Python-深度学习-学习笔记(12):keras搭建多层神经感知网络(正反向传播)
Keras是一个模型级的深度学习链接库,Keras只处理模型的建立、训练、预测等功能。深度学习底层的运行,例如张量(矩阵)运算,Keras必须配合“后端引擎”进行运算。目前Keras提供了两种后端引擎:Theano 与Tensorflow。
在用Keras设计神经网络的时候,只需添加每层及该层的参数即可,就像做汉堡一样,逐层添加。
搭建神经网络步骤
1、建立模型
1.1、 建立Sequential模型
Sequential模型是多个神经网络的线性堆叠。类似于一个框架结构,之后将设计好的层及层的参数填到到这个模型中,实现一个整体网络的效果。
"""
建立Sequential模型
"""
from keras.models import Sequential #在使用前需要先提前导入这个函数
model = Sequential()
1.2、建立“输入层”与“隐蔽层”
Keras已经内建了各种神经网络层,只需将各层的模型添加到整体框架中,并设置各层的参数,即可完成封装。这里第一步是添加“输入层”和“隐蔽层”,因为输入层即添加输入的节点数,这里需要配合一个隐蔽层来完成参数的设置,输入神经元个数根据你输入神经网络的数据来决定。
from keras.layers import Dense
"""
建立输入层和第一层隐蔽层
参数:
units - 隐蔽层神经元个数
input_dim - 输入层神经元个数
kernel_initializer - 使用normal distribution正态分布的随机数来初始化权重和方差
activation - 定义激活函数
"""
model.add(Dense(units = 256,
input_dim = 784,
kernel_initializer = 'normal',
activation = 'relu'))
1.3、建立多层隐蔽层
这里属于选做部分,如果你想搭建一个单层神经网络或者2层神经网络,那么只需要一层隐蔽层,在上一步已经与输入层嵌到一个模型中了。但如果你发现训练的效果并不是很好,或者误差有点高,可以通过增加隐蔽层数目来提高算法的准确度。
"""
建立隐蔽层
参数:
units - 隐蔽层神经元个数
kernel_initializer - 使用normal distribution正态分布的随机数来初始化权重和方差
activation - 定义激活函数
"""
model.add(Dense(units = 1000, #定义隐蔽层神经元个数为256个
kernel_initializer = 'normal', #使用正太分布的随机数初始化参数
activation = 'relu')) #定义激活函数为relu
由于这里是第二个隐蔽层,通过Sequential模型与上一层相连,所以不再需要定义输入神经元个数
训练结束后,可能会遇到训练集和测试集准确率相差过大(过拟合)的问题,那么我们可以通过在隐蔽层添加dropout层,输入的特征都是有可能被随机消除的,所以该神经元不会再特别依赖于任何一个输入特征,不会给任何一个输入设置太大的权重,从而降低过拟合问题。或者还可以采用一些其他的方法,例如L2泛化等,这里就不多做解释。
from keras.layers import Dropout
model.add(Dropout(0.5)) #随机消除50%的神经单元
1.4、建立输出层
同样的道理,输出层与最后一层隐蔽层通过Sequential模型相连,所以不需要定义输入神经单元个数,但是需要设置输出神经单元个数,这里的输出神经单元个数就是你定义的分类个数(或者是其他的一些输出标准,这个是你自己定的),输出的激活函数一般常用的2元的采用sigmoid,多元的采用softmax,或者是一些其他的激活函数。
"""
建立输出层
参数:
units - 输出层神经元个数
kernel_initializer - 使用normal distribution正态分布的随机数来初始化权重和方差
activation - 定义激活函数
"""
model.add(Dense(units = 10,
kernel_initializer = 'normal',
activation = 'softmax'))
1.5、查看模型摘要
print(model.summary())

通过此代码可以显示你配置好的网络结构参数,参数部分的计算法则为:
Param = (上一层神经元数量)*(本层神经元数量)+(本层神经元数量)
黄色箭头的位置为搭建该模型用到的参数总计。
2、进行训练
2.1、定义训练方式
"""
定义训练方式
参数:
loss - 损失函数: 这里采用交叉熵的方式
optimizer - 优化器: 使用adam优化器可以让训练收敛更快
metrics - 评估模型:设置为准确率
"""
model.compile(loss = 'categorical_crossentropy',
optimizer = 'adam', metrics = ['accuracy'])
优化器的选择有很多种,需要根据你训练数据的特点来进行选择,这里简单介绍一下每种优化器的特点。
(1)SGD:随机梯度下降
- 最基础的优化器,从样本中随机选取batch_size样本进行一次更新,在保证收敛的情况下减少计算量。
- 可以调整Momentum参数,增加一阶动量,在更新时一定程度上保留上次更新的 方向,可以增加一定的稳定性,并具有一定摆脱局部最优的能力。
- 可以调整Nesterov参数,为优化器增加向前多看一步的能力,增强一阶动量的效果。
(2)Adagrad
- 对学习率进行了约束,出现频率高的参数用较小的学习率进行更新,出现频率小的 参数用较大的学习率进行更新。
- Adagrad累加之前所有的梯度和作为分母,在训练的中后期,可能会导致更新的步 伐越来越小,从而提前结束训练。
(3) RMSprop:
- 使用之前梯度的平均值,缓解了Adagad学习率衰减过快的问题。
- 对学习率得约束效果介于Adagrad与Adadelta之间。
(4) Adadelta
- 相对于Adagrad使用全部的梯度对学习率进行约束,Adadelta只使用最近部分的梯度参数。
- 在训练中期,可能加速效果不错,但在训练的后期,可能会在最小值附近波动。
(5)Adam
- 相当于一种结合了Momentum和RMSprop的算法。
- 在实际应用中,最为常见的一种算法。
- 可调整参数amsgrad应用AMSgrad变体,约束其学习率为正数,记录迄今为止提 地更新的最大值,并用他来更新学习率。
(6) Adamax
- 是Adam算法的一种变体,对算法学习率得上限给出了一个更简单得范围。
(7)Nadam
- Nadam算法是一种结合了Adam和Nesterov方法的算法,增强Adam算法一阶动量方面的效果,可能会使优化器相对于Adam收敛的速度加快。
下面是keras官方文档给出来的优化器以及参数代码。
2.2、开始训练
"""
开始训练
参数:
X_train_normalize - feature数字图像的特征值
y_train_one_hot - 数字图像的真实标签
metrics - 评估模型:设置为准确率
validation_spli - 训练与验证数据比例:80%用作训练数据,20%用作验证数据
epochs - 训练周期
batch_size - 每批次的数据项数
verbose - 显示训练过程
"""
train_history = model.fit(x=X_train_normalize,
y=y_train_one_hot,validation_split=0.2,
epochs=10,batch_size=200,verbose=2)
这里的训练周期和每批训练数据量的大小都是需要大家自己去尝试的,训练周期不是越长越好,每次训练的数量也不是越多越好,只要能够再保证训练结果准确且过拟合现象不严重的情况下,尽可能的减少训练时间,那么这样搭建出来的模型就是一个好模型。

fit函数返回一个History的对象,其History.history属性记录了损失函数和其他指标的数值随epoch变化的情况,如果有验证集的话,也包含了验证集的这些指标变化情况。

2.3、建立显示过程
import matplotlib.pyplot as plt
def show_train_history(train_history,train,validation):
"""
显示训练过程
参数:
train_history - 训练结果存储的参数位置
train - 训练数据的执行结果
validation - 验证数据的执行结果
"""
plt.plot(train_history.history[train])
plt.plot(train_history.history[validation])
plt.title('Train History')
plt.ylabel(train)
plt.xlabel('Epoch')
plt.legend(['train','validation'],loc = 'upper left')
plt.show()
show_train_history(train_history,'acc','val_acc') #绘制准确率执行曲线
show_train_history(train_history,'loss','val_loss') #绘制损失函数执行曲线
效果如下:

3、评估模型准确率
根据训练来分析此模型的准确率。
# 评估模型的准确率
scores = model.evaluate(X_test_normalize, y_test_one_hot)
print()
print('accuracy=',scores[1])
返回值:
score[0]:损失值
score[1]:准确率
4、进行预测
用训练好的模型对新的数据进行预测。
#进行预测
prediction = model.predict_classes(X_test)
print(prediction)
5、模型保存
模型训练完成后可以保存为.h5文件,其中包括训练好的参数、权重等等,下次打开后可以直接使用。
model.save(r'C:\Users\dell\Desktop\model.h5') #路径自己选
总结
利用keras搭建神经网络真的方便了好多,你不需要去计算矩阵的维度,不需要去定义权重参数,也不需要去封装优化器或是激活函数等一些复杂的工具,只需要使用某个keras关键字就可调用某种功能,所以非常适合神经网络的初学者来搭建模型。
我通过搭建了一些简单的神经网络,总结出来我分析和搭建神经网络的基本步骤(仅供参考)。
1、首先要先分析我们的输入数据特点,包括像素大小,是单色还是RGB三色等等。
2、搭建基本模型,确定网络层数和各层神经单元个数,这里大家可以做一个循环,从而对比哪层的效果最后(可以用plot将图像画在一张图中,这样对比更明显),一般层数和神经单元数增加到一定程度效果会提升的不是很明显,要把握好那个临界点。
3、通过观察训练集和测试集准确率的变化,判断过拟合问题,选择适当的正则化方法和参数,从而抑制过拟合问题,主要目的是在保证准确率的前提下将过拟合问题尽可能的减小,但又不能让训练集的准确率低于测试集,因为这样可能是训练没有达到效果。
4、通过观察训练集和测试集的损失函数下降情况来选择合适的优化器,使得损失函数尽可能的降低,从而使得参数最优化,实现最好的分割方向。
5、改变学习率参数(不过这里还是建议使用官方推荐的参数)。
6、将这几部分进行协调配合,从而获得最适合数据集的神经网络训练模型。
最后附上整体代码实例:
import tensorflow as tf
import numpy as np
import keras
from keras.models import Sequential
from keras.layers import Dense,Activation,Dropout
from keras.datasets import mnist
from keras.utils import np_utils
import matplotlib.pyplot as plt
#数据预处理
(x_train,y_train),(x_test,y_test)=mnist.load_data() #加载数据集
x_train=x_train.reshape(60000,784) #重塑
x_test=x_test.reshape(10000,784)
x_train.astype('float32')
x_test.astype('float32')
x_train_normalize=x_train/255 #标准化
x_test_normalize=x_test/255
y_train_onehot = np_utils.to_categorical(y_train) #one_hot转换
y_test_onehot = np_utils.to_categorical(y_test)
shenjingyuan_accuracy=[]
train_historys = []
"""
添加图像绘制功能
"""
def show_train_history(train_history,train,validation,i):
plt.plot(train_historys.history[train])
plt.plot(train_historys.history[validation])
plt.title('Train History with '+ str(i) + 'hidden layers')
plt.ylabel(train)
plt.xlabel('Epoch')
plt.legend(['train','validation'],loc='upper left')
plt.show()
#建立模块(逐渐增加层数)
for i in range(1,3):
model=Sequential()
model.add(Dense(units=100,input_dim=784,kernel_initializer='normal',activation='relu'))
if i>2:
model.add(Dense(units=100,kernel_initializer='normal',activation='relu'))
model.add(Dropout(0.4))
if i>1:
model.add(Dense(units=100,kernel_initializer='normal',activation='relu'))
model.add(Dropout(0.4))
model.add(Dense(10,activation='softmax'))
print(model.summary())
#定义训练
model.compile(loss='categorical_crossentropy',optimizer='adam',metrics=['accuracy'])
train_history=model.fit(x=x_train_normalize,
y=y_train_onehot,
validation_split=0.2,
epochs=15,batch_size=128,verbose=2)
score=model.evaluate(x_test_normalize,y_test_onehot)
print("The loss:",score[0],end='')
print("The accuracy:",score[1],end='')
#shenjingyuan_accuracy.append(score[1])
train_historys.append(train_history)
show_train_history(train_historys,'acc','val_acc',i)
show_train_history(train_historys,'loss','val_loss',i)
初学神经网络,哪里有不对的地方还请大神们批评指正。
附加
前向传播
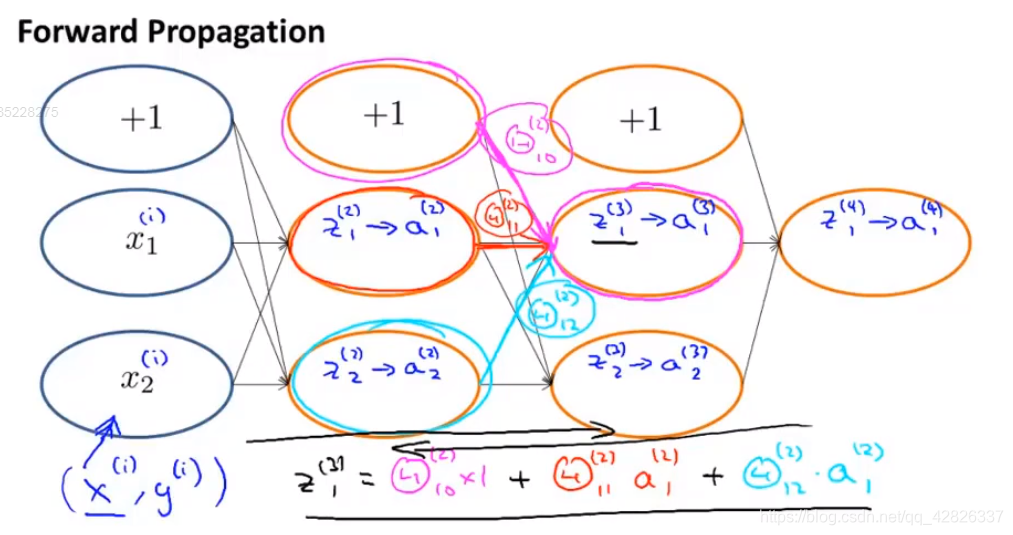
反向传播

公式

