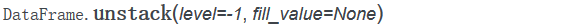
对之前具有层次化索引的Series对象result使用unstack方法,


2)level参数
如果是指定哪层索引去除堆叠,可以使用索引的编号,也可以使用索引对象的名称,

stack 和unstack方法配合使用

格式转换——pivot方法
1)基本使用

官方文档中给出的解释如下,
Uses unique values from index / columns to form axes of the resulting DataFrame.
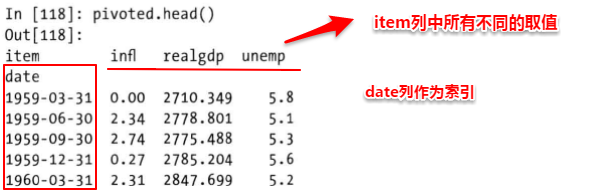
形成类似于课程表一样的基础表格,

将“date”这一列作为索引,将 item这一列不同的值作为列名,将value对应到pivot生成的表格中,

2)value参数
pivot方法的 values参数是可以不用给出来的,


实际上,pivot的作用可以看做是 set_index方法和 unstack方法的结合,
