在R软件中对有序对有序分类因变量做Logistics或者Probit回归,可以采用MASS包里的polr函数进行建模,此函数中使用的是位置结构模型。该函数的使用格式如下:
plor(formula, data, weights, method=c("logistic", "probit", "loglog", "cloglog", "cauchit"))
本例使用MASS包中的housing数据集,该数据集是关于哥本哈根住房情况的调查数据。其中包括5个变量,分别为:房主对他们目前住房的满意度(高、中、低),记为Sat是有序变量;房主认为物业管理的影响程度(高、中、低),记为Infl;租赁住房的类型(塔式、中庭、公寓、露宿),记为Type;与其他住户的沟通程度(低、高),记为Cont;每组对应的居民人数,记为Freq,其中共 个组。以Sat为因变量,Infl、Type、Cont为自变量,建立Logistics回归模型,其中Freq为权重。
回归的代码实现如下:
library(MASS)
house.plr<-polr(Sat~Infl+Type+Cont,weights=Freq,data=housing)
summary(house.plr)
输出结果为:
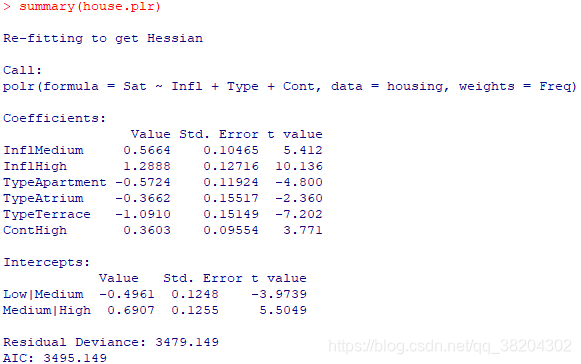
输出结果中为给出InflLow、TypeTower、ContLow对应的系数,因为他们对应的系数为0,有上面的回归系数可以写出对应的回归模型。
另外,我们可以使用函数predict(house.plr)输出有序变量的预测值
,并与真实值Sat进行对比,以分析能够做出正确判断的概率。整理结果如下表所示。

表中1表示低,2表示中,3表示高,对比预测值和真实值容易看出正确判断的概率为
,说明该模型不够理想,可能是由于自变量对因变量的影响不够显著,若要得到更好的结果,需要考虑加入重要的自变量。
有序数据比分类数据含有更多的信息量,从理论上说有序数据因变量回归的效果应该比类别数据因变量的回归效果好。但从实际应用效果看,有序数据因变量回归的效果往往不尽如人意,其回归模型也正在研究和发展中。
