在文件存储系统中,会使用到B树来进行存储,为什么要这样做?这样做的原因是什么?
如果我们在很多数据中去查询一条数据,逐一进行比较是最容易想到的办法,逐一进行比较的算法时间复杂度是O(n),似乎是慢了点。这时我们就想到了AVL树,这种数据结构的搜索时间复杂度是O(logn),也就是说对数据进行排序,然后使用二分搜索的思路进行查找,时间复杂度当然就是O(logn),那么使用AVL树就可以了,为什么要引进B树,先来了解一下B树
首先,B树也是一棵二叉搜索树,只不过是m阶搜索树,有以下几个性质:
1.树中的每个节点最多有m个孩子
2.除根节点和叶子节点的节点孩子数至少为ceil(m-1)
3.除根节点外的关键字数至少为 ceil(m-1)-1<=关键字<=m-1
注:ceil为取上限函数
刚看到这几个特点,或许不明白为什么孩子数和关键字数至少这么多,我们先来看看B树的插入操作,然后再来进行解释
B树的插入
举例说明,在5阶B树种插入一组字母:
C N G A H E K Q M F W L T Z D P R X Y S
注意,插入同样需要遵循搜索二叉树的性质,小的在左边,大的在右边,插入前5个
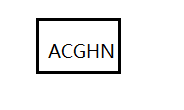
由于是5阶,节点的关键字最多为4,所以需要向上分裂,即把G提上去,AC和HN分别为左右孩子
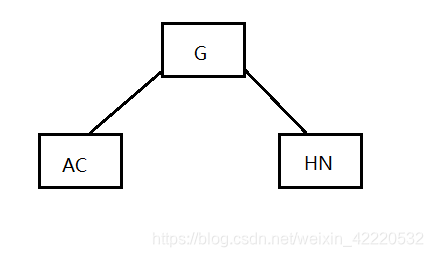
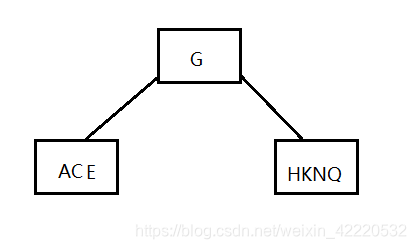
插入E,K,N,找到合适的位置,如下图:
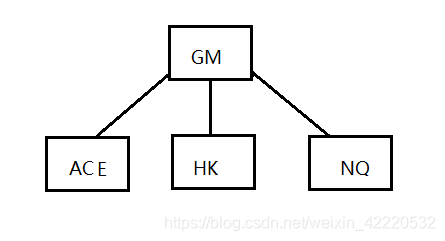
插入M时,发现插入的节点已经满足了5个,这时对该节点向上分裂
找到相应的位置,插入F,W,L,T
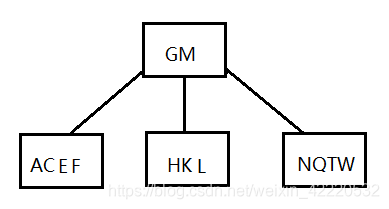
插入Z,发现插入的节点后为NQTWZ,已经满足了5个,所以需要向上分裂,如下图
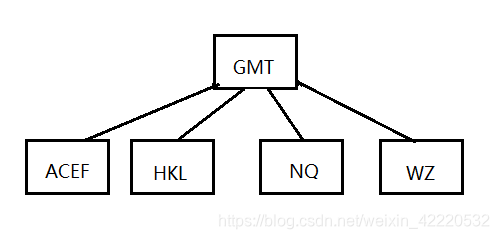
插入D,当前节点为ACDEF,需要向上分裂,分裂后如下图:
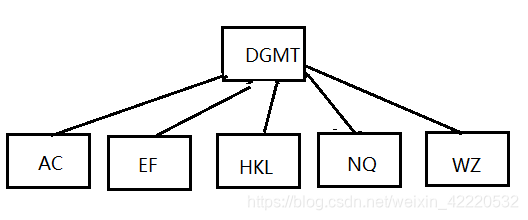
插入P,R,X,Y
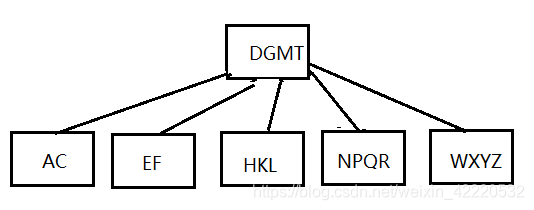
插入S,当前节点变为NPQRS,Q向上分裂,分裂完如下图:
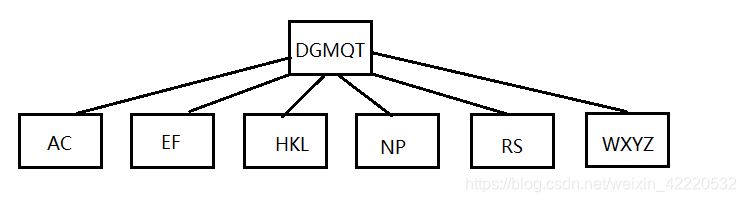
这时发现根节点已经5个了,DGMQT,需要继续分裂,把M提上去
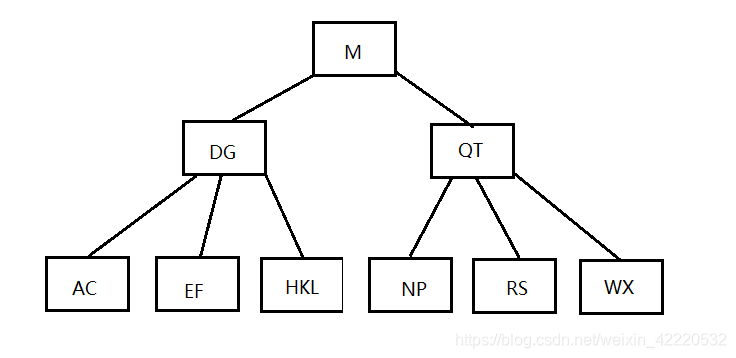
这样就完成了M的插入,后面的就不在继续画图了,到这里我们也就明白了B树是绝对平衡的,正是由于他向上分裂的结果。总结一下节点的插入过程,当插入的节点没有满的时候,直接插入到当前节点中,当插入的节点满了以后,当前节点就需要向上分裂,分裂后父节点相当于插入了一个新的关键字,如果未满,则直接插入,如果满了,则继续向上迭代。
在这里解释一下B树第二,三条性质。当向上分裂时,关键字首先会减一,也就是向上分裂了,然后分一半就是节点的关键字至少多少,如果原来节点的关键字个数是m个,分裂后为(m-1)/2,这里是取下限,如果改为取上限,就是ceil(m/2)-1,两者结果完全相同。如果关键字个数至少为ceil(m/2)-1,那么孩子数就比关键字个数多1,即ceil(m/2)
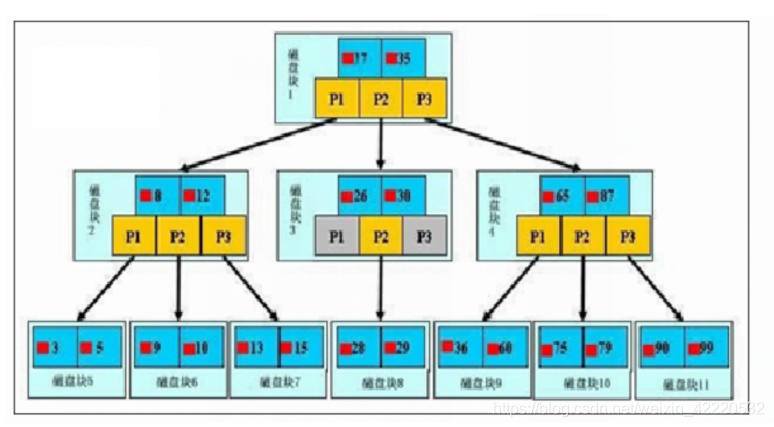
上图是B树的图,蓝色表示关键字,黄色表示孩子,而红色则是与关键字进行绑定的数据行,现在来解释一下为什么AVL可以完成的事情,为什么需要B树来完成:
在每一次比对查询是否正确的时候,因为数据量大,都是存在于磁盘上的,所以每次调取数据都需要完成一次磁盘IO,在操作系统层面来讲,内存中是以页为单位,磁盘是以块为单位,不论每次进行磁盘IO的数据量大小,最小都要以一个数据块为单位,这就造成了浪费,B树的高度会非常低,也就是说高度为几,则需要进行几次磁盘IO,真实环境中有可能时几百阶的B树,这样就保证了一次磁盘IO会充分利用好一个单位块数据。总结来说,采用B树,而不是AVL树,就是为了减少磁盘IO的次数,减少浪费。
但是在实际过程中,采用的是B+树,是B树的进化版,B+树如下图所示:
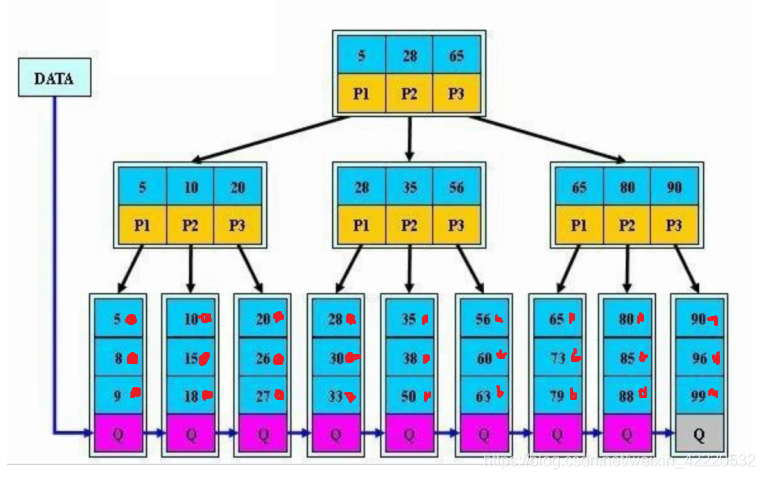
同样,蓝色是关键字,黄色是孩子,红色是与关键字绑定的数据行,会发现B+树有几个与B树不同的特点:
- 数据都出现在叶子节点,所以拿到数据的时间是相同的。树干节点就是用于搜索
- 有一个链表串起了整张数据表,这样更利于范围查询
那么B+树相对于B树的查询优势有以下三点:
- 由于非叶子节点的关键字只用于搜索,不存储数据行地址,那么同一个块中能容纳的关键字就越多,树的高度就越矮,查询的效率就越高
- 由于数据行地址都是在叶子节点中,所以查询的时间比较稳定
- 由于链表指针的存在,所以更利于范围查询
