一、神经网络简单原理
逻辑回归只能解决线性可分问题,对于异或问题,无法找到一条直线分割两个类,则引入了神经网络,加入更多的神经元以及激活函数来拟合非线性问题。
逻辑回归介绍在我另一篇博客:逻辑回归介绍与代码实现
神经网络结构
神经网络包含一层输入层,输入数据的特征,至少一层的隐藏层,和输出层。
该例子输入数据x有三个特征,隐藏层包含三个神经元,输出层输出一个神经元。该例子可用于解决回归问题与二分类问题,若解决回归问题,不需要经过激活函数,若解决二分类问题,输出层经过sigmoid激活函数将输出值映射到0-1之间,与0.5比较大小判断输出类别。
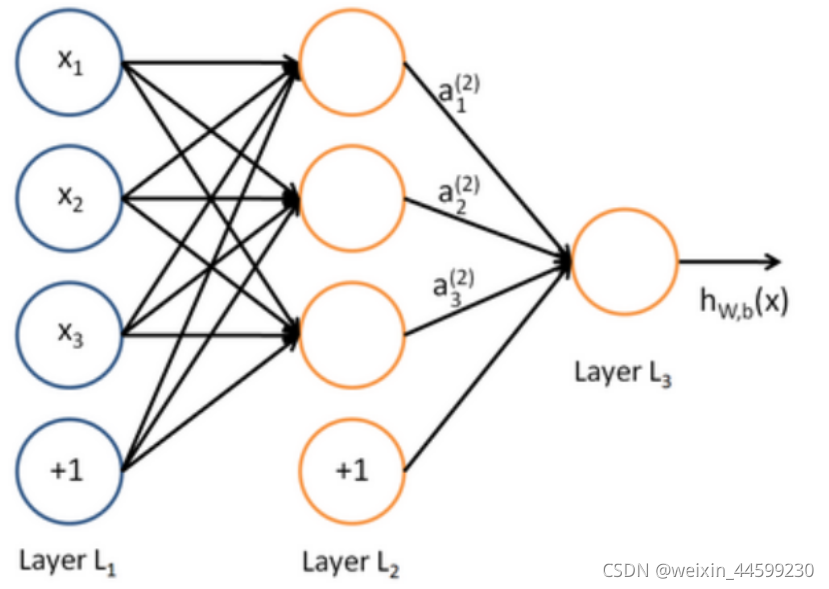
前向传播计算
该图中最下边多出的神经元,用于表示偏置值,该神经元的值永远是1,与对应的权重相乘,可以表示偏置值
对于隐藏层
a i ( 2 ) = g ( [ ∑ j = 1 3 ( x j θ i j + b i ( 2 ) ) ] ) a_{i}^{(2)}=g([\sum_{j=1}^{3}(x_{j} \theta_{ij}+b_{i}^{(2)} )]) ai(2)=g([∑j=13(xjθij+bi(2))])
θ i j ( 2 ) \theta_{ij}^{(2)} θij(2)表示第2层第i个神经元与第1层第j个神经元的连接权重
g表示激活函数
对于输出层
h = g ( [ ∑ j = 1 3 ( a j ( 2 ) θ i j ( 3 ) + b i ( 3 ) ) ] ) h=g([\sum_{j=1}^{3}(a_{j}^{(2)} \theta_{ij}^{(3)}+b_{i}^{(3)} )]) h=g([∑j=13(aj(2)θij(3)+bi(3))])
θ i j ( 3 ) \theta_{ij}^{(3)} θij(3)表示第3层第i个神经元与第1层第j个神经元的连接权重
公式全部展开写:
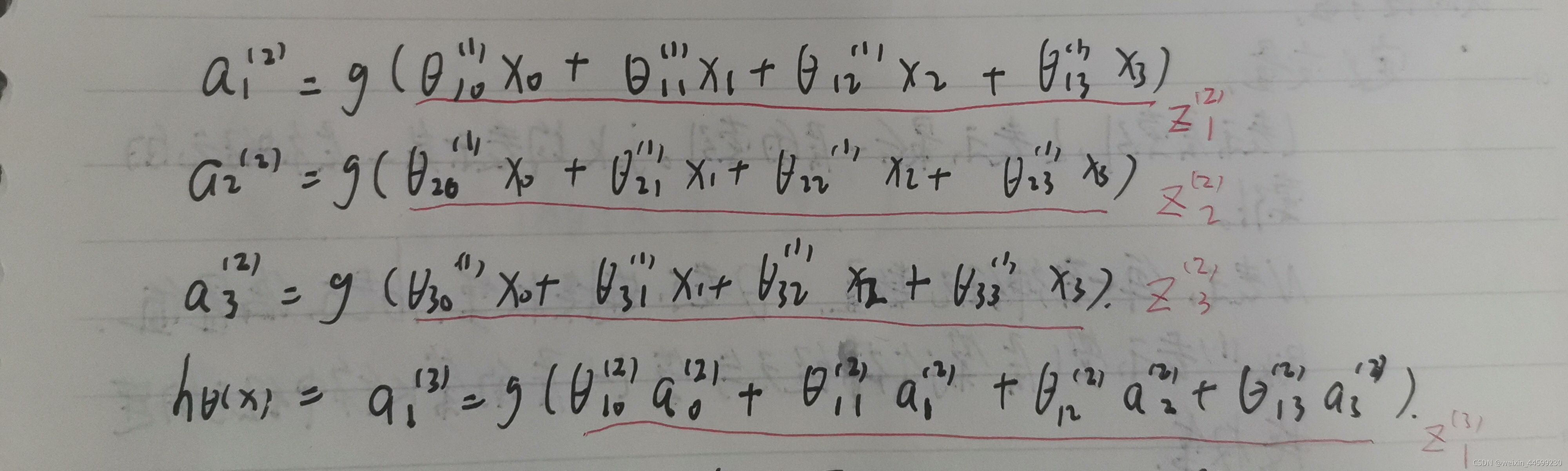
该式子与矩阵相乘的运算规则类似,可以将前向运算过程转化为矩阵运算
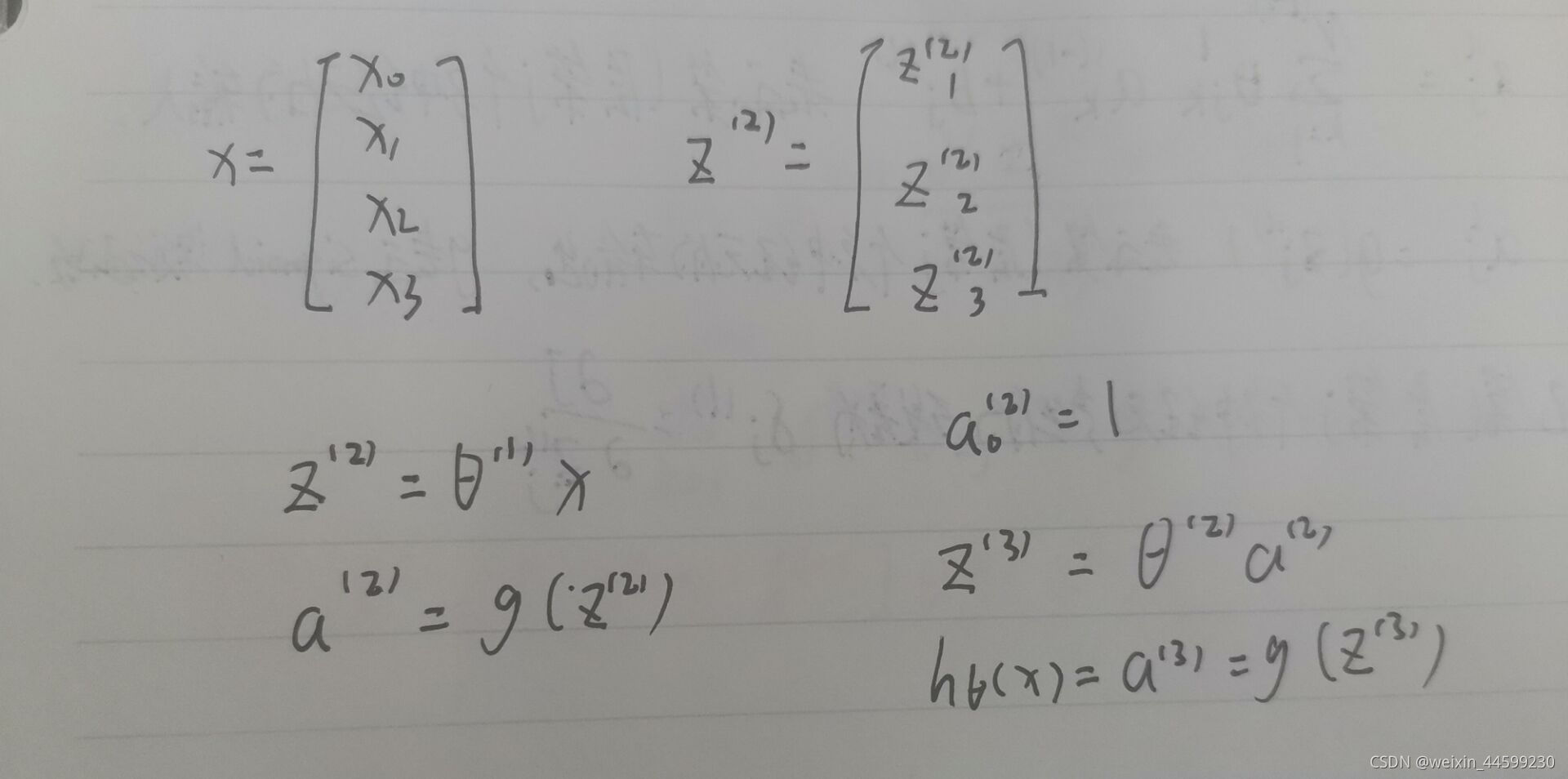
θ ( 1 ) \theta ^{(1)} θ(1)代表第一层的全部参数的矩阵 θ 10 ( 1 ) , θ 11 ( 1 ) , θ 12 ( 1 ) , θ 13 ( 1 ) \theta_{10}^{(1)},\theta_{11}^{(1)},\theta_{12}^{(1)},\theta_{13}^{(1)} θ10(1),θ11(1),θ12(1),θ13(1)…,该例子中 θ ( 1 ) \theta ^{(1)} θ(1)是一个3*4的矩阵
代价函数
当用与C(C>2)分类任务时,输出层是C个神经元,可以看成是C个二分类问题,例如一个三分类任务,判断一个动物是猫、狗还是猪,输出层是三个神经元,第一个神经元判断是猫还是非猫,第二个神经元判断是狗还是非狗,第三个神经元判断是猪还是非猪,哪个神经元输出值最大判定为哪一类。
y的标签值也不是1 2 3 ,而是one-hot编码后的值,一共三类第一类表示为[1,0,0],第二类表示为[0,1,0],第三类表示为[0,0,1]
代价函数:
J ( θ ) = − 1 m [ ∑ i = 1 m ∑ k = 1 K y k ( i ) l n ( h ( x ( i ) ) ) k + ( 1 − y k ( i ) ) l n ( 1 − h ( x ( i ) ) ) k ] J( \theta )=-\frac{1}{m} [\sum_{i=1}^{m} \sum_{k=1}^{K} y_{k}^{(i)} ln(h(x^{(i)}))_{k}^{}+(1-y_{k}^{(i)})ln(1-h(x^{(i)}))_{k}^{}] J(θ)=−m1[∑i=1m∑k=1Kyk(i)ln(h(x(i)))k+(1−yk(i))ln(1−h(x(i)))k]
y k ( i ) y_{k}^{(i)} yk(i)代表第i个样本标签值的第k个分量, h ( x ( i ) ) k h(x^{(i)})_{k} h(x(i))k代表输出值的第k个分量
二、反向传播公式推导
定义变量
l表示层索引,L表示最后一层的索引,jk均表示某一层神经元的索引
N表示每一层神经元数量。 θ \theta θ代表连接权重,b代表偏置
θ i j ( l ) \theta_{ij}^{(l)} θij(l)表示第l层第j个神经元与第l-1层第k个神经元的连接权重
b j ( l ) b_{j}^{(l)} bj(l)代表第l层第j个神经元的偏置值
z j ( l ) = ∑ k = 1 N ( l − 1 ) [ θ j k ( l ) a k ( l − 1 ) + b j ( l ) ] z_{j}^{(l)}=\sum_{k=1}^{N^{(l-1)}}[ \theta_{jk}^{(l)}a_{k}^{(l-1)}+b_{j}^{(l)}] zj(l)=∑k=1N(l−1)[θjk(l)ak(l−1)+bj(l)]表示第l层第j个神经元的输入
a j ( l ) = g ( z j ( l ) ) a_{j}^{(l)}=g(z_{j}^{(l)}) aj(l)=g(zj(l))表示第l层第j个神经元的输出 g表示激活函数
第第l层第j个神经元残剩的残差为 ξ j ( l ) = ∂ J ∂ z j ( l ) \xi_{j}^{(l)}=\frac{\partial J}{\partial z_{j}^{(l)}} ξj(l)=∂zj(l)∂J
反向传播公式推导
对于输出层:
该推导过程是按照激活层是sigmoid激活函数的,一般多分类输出层激活函数是softmax,由于本人刚刚在逻辑回归中推到过该式子,所以还是以sigmoid为激活函数推导,以softmax为激活函数的推导过程请读者自行推导,如果没记错的话也是h-y

对于隐藏层:

对于连接权重和偏置值

然后根据代价J对每个参数的偏导数值,使用梯度下降法方可求解最优解。
梯度下降原理可以参考这一篇文章:梯度下降原理
三、python代码实现,基于numpy
使用sklearn自带的鸢尾花数据集,构建一个简单的三层神经网络,第二层十个神经元,第三层三个神经元
from sklearn import datasets
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
#relu激活函数
def relu(x):
x=np.where(x>0,x,0)#大于0的还是本身,小于0的设置为0
return x
#relu激活函数的导数,大于0的导数是1,小于0的导数是0
def back_relu(z):
return np.where(z>0,1,0)
#最后一层softmax激活函数,输出一个概率分布
def softmax(x):
a=np.sum(np.exp(x), axis=1)
b=np.expand_dims(a, 1).repeat(3, axis=1)
return np.exp(x)/b
#把离散的类别转化为one-hot编码
def trans_label(labels):
newlabels=np.zeros((len(labels),3))
for i,label in enumerate(labels):
newlabels[i,label]=1
return newlabels
#评估模型准确率
def evaluate(x_test,y_test):
num_correct = 0
for x, y in zip(x_test, y_test):
y_hat = model.predict(x)
y = np.argmax(y)
if y_hat == y:
num_correct += 1
acc=num_correct / len(x_test)
return acc
class model():
def __init__(self,num_iters=200,lr=0.15):
"""
:param num_iters: 迭代次数
:param lr: 学习率
"""
#定义模型参数
#这是一个三层的神经网络,第一层是输入层,第二层有十个神经元,第三层有三个神经元,因为是3分类
self.Theta2 = np.random.rand(4, 10)
self.Theta3 = np.random.rand(10, 3)
self.B2 = np.zeros(10)
self.B3 = np.zeros(3)
self.num_iters=num_iters
self.lr=lr
#模型的训练
#由于该例子模型较为简单,为便于理解前向传播与反向传播梯度下降都是一步一步来的,如果模型较为复杂,可以使用循环
def fit(self,X,Y):
"""
:param X: 特征矩阵
:param Y: 类别
:return:
"""
#数据个数
m=len(X)
for k in range(self.num_iters):
loss = 0
#损失对各个参数的偏导数
dj_dTheta3 = 0
dj_dB3 = 0
dj_dTheta2 = 0
dj_dB2 = 0
for i in range(len(X)):
#由于用到矩阵相乘,将其扩充一个维度
x = np.expand_dims(X[i], 0)
y = Y[i]
z2 = np.dot(x, self.Theta2) + self.B2
a2 = relu(z2)
z3 = np.dot(a2, self.Theta3) + self.B3
a3 = softmax(z3)
h=a3
loss += -(np.sum(np.multiply(y, np.log(h + 1e-5))) +
np.sum(np.multiply((1 - y), np.log(1 - h + 1e-5))))
#防止ln函数溢出,加一个1e-5
XI3 = a3 - y
XI2 = np.multiply(np.dot(XI3, self.Theta3.T), back_relu(z2))
dj_dTheta3 += np.dot(a2.T, XI3)
dj_dB3 += XI3
dj_dTheta2 += np.dot(x.T, XI2)
dj_dB2 += XI2
dj_dTheta3 /= m
dj_dB3 /= m
dj_dTheta2 /= m
dj_dB2 /= m
#进行梯度下降
self.Theta3 = self.Theta3 - self.lr * dj_dTheta3
self.B3 = self.B3 - self.lr * dj_dB3
self.Theta2 = self.Theta2 - self.lr * dj_dTheta2
self.B2 = self.B2 - self.lr * dj_dB2
loss /= m
print("num_iter:%d,loss:%f"%(k,loss))
#前向传播
def forward(self,x):
x = np.expand_dims(x, 0)
z2 = np.dot(x, self.Theta2) + self.B2
a2 = relu(z2)
z3 = np.dot(a2, self.Theta3) + self.B3
a3 = softmax(z3)
h=a3
return h
#预测样本类别
def predict(self,x):
h=self.forward(x)
#输出的三个概率分布,最大的那个判定为那一类
y_hat=np.argmax(h,1)[0]
return y_hat
if __name__ == '__main__':
iris = datasets.load_iris()
data = iris.data
label = iris.target
label = trans_label(label)
#数据标准化
std = StandardScaler()
data = std.fit_transform(data)
x_train, x_test, y_train, y_test = train_test_split(data, label, test_size=0.2, random_state=0)
model=model()
model.fit(x_train,y_train)
print("训练完成")
acc=evaluate(x_test,y_test)
print("测试集正确率为:%.3f%%"%(acc*100))
运行结果:
D:\Anaconda3\python.exe D:/pycharmproject/机器学习算法复习/神经网络2.py
D:\Anaconda3\lib\site-packages\sklearn\feature_extraction\text.py:17: DeprecationWarning: Using or importing the ABCs from ‘collections’ instead of from ‘collections.abc’ is deprecated, and in 3.8 it will stop working
from collections import Mapping, defaultdict
num_iter:0,loss:3.063194
num_iter:1,loss:2.239954
num_iter:2,loss:1.693593
num_iter:3,loss:1.551304
num_iter:4,loss:1.506748
num_iter:5,loss:1.479147
num_iter:6,loss:1.457542
num_iter:7,loss:1.438619
num_iter:8,loss:1.421467
num_iter:9,loss:1.405498
num_iter:10,loss:1.390019
num_iter:11,loss:1.375111
num_iter:12,loss:1.360902
num_iter:13,loss:1.347246
num_iter:14,loss:1.333915
num_iter:15,loss:1.321025
num_iter:16,loss:1.308455
num_iter:17,loss:1.296189
num_iter:18,loss:1.284267
num_iter:19,loss:1.272691
num_iter:20,loss:1.261426
num_iter:21,loss:1.250217
num_iter:22,loss:1.239248
num_iter:23,loss:1.228504
num_iter:24,loss:1.217936
num_iter:25,loss:1.207321
num_iter:26,loss:1.196690
num_iter:27,loss:1.186266
num_iter:28,loss:1.176033
num_iter:29,loss:1.165851
num_iter:30,loss:1.155603
num_iter:31,loss:1.145506
num_iter:32,loss:1.135513
num_iter:33,loss:1.125471
num_iter:34,loss:1.115541
num_iter:35,loss:1.105662
num_iter:36,loss:1.095764
num_iter:37,loss:1.085812
num_iter:38,loss:1.075536
num_iter:39,loss:1.064804
num_iter:40,loss:1.053329
num_iter:41,loss:1.042024
num_iter:42,loss:1.030859
num_iter:43,loss:1.019773
num_iter:44,loss:1.008787
num_iter:45,loss:0.997435
num_iter:46,loss:0.985707
num_iter:47,loss:0.973916
num_iter:48,loss:0.962310
num_iter:49,loss:0.950888
num_iter:50,loss:0.939652
num_iter:51,loss:0.928598
num_iter:52,loss:0.917294
num_iter:53,loss:0.905565
num_iter:54,loss:0.893416
num_iter:55,loss:0.881281
num_iter:56,loss:0.869301
num_iter:57,loss:0.856783
num_iter:58,loss:0.844534
num_iter:59,loss:0.832546
num_iter:60,loss:0.820826
num_iter:61,loss:0.809372
num_iter:62,loss:0.798184
num_iter:63,loss:0.787256
num_iter:64,loss:0.776585
num_iter:65,loss:0.766098
num_iter:66,loss:0.755540
num_iter:67,loss:0.745238
num_iter:68,loss:0.735184
num_iter:69,loss:0.725355
num_iter:70,loss:0.715305
num_iter:71,loss:0.705144
num_iter:72,loss:0.694819
num_iter:73,loss:0.684792
num_iter:74,loss:0.674848
num_iter:75,loss:0.663907
num_iter:76,loss:0.653278
num_iter:77,loss:0.642616
num_iter:78,loss:0.632334
num_iter:79,loss:0.621853
num_iter:80,loss:0.611735
num_iter:81,loss:0.601942
num_iter:82,loss:0.592096
num_iter:83,loss:0.582128
num_iter:84,loss:0.571898
num_iter:85,loss:0.562073
num_iter:86,loss:0.552639
num_iter:87,loss:0.543344
num_iter:88,loss:0.533303
num_iter:89,loss:0.523705
num_iter:90,loss:0.514535
num_iter:91,loss:0.505754
num_iter:92,loss:0.497341
num_iter:93,loss:0.489270
num_iter:94,loss:0.481526
num_iter:95,loss:0.474088
num_iter:96,loss:0.466942
num_iter:97,loss:0.460070
num_iter:98,loss:0.453469
num_iter:99,loss:0.447136
num_iter:100,loss:0.441093
num_iter:101,loss:0.435259
num_iter:102,loss:0.429630
num_iter:103,loss:0.424196
num_iter:104,loss:0.418948
num_iter:105,loss:0.413882
num_iter:106,loss:0.408978
num_iter:107,loss:0.404225
num_iter:108,loss:0.399610
num_iter:109,loss:0.395138
num_iter:110,loss:0.390805
num_iter:111,loss:0.386602
num_iter:112,loss:0.382522
num_iter:113,loss:0.378551
num_iter:114,loss:0.374696
num_iter:115,loss:0.370963
num_iter:116,loss:0.367340
num_iter:117,loss:0.363815
num_iter:118,loss:0.360384
num_iter:119,loss:0.357042
num_iter:120,loss:0.353787
num_iter:121,loss:0.350614
num_iter:122,loss:0.347520
num_iter:123,loss:0.344501
num_iter:124,loss:0.341556
num_iter:125,loss:0.338681
num_iter:126,loss:0.335875
num_iter:127,loss:0.333134
num_iter:128,loss:0.330454
num_iter:129,loss:0.327833
num_iter:130,loss:0.325271
num_iter:131,loss:0.322764
num_iter:132,loss:0.320311
num_iter:133,loss:0.317910
num_iter:134,loss:0.315559
num_iter:135,loss:0.313258
num_iter:136,loss:0.311011
num_iter:137,loss:0.308808
num_iter:138,loss:0.306650
num_iter:139,loss:0.304540
num_iter:140,loss:0.302480
num_iter:141,loss:0.300460
num_iter:142,loss:0.298477
num_iter:143,loss:0.296532
num_iter:144,loss:0.294622
num_iter:145,loss:0.292750
num_iter:146,loss:0.290911
num_iter:147,loss:0.289105
num_iter:148,loss:0.287329
num_iter:149,loss:0.285582
num_iter:150,loss:0.283865
num_iter:151,loss:0.282178
num_iter:152,loss:0.280516
num_iter:153,loss:0.278883
num_iter:154,loss:0.277277
num_iter:155,loss:0.275697
num_iter:156,loss:0.274143
num_iter:157,loss:0.272618
num_iter:158,loss:0.271122
num_iter:159,loss:0.269649
num_iter:160,loss:0.268201
num_iter:161,loss:0.266775
num_iter:162,loss:0.265371
num_iter:163,loss:0.263989
num_iter:164,loss:0.262628
num_iter:165,loss:0.261287
num_iter:166,loss:0.259967
num_iter:167,loss:0.258667
num_iter:168,loss:0.257390
num_iter:169,loss:0.256131
num_iter:170,loss:0.254891
num_iter:171,loss:0.253670
num_iter:172,loss:0.252466
num_iter:173,loss:0.251280
num_iter:174,loss:0.250111
num_iter:175,loss:0.248958
num_iter:176,loss:0.247820
num_iter:177,loss:0.246698
num_iter:178,loss:0.245592
num_iter:179,loss:0.244501
num_iter:180,loss:0.243424
num_iter:181,loss:0.242362
num_iter:182,loss:0.241314
num_iter:183,loss:0.240280
num_iter:184,loss:0.239259
num_iter:185,loss:0.238252
num_iter:186,loss:0.237258
num_iter:187,loss:0.236277
num_iter:188,loss:0.235308
num_iter:189,loss:0.234352
num_iter:190,loss:0.233439
num_iter:191,loss:0.232550
num_iter:192,loss:0.231672
num_iter:193,loss:0.230794
num_iter:194,loss:0.229951
num_iter:195,loss:0.229083
num_iter:196,loss:0.228270
num_iter:197,loss:0.227416
num_iter:198,loss:0.226632
num_iter:199,loss:0.225797
训练完成
测试集正确率为:100.000%
Process finished with exit code 0
希望可以帮助到大家~~