摘要:
GBDT-分类
GBDT-回归
前面两篇文章已经详细介绍了在回归和分类下的GBDT算法。这一篇文章将最后介绍一个多分类任务的GBDT。其过程和二分类的GBDT类似,但是有一个地方有很大的不同,下文将详细的介绍。
正文:
下图是Friedman在论文中对GBDT多分类给出的伪代码:

从代码上看,大致和分类时候的过程一样。最大的不同点在于多了一层内部的循环For。
这里需要注意的是:
1.对于多分类任务,GDBT的做法是采用一对多的策略(详情见文章)。
也就是说,对每个类别训练M个分类器。假设有K个类别,那么训练完之后总共有M*K颗树。
2.两层循环的顺序不能改变。也就是说,K个类别都拟合完第一颗树之后才开始拟合第二颗树,不允许先把某一个类别的M颗树学习完,再学习另外一个类别。
算法6使用的是多分类常用的损失函数:
其中
(softmax)
对损失函数求一阶导有:
。
叶子节点的更新值为:
下面以一个简单的数据集说明整个GBDT的流程。
| 6 | 12 | 14 | 18 | 20 | 65 | 31 | 40 | 1 | 2 | 100 | 101 | 65 | 54 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 2 | 2 | 2 | 2 |
由于我们需要转化3个二分类的问题,所以需要先做一步one-hot:
| 6 | 12 | 14 | 18 | 20 | 65 | 31 | 40 | 1 | 2 | 100 | 101 | 65 | 54 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 2 | 2 | 2 | 2 | |
| 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 |
为了方便说明,作以下设置:
1. 树的深度为1
2. 学习率1
首先进行初始化
,对所有的样本。
注意:在Friedman论文里全部初始化为0,但在sklearn里是初始化先验概率(就是各类别的占比)
对第一个类别( )拟合第一颗树 。
| 6 | 12 | 14 | 18 | 20 | 65 | 31 | 40 | 1 | 2 | 100 | 101 | 65 | 54 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
利用
| 6 | 12 | 14 | 18 | 20 | 65 | 31 | 40 | 1 | 2 | 100 | 101 | 65 | 54 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0.3333 | 0.3333 | 0.3333 | 0.3333 | 0.3333 | 0.3333 | 0.3333 | 0.3333 | 0.3333 | 0.3333 | 0.3333 | 0.3333 | 0.3333 | 0.3333 |
下面计算负梯度值,以
为例
:
=>
同样地,计算其他样本可以有下表:
| 6 | 12 | 14 | 18 | 20 | 65 | 31 | 40 | 1 | 2 | 100 | 101 | 65 | 54 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0.6667 | 0.6667 | 0.6667 | 0.6667 | 0.6667 | -0.3333 | -0.3333 | -0.3333 | -0.3333 | -0.3333 | -0.3333 | -0.3333 | -0.3333 | -0.3333 |
以
拟合一颗回归树,(以31为分裂点)
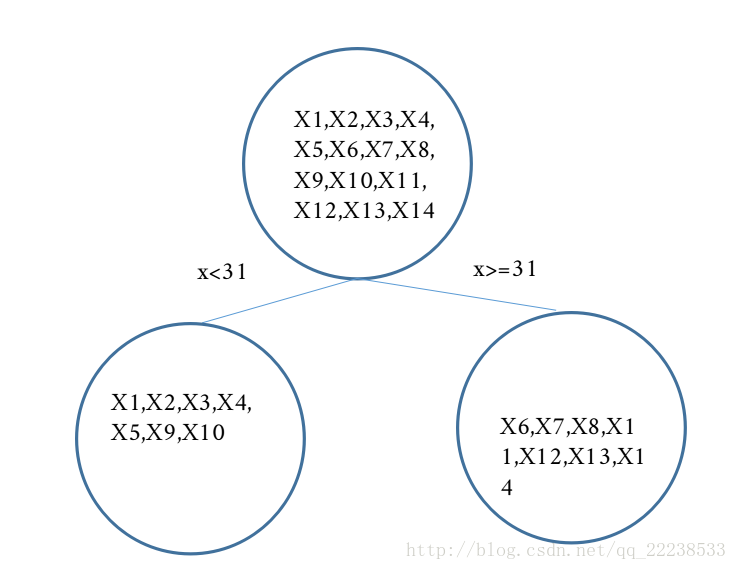
这里简单补充一下,为什么选择31作为分裂点。
在GBDT的建树中,可以采用如MSE,MAE等作为分裂准则来确定分裂点(启发式)。而本文采用的分裂准则是MSE,具体计算过程如下。
遍历所有特征的取值,将每个特征值依次作为的分裂点,然后计算左子结点与右子结点上的MSE,寻找两者加和最小的一个。
比如,选择1作为分裂点时(x<1)。
左子结点上的集合的MSE为:
右子节点上的集合的MSE为:
故总的MSE为:
比如选择2作为分裂点时(x<2)。
计算完后可以发现,当选择31做为分裂点时,可以得到最小的MSE,
和前面文章类似,分别计算
可得:
,
更新 可得下表:
| 6 | 12 | 14 | 18 | 20 | 65 | 31 | 40 | 1 | 2 | 100 | 101 | 65 | 54 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1.1428 | 1.1428 | 1.1428 | 1.1428 | 1.1428 | -0.999 | -0.999 | -0.999 | 1.1428 | 1.1428 | -0.999 | -0.999 | -0.999 | -0.999 |
至此第一个类别(类别0)的第一颗树拟合完毕,下面开始拟合第二个类别(类别1)的第一颗树:
对第二个类别( )拟合第一颗树 。
| 6 | 12 | 14 | 18 | 20 | 65 | 31 | 40 | 1 | 2 | 100 | 101 | 65 | 54 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 |
利用
| 6 | 12 | 14 | 18 | 20 | 65 | 31 | 40 | 1 | 2 | 100 | 101 | 65 | 54 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0.3333 | 0.3333 | 0.3333 | 0.3333 | 0.3333 | 0.3333 | 0.3333 | 0.3333 | 0.3333 | 0.3333 | 0.3333 | 0.3333 | 0.3333 | 0.3333 |
下面计算负梯度值,以
为例
:
=>
同样地,计算其他样本可以有下表:
| 6 | 12 | 14 | 18 | 20 | 65 | 31 | 40 | 1 | 2 | 100 | 101 | 65 | 54 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| -0.3333 | -0.3333 | -0.3333 | -0.3333 | -0.3333 | 0.6667 | 0.6667 | 0.6667 | 0.6667 | 0.6667 | -0.3333 | -0.3333 | -0.3333 | -0.3333 |
以
拟合一颗回归树,(以6为分裂点),可计算得到叶子节点:
,
更新
可得下表:
| 6 | 12 | 14 | 18 | 20 | 65 | 31 | 40 | 1 | 2 | 100 | 101 | 65 | 54 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| -0.2499 | -0.2499 | -0.2499 | -0.2499 | -0.2499 | -0.2499 | -0.2499 | -0.2499 | 2 | 2 | -0.2499 | -0.2499 | -0.2499 | -0.2499 |
然后再拟合第三个类别(类别2)的第一颗树,过程也是重复上述步骤,所以这里就不再重复了。在拟合完所有类别的第一颗树后就开始拟合第二颗树。反复进行,直到训练了M轮。
总结
至此,GBDT回归与分类就完整的说了一遍了。在多分类里面不打算分析Sklearn源码是因为其实现和Frieman论文里面步骤有一点不太一样。
————————
感谢网友们对本文的阅读以及宝贵的意见!特别感谢网友@guo15996278092提出的宝贵意见!