1.B+树索引
1.1不同应用中B+树索引的使用
OLTP:查询操作只从数据库中取得一小部分的数据,一般可能都在10条记录以下,或者1条记录
是建立B+树索引最有意义的,否则即使建立了,优化器可能选择不使用索引。
OLAP:需要访问表中大量的数据 根据这些数据来产生查询结果,这些查询多是面向分析查询,并提供给决策者。对于OLAP复杂查询,要涉及多张表之间的连接,索引添加依然有意义。 但是Hash JOIN 索引变得不重要了,在OLAP需要对时间字段进行索引
1.2联合索引
- 联合索引使用情况:
**联合索引键值>=2 **
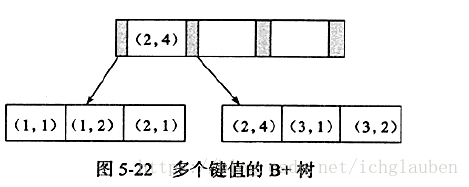
数据按照(a,b)的顺序进行了存放 如上图。
用SELECT * FROM TABLE WHERE a=xxxx and b=xxxx 可以使用(a,b)这个联合索引。
已经对第二个键值进行了排序处理
联合索引(a,b)其实根据列a,b进行排序 下列语句可以直接使用联合索引得到:
select … from table where a=xxx order by b
然鹅对于(a,b,c)同样可以直接通过联合索引得到结果:
SELECT … FROM TABLE WHERE a=xxx ORDER BY b
SELECT … FROM TABLE WHERE a=xxx AND b=xxx ORDER BY c
1.3覆盖索引
InnoDB存储引擎支持覆盖索引(Covering index 索引覆盖) 从辅助索引中得到查询的记录,不需要查询聚集索引的记录。
-
好处: 辅助索引不包含整行记录的所有信息,故其大小远小于聚集索引 可以减少大量的IO操作
-
好处2:对于统计问题
SELECT COUNT(*) FROM TABLE
InnoDB引擎不会选择查询聚集索引进行统计 而是选择辅助索引(数量小 减少IO操作)


1.4优化器选择不使用索引的情况
当执行EXPLAIN命令进行SQL语句分析,优化器并没有选择索引去查找数据,而是通过聚集索引(扫描全表得到数据) 发生于范围查找,JOIN链接操作等情况。
例子:

该表中(OrderID,ProductID)的联合主键,此处还有对于OrderID的单个索引。上述SQL本可以通过OrderID上索引进行数据查找。结果却是走的主键。

在possible_keys一列可以看到查询使用PRIMARY OrdersOrder_Details三个索引,在最后的索引使用中,优化器选择了PRIMARY聚集索引
- 原因:用户要选取的数据是整行信息,而OrderID索引不能覆盖我们要查询信息,因此在对OrderID索引查询到指定数据后,还需要一次书签访问查找整行数据信息。(OrderID索引中数据顺序存放 再次进行书签查找的数据无序 变成离散读操作 若要求访问数据量很小 则优化器会选择辅助索引 但访问数据占整个表中数据的蛮大部分时 优化器通过聚集索引找数据)
不能进行索引覆盖的情况,优化器选择辅助索引的情况是:通过辅助索引查找的数据量是少量的。
若使用固态硬盘,随机读操作非常快,确定辅助索引可以带来更好的性能,可以使用关键字FORCE INDEX来强制使用某个索引。
SELECT * FROM orderdetails FORCE INDEX(OrderID) WHERE orderid>10000 and orderid<10200
1.5索引提示
MySQL数据库支持索引提示(INDEX HINT)


Multi-Range Read优化(MRR)
MRR优化的好处:
- MRR使数据访问变顺序。查询辅助索引 先根据得到的查询结果 按照主键进行排序 按照主键排序的顺序进行书签查找
- 减少缓冲池页被替换的次数 提高命中率了
- 批量处理对键值查询的操作 数量大
MRR工作方式
- 将查询的辅助索引键值放入一个缓存中,缓存数据是根据辅助索引键值排序的
- 将缓存的键值根据RowID进行排序
- 根据RowID排序访问实际的数据文件
会提升不小的性能

1.6Index Condition Pushdown(ICP)优化
有无ICP区别:在取出索引的同时 判断是否可以进行where条件过滤。 有了ICP 大大减少上层SQL层对记录的索取(fetch) 从而提高数据库的整体性能。
2 哈希算法
-
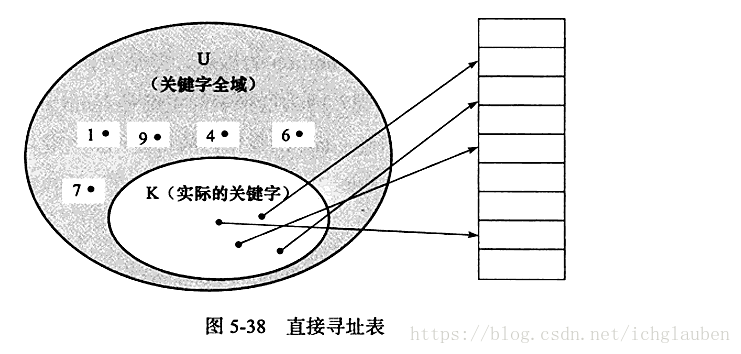
介绍:称为散列表 由直接寻址表改进而来。
-
依据hash算法 计算出映射的槽位 并用链表发来解决插入槽位多值问题、
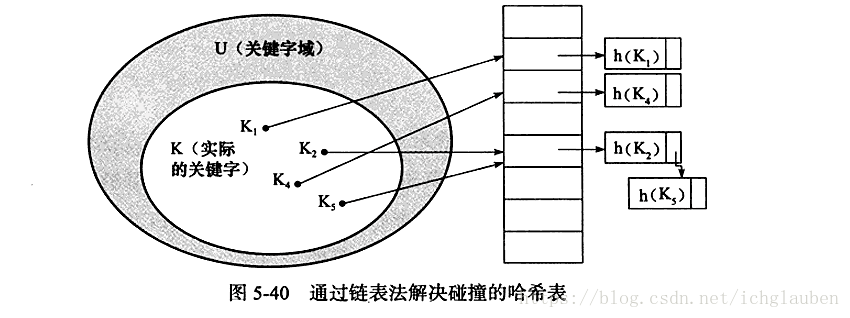
2.1hash算法
复杂度O(1)
缓冲池页的哈希表中,在缓冲池中的Page页都有一个chain指针 指向相同哈希函数值的页
- 例子
innodb_buffer_pool_size = 10M = 10 * 1024 * 1024 = 16 1K * 640
对缓冲页中hash表来说 需要分配6402 = 1280个槽 但是要比1280大的质数 取1399