文章目录
Self-Attention For Generative Models
Ashish Vaswani and Anna Huang
Joint work with: Noam Shazeer, Niki Parmar, Lukasz Kaiser, Illia Polosukhin, Llion Jones, Justin Gilmer, David Bieber, Jonathan Frankle, Jakob Uszkoreit, and others.
学习变长数据的表示
Deep learning is all about representation learning.
RNN
- 学习变长数据的表示,这是序列学习的基本组件(序列学习包括 NMT, text summarization, QA)
- 通常使用 RNN 学习变长的表示:RNN 本身适合句子和像素序列
- LSTMs,GRUs和其变体在循环模型中占主导地位
这些RNN的变体显示增加了一些乘法交互,有助于梯度的转移

- 但是
- 序列计算抑制了并行化。
- 没有对长期和短期依赖关系进行显式建模。
- 我们想要对层次结构建模。
- 传递信息过程:将一个句子或一个string输进去,甚至是一张图片的像素序列。每个时间步将之前所有已知信息都融合到一个固定长度的向量中。比如:共指信息、修饰关系等等,因此可能很难建模。
- RNNs(顺序对齐的状态)看起来很浪费!
CNN

- 每层都能够并行化,能够在每个位置同时进行卷积
- 提取局部依赖
- 因为感受野是局部的,因此需要一些线性,如果做扩张卷积,那么就需要深度和对数。线性或对数位置之间的“交互距离”。
- 长距离依赖需要许多层。(层数应该是你输入字符串长度的一个函数)
Attention
attention在NMT中的编码器和解码器之间是很关键的,在解码阶段,解码器需要通过attention来决定从输入中吸收哪些信息。attention就像记忆检索机制(memory retrieval mechanism)
为什么不把attention用于表达呢?
Self-Attention

- 这只是一个粗略的的框架,如果你要重新构建词 的表示,将它(一开始只是一个词embedding)与其他所有词(embedding)比较,基于这些比较,就会得到其他词的一个加权组合,最后基于加权组合,你总结了所有这些信息。就好像你在某些方面(上下文词的加权组合)重新表示自己一样。当然也可以增加前馈层来计算一些简单的特征。
- Constant ‘path length’ between any two positions:任意一个位置可以同时与其他位置进行交互,即任意两个位置路径长度都为1
- Gating/multiplicative interactions:门控/乘法的交互
- Trivial to parallelize (per layer):使用matmul就可以很容易并行
- 自注意力能够完全替代序列计算吗?
Previous work
Classification & regression with self-attention:
Parikh et al. (2016), Lin et al. (2016)
Self-attention with RNNs:
Long et al. (2016), Shao, Gows et al. (2017)
Recurrent attention:
Sukhbaatar et al. (2015)
- 与transformer最接近的是Memory Network
The Transformer
Attention is permutation invariant. Attention是排列不变量,所以改变单词顺序,不会改变实际输出。所以为了维持位置信息,加入位置表示(position representations)。

- Encoder
- self-attention层只是重新计算表示。对于每个位置,同时开始使用attention
- 然后接一个前馈层
- residual connections,每层都有
- 然后将self-attention层和前馈层组合重复多次就形成了 encoder
- Decoder
- self-attention层
- Encoder-Decoder Attention,与encoder最后一层的输出进行交互
- 然后接一个FFNN
- 将这三层进行重复
Encoder Self-Attention

- 以计算 的表示为例
- 首先将 线性转化(linear transformation)为一个 query
- 然后将所有邻居线性转化为 key
- 这些线性转化实际上可以被认为是特征
- 实际上是双线性形式,将这些向量投射到一个空间,在那个空间里,向量乘积可以被认为是相似性,然后使用softmax求组合系数
- 对每个位置使用先行转化得到 value,根据组合系数,将 value组合,最后通过一个FFNN得到 的最终表示
- 这些计算只需要两个矩阵乘法,如上图中公式是计算注意力的过程, 是比例因子,只是为了不让乘积过大。
Decoder Self-Attention

- 与encoder self-attention 很像
- 增加了mask
Attention is Cheap!

Mutil-head Attention
Attention: a weighted average
目前的attention是一个加权平均

Convolutions

Self-Attention

- self-attention 也是如此,将所有信息进行加权平均了,如上图中将三个信息进行了加权平均,三个词都显得很重要,I 表示主语,kicked 表示动作,ball 表示宾语。但如果将三者混合在一起,并不能区分开每个权值所表示的含义。因此我们需要让注意力权值变得不同–>如何让注意力权值变得不同–>使用多个注意力头
- Attention head: Who

- Attention head: Did what?

- Attention head: To whom?

- 可以将注意力层看作是一个特征检测器,因为在计算注意力之前,将向量使用线性变换转到了不同的空间,因此在这个空间有可能有可能开始关注语法(或者其他特征)
- 这些注意力计算可以并行,且使用的线性转换空间维度变小了
- 在一些限制下,可以证明 多头注意力可以达到与卷积相同的功能

Machine Translation: WMT-2014 BLEU

Attention is All You Need (NeurIPS 2017) Vaswani*, Shazeer*, Parmar*, Uszkoreit*, Jones*, Kaiser*, Gomez*, Polosukhin*
Frameworks
tensor2tensor
Sockeye
Importance of Residuals

残差连接携带位置信息到更高层,以及其他信息。
Training Details


Self-Similarity, Image and Music Generation
Self-similarity in images
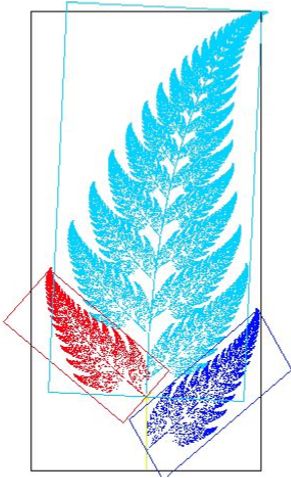

Self-similarity in music

- 主题再重复,马上或隔一段距离
Probabilistic Image Generation
- 对像素的联合分布建模(就像图片上的语言建模)
- 将其转化为一个序列建模问题
- 分配概率允许度量泛化
- RNNs 和 CNNs 是最优模型(PixelRNN, PixelCNN)
- 包含 gating 的CNN现在在质量上与RNN匹配
- 由于并行,CNNs 更快
- 长距离依赖对图像很重要(比如,对称)
- 可能随着图像大小的增加而变得越来越重要
- 用CNNs建模长期依赖关系需要
- 很多层 会让训练更加困难
- 大参数/计算代价下的 大卷积核
Texture Synthesis with Self-Similarity

Texture Synthesis by Non-parametric Sampling (Efros and Leung, 1999)
基于非参数采样的纹理合成
Non-local Means

-
利用自相似性进行图像去噪,BCM 2005
-
A Non-local Algorithm for Image Denoising (Buades, Coll, and Morel. CVPR 2005)
-
Non-local Neural Networks (Wang et al., 2018)
Previous work
- Self-attention:
Parikh et al. (2016), Lin et al. (2016), Vaswani et al. (2017) - Autoregressive Image Generation:
A Oord et al. (2016), Salimans et al. (2017)

- 将 embedding 换成 小块图片,则self-attention在这些小块图片之间,计算基于内容的相似性,然后基于相似性,构造一个凸组合将所有信息联合起来。

- 将Transform应用于图片中,有些地方需要进行调整
Attention is Cheap if length << dim!

- 图片展开后 length 要比 dim大,因此需要更多的计算
- 简单的解决方法
- 将局部性与 self-attention 结合
- 将注意力窗口限制为局部区域
- 是一个好的假设,因为空间局部性
- 有两种光栅化


Image Transformer Layer

- 局部 self-attention,位置编码是二维的。
Tasks
- 超分辨率
- 无条件和条件图像生成
Results
Image Transformer
Parmar*, Vaswani*, Uszkoreit, Kaiser, Shazeer, Ku, and Tran. ICML 2018
- Unconditional Image Generation

- CIFAR-10和Imagenet数据集上各种模型的交叉熵。
- PixelSNAL 是卷积和self-attention的混合
- Cifar10 Samples

- 结构性的物体容易被捕获
- CelebA Super Resolution


- CelebA上图像转换器的人因评估性能。被欺骗的人的比例明显好于以前的技术水平。
- Cifar10 SuperResolution

- Conditional Image Completion

- 最后一列是补全后真实的图片,中间三张是模型补全的
- 第三行第三列模型把人也补全了,说明模型已经有了一些“知识”
Music generation using relative self-attention
Music Transformer (ICLR 2019) by Cheng-Zhi Anna Huang, Ashish Vaswani, Jakob Uszkoreit, Noam Shazeer, Ian Simon, Curtis Hawthorne, Andrew M. Dai, Matthew D. Hoffman, Monica Dinculescu and Douglas Eck.
Blog post: https://magenta.tensorflow.org/music-transformer
Raw representations in music and language

Music Language model: Prior work Performance RNN (Simon & Oore, 2016)

- 将音乐建模为一个序列,每步的输出为 note on(音符通),note off(关),note velocity,advanced clock
Continuations to given initial motif
给定初始的主题,然后进行延续

- 训练时只有生成时一半的长度
- RNN-LSTM 随着距离变长,对之前的节奏不能很好的捕获
- Transformer 在超出训练长度之后,效果立马变差了
- Music Transformer 生成效果最好
Self-Similarity in Music

Sample from Music Transformer

- 不同的颜色的线表示不同的注意力头,指示了在生成那个 note 时,关注之前的哪些 note
- 这里的 self-attention 是 note-note level 或者说 event-event level

常规的注意力机制是过去历史的加权平均,不管多远,我们都能直接接触到它。但有点像词袋模型,不能区分不同的特征,比如说节奏

不同的卷积核能够捕捉不同的特征

- Music Transformer 使用平移不变性来携带超过其训练长度的关系信息,进行传递
Closer look at attention
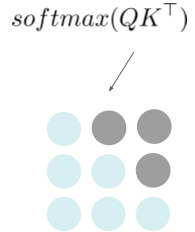
- 获得了自相似矩阵
Closer look at relative attention

- 加入了相对位置关系,区别于 key 和 query 的距离
Machine Translation (Shaw et al, 2018)

- relative attention 在机器翻译中能够帮助模型提升性能,但翻译是句子到句子,都比较短,而音乐需要2000时间步


- 将相对距离转化为绝对距离(没太懂)


Convolutions and Translational Equivariance
卷积与平移等变

- 卷积计算出来的激活值只与相对位置有关,而与绝对位置无关
- 相对位置平移等变

- relative attention 在图中有作用


- self-attention 就像一种信息传递机制
- Mutiple Towers 和 Mutiple head 很类似(虽然没听懂。。)
Self-Attention
- 任何两个位置之间的“路径长度”都是常数
- 无限的记忆
- 每层都容易并行化
- 能够对自相似性建模
- 相对注意力(Relative attention)提供了表达时间、等价性,并自然地扩展到图形。
课件最后部分介绍了很多这一方面的论文
Future
- Multitask learning
- Long-range attention
总结
-
介绍了自注意力的思想:用自己(一个词)与自己(句子中所有词)的关系来重新表示自己(所有词的加权和)
- 能够加快训练的两个优势:
- 任何位置相互作用,都能直接接触,而RNN中,两个相隔较远的位置,需要很多时间步的传递。即有数据相关。而 Transformer 能够在每层并行计算
- 计算快,只需要两个矩阵乘法
- 训练快,为以 Transformer 基础部件的模型的增大提供了条件
- 能够加快训练的两个优势:
-
多头注意力:注意力层相当于特征检测器,多个注意力头能够捕获不同的特征(比如,语法等等)
-
Transformer
- encoder中:
- self-attention 层,多头注意力
- 加入位置编码,因为attention结果与位置无关
- 后接FFNN
- 每层之间有 skipping connection
- 重复(self-attention, FFNN)
- decoder中:
- 带 mask 的self-attention 层
- 后接Encoder-Decoder attention,将encoder的最后一层连过来
- 然后接FFNN
- 重复(self-attention, Encoder-Decoder attention, FFNN)
- encoder中:
-
将Transformer 应用于图片任务中
- 将词嵌入换成小块图片,将图片建模为序列任务,能够建模自相似性
- 展示了在超分辨率,图像生成,图片补充等方面的任务
-
Transformer 在音乐生成方面的作用
- 主要是 relative attention(没太懂)
-
我觉得,注意力即就是乘法或加法交互,让两个东西产生关联,不过这样失去了位置信息,需要额外加入位置信息。
-
一个很有用的学习资料,含有代码实现:http://nlp.seas.harvard.edu/2018/04/03/attention.html
