一、概述
学校安排的大数据实训课程刚结束,当时是跟着老师傻瓜式搭建的,遇到问题大多也是他帮忙解决的。然后自己开始学习一个电商项目,里面用到了集群的知识,于是得自己搭建一个集群,便于项目开发。至于他们的作用就不多少了,直接开始吧
二、安装前环境准备
集群规划:(安装集群之前,先规划下集群,考虑配置,ip,内存硬盘,cpu)
主机名 IP运行的进程
liquanhong1 192.168.0.1 NameNode、JournalNode、DFSZKFailoverController(zkfc)、ResourceManager、JournalNode、QuorumPeerMain、DataNode,NodeManager
主机名 IP运行的进程
liquanhong1 192.168.0.1 NameNode、JournalNode、DFSZKFailoverController(zkfc)、ResourceManager、JournalNode、QuorumPeerMain、DataNode,NodeManager
liquanhong2 192.168.0.2 NameNode、JournalNode、DFSZKFailoverController(zkfc)、ResourceManager、JournalNode、QuorumPeerMain、DataNode,NodeManager
liquanhong3 192.168.0.3 DataNode、JournalNode、QuorumPeerMain
说明:
①在hadoop2.0中通常由两个NameNode组成,一个处于active状态,另一个处于standby状态。Active NameNode对外提供服务,而Standby NameNode则不对外提供服务,仅同步active namenode的状态,以便能够在它失败时快速进行切换。
hadoop2.0官方提供了两种HDFS HA的解决方案,一种是NFS,另一种是QJM。这里我们使用简单的QJM。在该方案中,主备NameNode之间通过一组JournalNode同步元数据信息,一条数据只要成功写入多数JournalNode即认为写入成功。通常配置奇数个JournalNode
这里还配置了一个zookeeper集群,用于ZKFC(DFSZKFailoverController)故障转移,当Active NameNode挂掉了,会自动切换Standby NameNode为standby状态
②hadoop-2.2.0中依然存在一个问题,就是ResourceManager只有一个,存在单点故障,hadoop-2.4.1解决了这个问题,有两个ResourceManager,一个是Active,一个是Standby,状态由zookeeper进行协调
③datanode与nodemanager最好在一起因为nodemanager里要运行mr,可以从本地获取数据。
说明:
①在hadoop2.0中通常由两个NameNode组成,一个处于active状态,另一个处于standby状态。Active NameNode对外提供服务,而Standby NameNode则不对外提供服务,仅同步active namenode的状态,以便能够在它失败时快速进行切换。
hadoop2.0官方提供了两种HDFS HA的解决方案,一种是NFS,另一种是QJM。这里我们使用简单的QJM。在该方案中,主备NameNode之间通过一组JournalNode同步元数据信息,一条数据只要成功写入多数JournalNode即认为写入成功。通常配置奇数个JournalNode
这里还配置了一个zookeeper集群,用于ZKFC(DFSZKFailoverController)故障转移,当Active NameNode挂掉了,会自动切换Standby NameNode为standby状态
②hadoop-2.2.0中依然存在一个问题,就是ResourceManager只有一个,存在单点故障,hadoop-2.4.1解决了这个问题,有两个ResourceManager,一个是Active,一个是Standby,状态由zookeeper进行协调
③datanode与nodemanager最好在一起因为nodemanager里要运行mr,可以从本地获取数据。
1.0、VMware虚拟机
1.1、Linux系统3台,改为仅主机模式
1.2、jdk-7u65-linux-i586.tar.gz
1.3、zookeeper-3.4.9.tar.gz
1.4、hadoop-2.7.3-32.tar.gz
注意:如果linux是复制的,linux的eth0网卡不会启动,所以需要把ifcfg-eth0中的HWADDR修改<虚拟机---网络设配 器---高级中的MAC地址>,然后删除70-persistent-net.rules文件,如下图
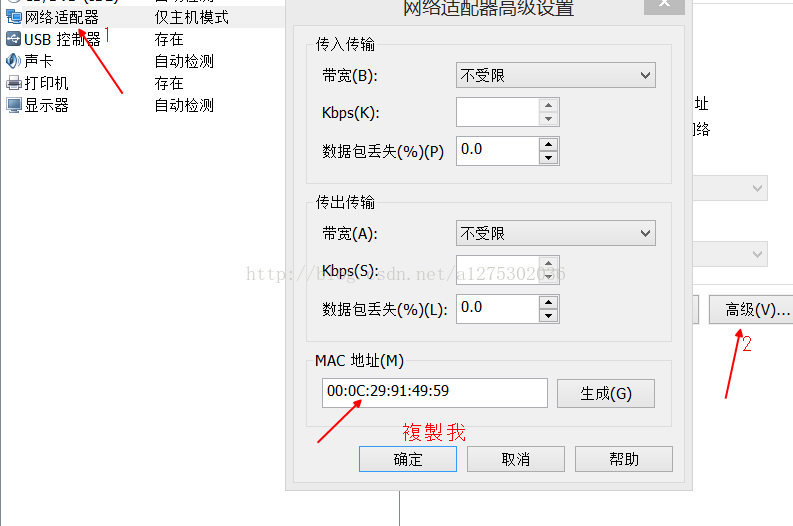
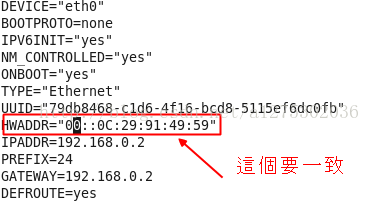
参考链接:linux复制后eth0不能启动
下面的都是以第一台为例
2.1、修改Linux主机名vim /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=liquanhong1
HOSTNAME=liquanhong1
2.2、修改IP,建议通过图形化界面修改<进入Linux图形界面 -> 右键点击右上方的两个小电脑 -> 点击 Editconnections -> 选中当前网络System eth0 -> 点击edit按钮 -> 选择IPv4 -> method选择为manual -> 点击add 按钮 -> 添加IP:192.168.0.1 子网掩码:255.255.255.0 网关:192.168.0.1 -> apply>
也可以通过vim /etc/sysconfig/network-scripts/ifcfg-eth0修改
2.3、修改主机名和IP的映射关系
vim /etc/hosts
//加在后面
192.168.0.1liquanhong1
2.4、关闭防火墙
service iptables stop
chkconfig iptables --list
下面那个是通过该配置文件关闭防火墙,相当于永久关闭
2.5、重启Linux
reboot
2.6、ssh免登录
ssh-keygen -t rsa
#将公钥拷贝到其他节点,包括自己
ssh-copy-id liquanhong1
ssh-copy-id liquanhong2
ssh-copy-id liquanhong3
#将公钥拷贝到其他节点,包括自己
ssh-copy-id liquanhong1
ssh-copy-id liquanhong2
ssh-copy-id liquanhong3
三、安装Jdk
3.1、上传到Linux
3.2、解压jdk 最好不要用jdk8
#创建文件夹
mkdir /usr/java
#解压
tar -zxvf jdk-7u55-linux-i586.tar.gz -C /usr/java/
mkdir /usr/java
#解压
tar -zxvf jdk-7u55-linux-i586.tar.gz -C /usr/java/
注意:-C中的C是大写
3.3将java添加到环境变量中
vim /etc/profile
#在文件最后添加
#刷新配置
vim /etc/profile
#在文件最后添加
export JAVA_HOME=/usr/java/jdk1.7.0_65
export PATH=$PATH:$JAVA_HOME/bin#刷新配置
source /etc/profile
3.4、拷贝到其他机器
scp -r /usr/java liquanhong2:/usr/
scp -r /usr/java liquanhong3:/usr/四、安装Zookeeper集群
4.0上傳zookeeper-3.4.9.tar.gz到linux
4.1解压
mkdir /root/zookeeper
tar -zxvf zookeeper-3.4.9.tar.gz -C /root/zookeeper
4.2修改配置
4.2.1
cd /root/zookeeper/zookeeper-3.4.9/conf/
cp zoo_sample.cfg zoo.cfg
vim zoo.cfg
①修改:dataDir=/root/zookeeper/zookeeper-3.4.9/tmp 这个下面是myid文件,必须这样
②在最后添加:
mkdir /root/zookeeper
tar -zxvf zookeeper-3.4.9.tar.gz -C /root/zookeeper
4.2修改配置
4.2.1
cd /root/zookeeper/zookeeper-3.4.9/conf/
cp zoo_sample.cfg zoo.cfg
vim zoo.cfg
①修改:dataDir=/root/zookeeper/zookeeper-3.4.9/tmp 这个下面是myid文件,必须这样
②在最后添加:
#2888端口是leader和flower之间通信的端口,3888端口是flower之间选举的端口
server.1=liquanhong1:2888:3888
server.2=liquanhong2:2888:3888
server.3=liquanhong3:2888:3888
4.2.2(myid中的值和server.1,server.2,server.3中的對應)
然后创建一个tmp文件夹 存储zookeeper产生的数据的
再创建一个空文件
最后向该文件写入ID
4.3将配置好的zookeeper拷贝到其他节点
注意:修改liquanhong2、liquanhong3对应的myid
liquanhong2:
liquanhong3:
4.4、启动zookeeper:
cd /root/zookeeper/zookeeper-3.4.9/bin
server.1=liquanhong1:2888:3888
server.2=liquanhong2:2888:3888
server.3=liquanhong3:2888:3888
4.2.2(myid中的值和server.1,server.2,server.3中的對應)
然后创建一个tmp文件夹 存储zookeeper产生的数据的
mkdir /root/zookeeper/zookeeper-3.4.9/tmp再创建一个空文件
touch /root/zookeeper/zookeeper-3.4.9/tmp/myid最后向该文件写入ID
echo 1 > /root/zookeeper/zookeeper-3.4.9/tmp/myid4.3将配置好的zookeeper拷贝到其他节点
scp -r /root/zookeeper/ liquanhong2:/root/
scp -r /root/zookeeper/ liquanhong3:/root/注意:修改liquanhong2、liquanhong3对应的myid
liquanhong2:
echo 2 > /root/zookeeper/zookeeper-3.4.9/tmp/myidliquanhong3:
echo 3 >/root/zookeeper/zookeeper-3.4.9/tmp/myid4.4、启动zookeeper:
cd /root/zookeeper/zookeeper-3.4.9/bin
./zkServer.sh start
./zkServer.sh status五、安装hadoop集群(在liquanhong1上)
5.0上传hadoop-2.7.3-32.tar.gz到Linux
5.1解压
mkdir /root/hadoop tar -zxvf hadoop-2.7.3-32.tar.gz -C /root/hadoop5.2配置HDFS(hadoop2.0所有的配置文件都在$HADOOP_HOME/etc/hadoop目录下)
#将hadoop添加到环境变量中
vim /etc/profile
export JAVA_HOME=/usr/java/jdk1.7.0_55
export HADOOP_HOME=/root/hadoop/hadoop-2.7.3-32
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin#hadoop2.0的配置文件全部在$HADOOP_HOME/etc/hadoop下
cd /root/hadoop/hadoop-2.7.3-32/etc/hadoop5.2.1vim hadoop-env.sh
export JAVA_HOME=/usr/java/jdk1.7.0_555.2.2vim core-site.xml
<configuration>
<!-- 指定hdfs的nameservice为ns1 (hadoop2.0以后,它实现了对namenode进行抽像称之为nameservice,一个nameservice有两个namenode,那这两个namenode只能有一个处于active状态,这个协调就是靠zookeeper,zookeeper能确保nameservice下有一个活跃的namenode,一旦namenode宕机了,zookeeper就会让另一个namenode成为activie)之所以抽像成一个nameservice就是因为两个是一对,一个失败,启动另外一个,访问也方便只需要访问ns1就可以,不用连接死namenode。NameNode高可靠原理看namenode高可靠原理图.png-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns1</value>
</property>
<!-- 指定hadoop临时目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/root/hadoop/hadoop-2.5.2/tmp</value>
</property>
<!-- 指定zookeeper地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>liquanhong1:2181,liquanhong2:2181,liquanhong3:2181</value>
</property>
</configuration>5.2.3vim hdfs-site.xml
<configuration>
<!--指定hdfs的nameservice为ns1,需要和core-site.xml中的保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>ns1</value>
</property>
<!-- ns1下面有两个NameNode,分别是nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.ns1</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns1.nn1</name>
<value>liquanhong1:9000</value>
</property>
<!-- nn1的http通信地址,有个管理界面用于下载文件 -->
<property>
<name>dfs.namenode.http-address.ns1.nn1</name>
<value>liquanhong1:50070</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns1.nn2</name>
<value>liquanhong2:9000</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns1.nn2</name>
<value>liquanhong2:50070</value>
</property>
<!-- 指定NameNode的元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://liquanhong1:8485;liquanhong2:8485;liquanhong3:8485/ns1</value>
</property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/root/hadoop/hadoop-2.7.3-32/journal</value>
</property>
<!-- 开启NameNode失败自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方式,通过ConfiguredFailoverProxyProvider这个类实现自动切换 -->
<property>
<name>dfs.client.failover.proxy.provider.ns1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制方法,多个机制用换行分割,即每个机制暂用一行,隔离机制sshfence的意思是:当一个namenode坏了,但还没有宕机,这样的话还处于active状态,为让另一个namenode正常成为active,另外一个namenode会向坏掉的 namenode发一个命令把它杀掉。shell(/bin/true)的意思是:如果active节点,完全宕机,那zkfc就不能汇报信息了,这样,standby很长时间收不到消息,当收不到消息时,standby就启动一个脚本,如果这个脚本返回true,就会变成active-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<!-- 使用sshfence隔离机制时需要ssh免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/hadoop/.ssh/id_rsa</value>
</property>
<!-- 配置sshfence隔离机制超时时间(active坏了之后,standby如果没有在30秒之内未连接上,那么standby将变成active) -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>5.2.4vim mapred-site.xml
<configuration>
<!-- 指定mr框架为yarn方式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<!--map运行时堆内存(可选)-->
<name>yarn.odemanager.resource.memory-mb</name>
<value>-Xmx8192m</value>
</property>
<!--map运行时堆内存(可选)-->
<property>
<name>mapred.child.java.opts</name>
<value>-Xmx400m</value>
</property>
</configuration>5.2.5vim yarn-site.xml
<configuration>
<!-- 开启RM高可靠 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定RM的cluster id -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yrc</value>
</property>
<!-- 指定RM的名字 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 分别指定RM的地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>liquanhong1</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>liquanhong2</value>
</property>
<!-- 指定zk集群地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>liquanhong1:2181,liquanhong2:2181,liquanhong3:2181</value>
</property>
<!--reduce获取数据时通过shuffle方式-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>5.2.6修改slaves(slaves是指定子节点的位置,因为要在liquanhong1上启动HDFS、在liquanhong1启动yarn,所 以liquanhong1上的slaves文件指定的是datanode的位置,liquanhong1上的slaves文件指定的是nodemanager的 位置)
liquanhong1
liquanhong2
liquanhong35.2.7配置免密码登陆
#首先要配置liquanhong1到liquanhong2,liquanhong3的免密码登陆
#在liquanhong1上生产一对钥匙
ssh-keygen -t rsa#将公钥拷贝到其他节点,包括自己
ssh-copy-id liquanhong1
ssh-copy-id liquanhong2
ssh-coyp-id liquanhong3 #注意:两个namenode之间要配置ssh免密码登陆,别忘了配置itcast02到itcast01的免登陆
在liquanhong2上生产一对钥匙
ssh-keygen -t rsa
ssh-coyp-id -i liquanhong1 5.3将配置好的hadoop拷贝到其他节点
scp -r /root/hadoop/ liquanhong2:/root/
scp -r /root/hadoop/ liquanhong3:/root/5.4启动zookeeper集群(分别在3台机器上启动zk)
cd /root/zookeeper/zookeeper-3.4.9/bin/
./zkServer.sh start#查看状态:一个leader,两个follower
./zkServer.sh status5.5启动journalnode(分别在在3台机器上执行)
cd /root/hadoop/hadoop-2.7.3-32
sbin/hadoop-daemons.sh start journalnode若在/etc/profile配置了$HADOOP_HOME/sbin则可以直接启动命令
5.6格式化HDFS
#格式化后会在根据core-site.xml中的hadoop.tmp.dir配置生成个文件,我配置的是/root/hadoop/hadoop-2.7.3-32/tmp
hdfs namenode -format然后将/root/hadoop/hadoop-2.7.3-32/tmp拷贝到其他机器下。
scp -r tmp/ liquanhong2:/root/hadoop/5.7格式化ZK(在liquanhong1上执行即可,若不能启动结点再在其他机器上执行)
作用:协助namenode进行高可靠,向zookeeper汇报
hdfs zkfc -formatZK 5.8 启动zk
hadoop-daemon.sh start zkfc5.9启动HDFS(在liquanhong1上执行)
start-dfs.sh 5.10启动YARN(是在liquanhong1上执行start-yarn.sh,把namenode和resourcemanager分开是因为性能问题,因为他们都要占用大量资源,所以把他们分开了,他们分开了就要分别在不同的机器上启动)
start-yarn.sh注意:需要严格按照上面的步骤启动,关闭顺序则相反
最后,若出现下图所示节点信息,则说明搭建成功
2662 QuorumPeerMain
23256 ResourceManager
23375 NodeManager
22994 NameNode
22919 DFSZKFailoverController
2770 JournalNode
23135 DataNode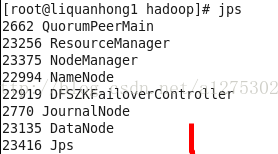
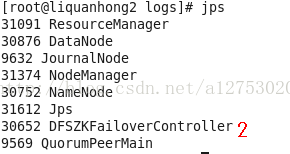
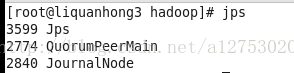
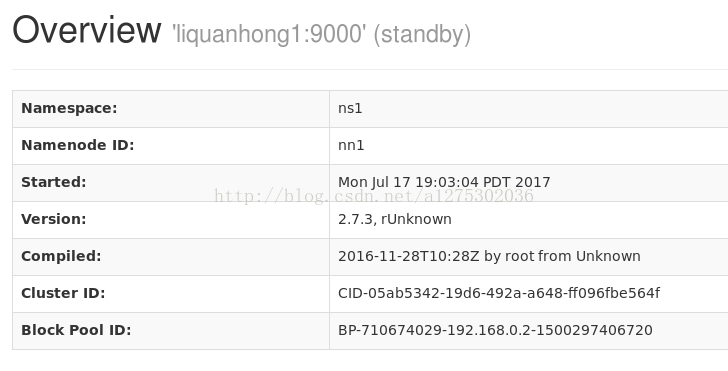
ok,大功告成,hadoop-2.7.3配置完毕,可以统计浏览器访问:
http://192.168.0.1:50070
NameNode 'liquanhong1:9000' (active)
http://192.168.0.2:50070
NameNode 'liquanhong2:9000' (standby)
************************下面是简略启动命令及顺序*****************************************
./zkServer.sh start
hadoop-daemon.sh start journalnode
hadoop-daemon.sh start zkfc
start-dfs.sh
start-yarn.sh注意:每执行一个命令需要用jps查看一下相关结点有没有起来
附:浏览器访问图:

六、总结
里面
的配置文件都是复制老师给的,网上也有很多几乎一样的( ),由于以前没有接触过大数据,很多配置文件都不知道是啥意思,
),由于以前没有接触过大数据,很多配置文件都不知道是啥意思,
),由于以前没有接触过大数据,很多配置文件都不知道是啥意思,
其实只要配置文件写对了,集群肯定能搭建成。本人比较糟糕,搞了两次才成。这个过程错误再说难免,列举
一些碰到的错误。
6.1、hadoop的编译版本要和linux系统版本一致,若不一致会报
Java HotSpot(TM) 64-Bit Server VM warning:You have loaded library /root/hadoop/hadoop-2.7.3-32/lib/native/libhadoop.so which might have disabled stack guard. The VM will try to fix the stack guard now类似的错误
当时是因为linux是32位,而hadoop编译版本是64位
6.2、配置文件一定要写对,一定要写对,一定要写对!
重要事情说三遍
当时配置时,由于
<!-- 指定hadoop临时目录 -->
<property> <name>hadoop.tmp.dir</name> value>/root/hadoop/hadoop-2.5.2/tmp</value>
</property>
6.3、启动start-dfs.sh命令时,提示command not found
这是环境变量中${HADOOP_HOME}/bin没配置
6.4、Could not resolve hostname that: Temporary failure in name resolution or: ssh: Could not resolve hostname or: Temporary failure in name resolution with: ssh: Cou
这个也是环境变量没有配置好
这个也是环境变量没有配置好
vim /etc/profile中加入以下語句
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
source /etc/profile
这是hdfs zkfc -formatZK写错了,formatZK不能分开
6.6、虚拟机启动时报下面的错误
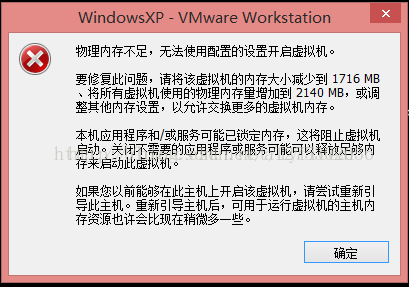
网上说了很多种解决方法,最后的解决方法时把Vmware升级至10.0.4以上,
这是10.0.4会对win8.1操作系统内存误报(大概意思)
6.7、第一次启动dfs、zkfc时别忘了格式化
主要就是这些问题了吧,还有的问题没想起来了。有错误的地方请指正。
搭建的时候细心点,调错误的时候耐心点,集群也并没那么难!
就写这么多吧,转载请注明出处,谢谢!
,谢谢!
