一.准备:
1. 安装centos7并卸载自带的OpenJDK(centos7的安装教程在上一篇):
1.1 通过 rpm -qa | grep java 命令查询系统自带的jdk(带箭头的2个就是系统自带的)

1.2 通过 rpm -e --nodeps+后面跟系统自带的jdk名 这个命令来删除系统自带的jdk,例如:
# rpm -e --nodeps java-1.8.0-openjdk-headless-1.8.0.102-4.b14.el7.x86_64
# rpm -e --nodeps java-1.8.0-openjdk-1.8.0.102-4.b14.el7.x86_64
执行后再执行 rpm -qa | grep java 命令会发现已经删除了。

2.克隆另外两台虚拟机
2.1 这里选择克隆
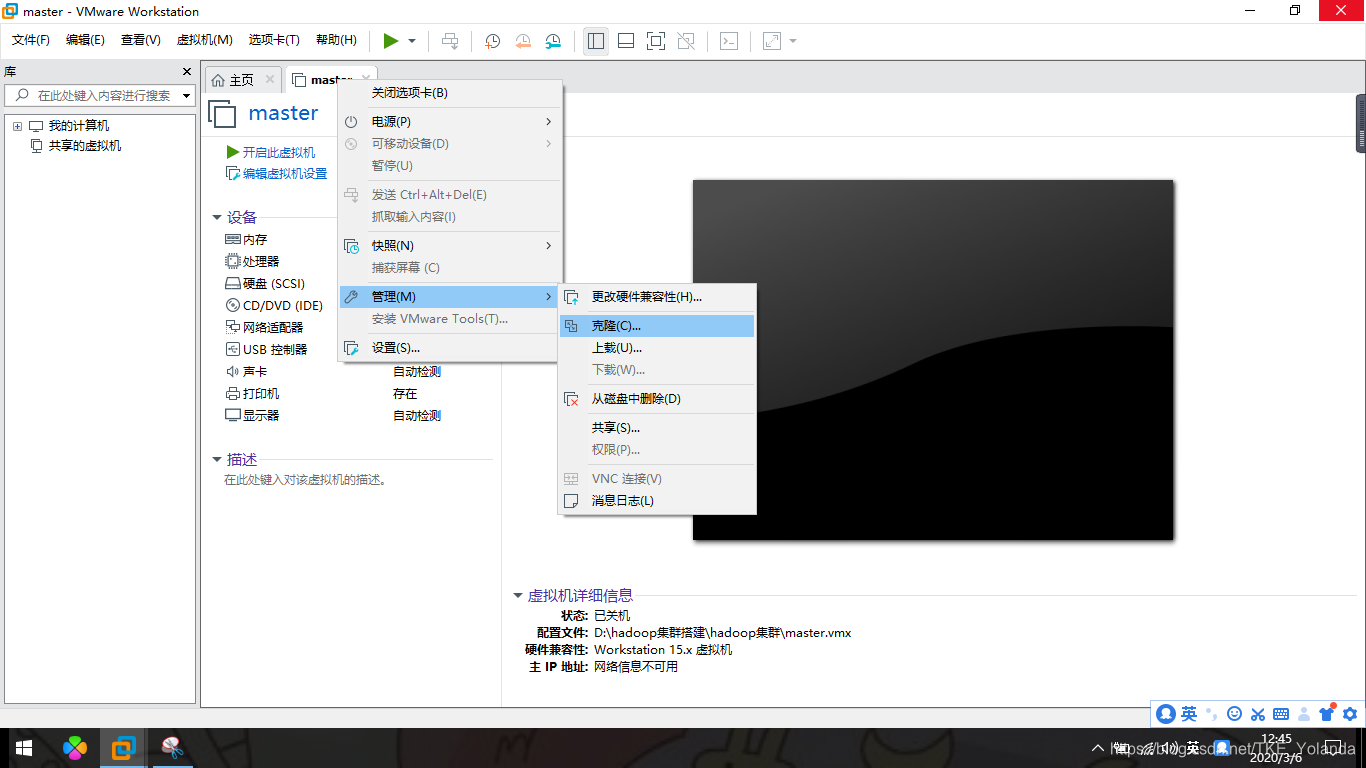
2.2 点击下一步。
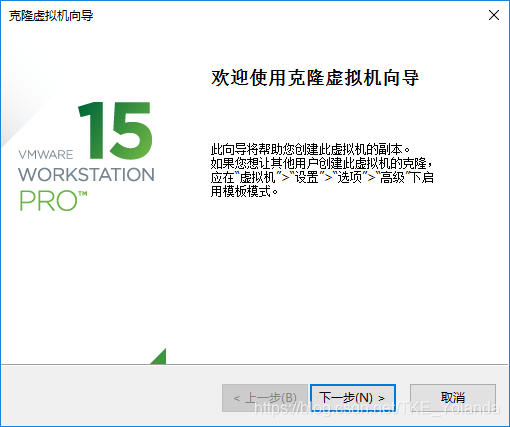
2.3 下一步
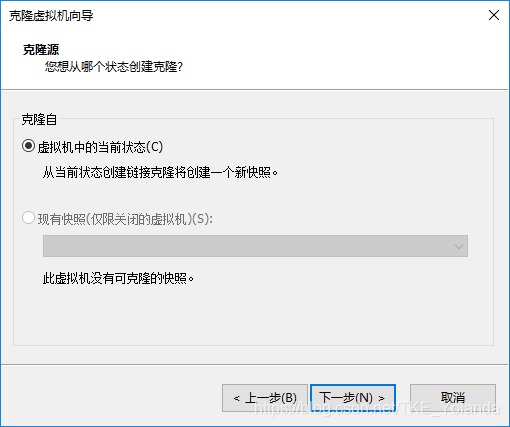
2.4 选择创建完整克隆。
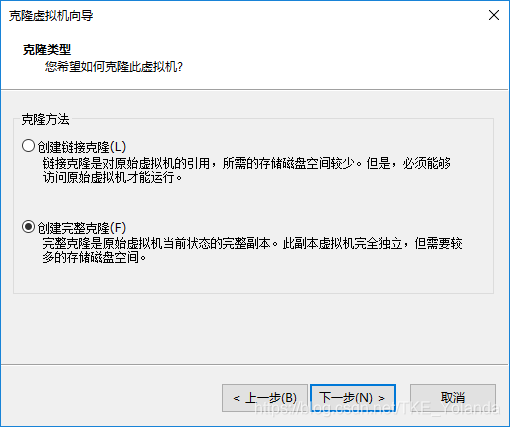
2.5 设置虚拟机名称及想要存放的位置,点击完成即可。
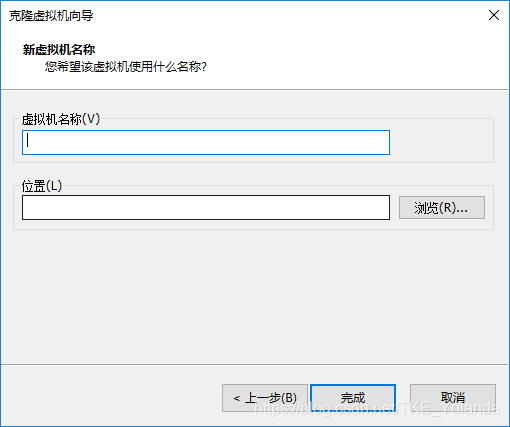
在删除JDK后再进行克隆的好处是克隆的两台虚拟机就不需要再进行删除操作了
二.集群搭建
1.集群规划
master 192.168.37.10
slave1 192.168.37.11
slave2 192.168.37 12
注意:这里的IP地址需要和本地vmnet8在同一网段内
打开控制面板,点击查看网络连接,点击net8详细信息即可查看IP地址。

2.关闭系统防火墙及内核防火墙
在每台虚拟中都要进行修改
#永久关闭防火墙
# systemctl disable firewalld
#永久关闭内核防火墙
# vim /etc/selinux/config
修改 SELINUX=disabled

3.修改主机名
在每台虚拟机中都要进行修改
# hostnamectl set-hostname master
# hostnamectl set-hostname slave1
# hostnamectl set-hostname slave2
4.修改IP地址
在每台虚拟中都要进行修改
# vim /etc/sysconfig/network-scripts/ifcfg-ens33
#修改下列信息
ONBOOT=yes
NM_CONTROLLED=yes
BOOTPROTO=static
#下列信息根据自己的情况设置
IPADDR=192.168.37.10
NETMASK=255.255.255.0
GATEWAY=192.168.37.0
DNS1=114.114.114.114
# service network restart #重启网络服务
5.修改主机文件
在每台虚拟机中都要进行修改
# vim /etc/hosts
添加以下内容(根据实际情况)
192.168.37.10 master
192.168.37.11 slave1
192.168.37.12 slave2
6.SSH互信配置
在每台虚拟机中都进行配置
# ssh-keygen -t rsa #生成密钥对(公钥和私钥)
#三次回车生成密钥
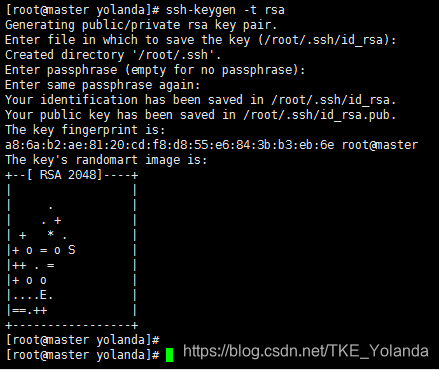
# cd /root/.ssh/ #进入.ssh目录
# ssh-copy-id -i id_rsa.pub [email protected](12) #将生成的密钥对发送到其他的服务器上

# ssh 192.168.37.11 #登录其他服务器
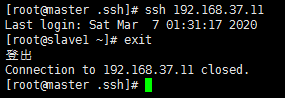
能够登录表示配置成功了。
7.安装JDK
以下操作只在master中进行
7.1 在本机下载好JDK安装包
7.2 使用XFTP传输至虚拟机
7.2.1 选定安装目录
我这里选择 /usr/local/src作为安装目录
# cd /usr/local/ #进入目录
# chmod 777 src/ #修改权限
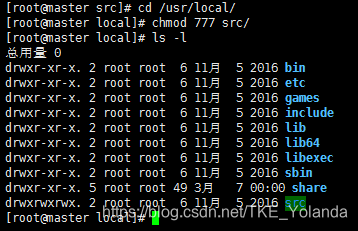
可以看到权限已经修改了
7.2.2 使用XFTP连接虚拟机
输入虚拟机名称及地址,协议选择SFTP,点击确认。
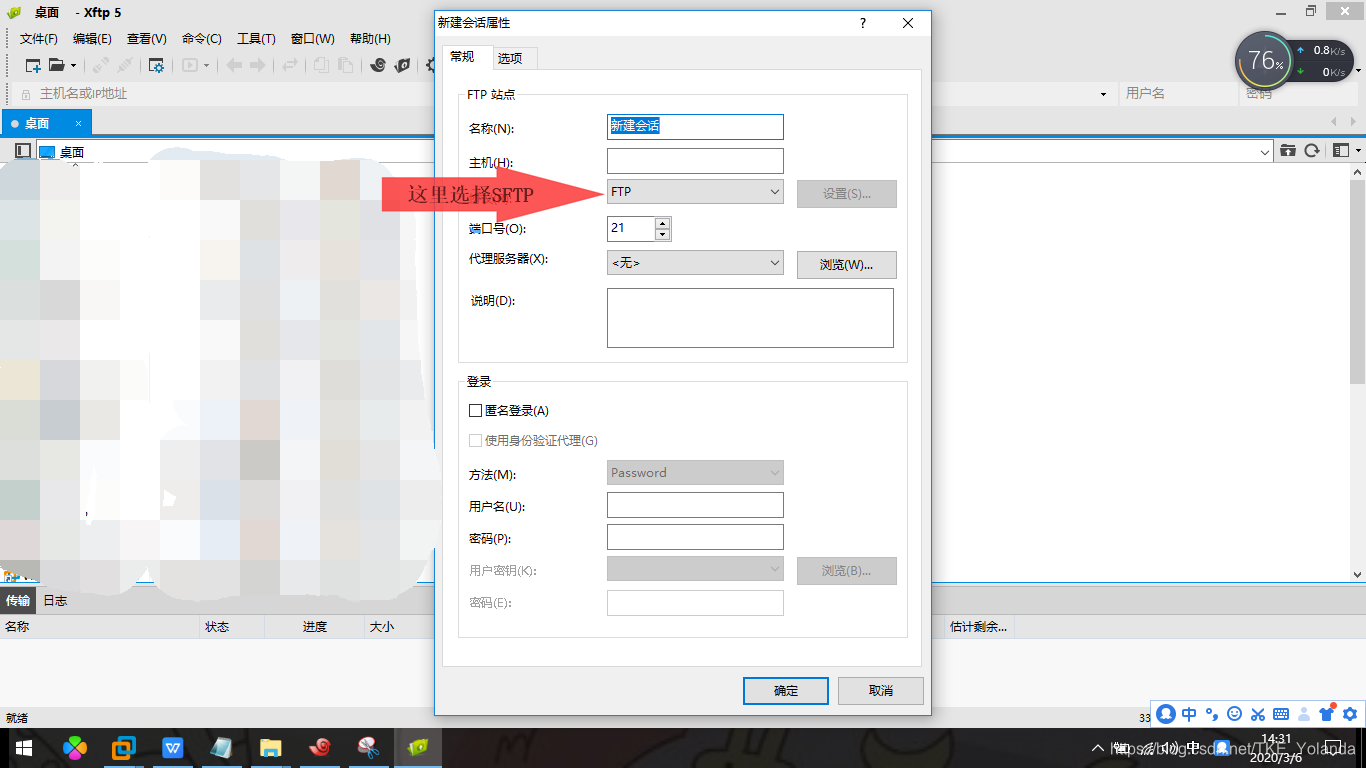
选择一次性接收
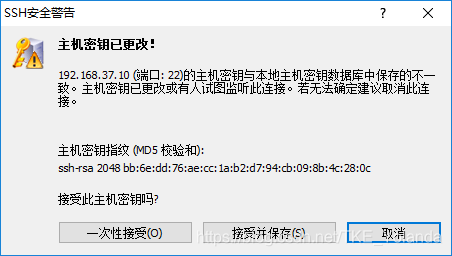
输入用户名及密码连接即可。
7.2.3 上传JDK
在右侧虚拟机选定安装的目录,在左侧本机找到下载好的JDK压缩包,双击进行传输即可。成功后右侧虚拟机会出现对应压缩包。
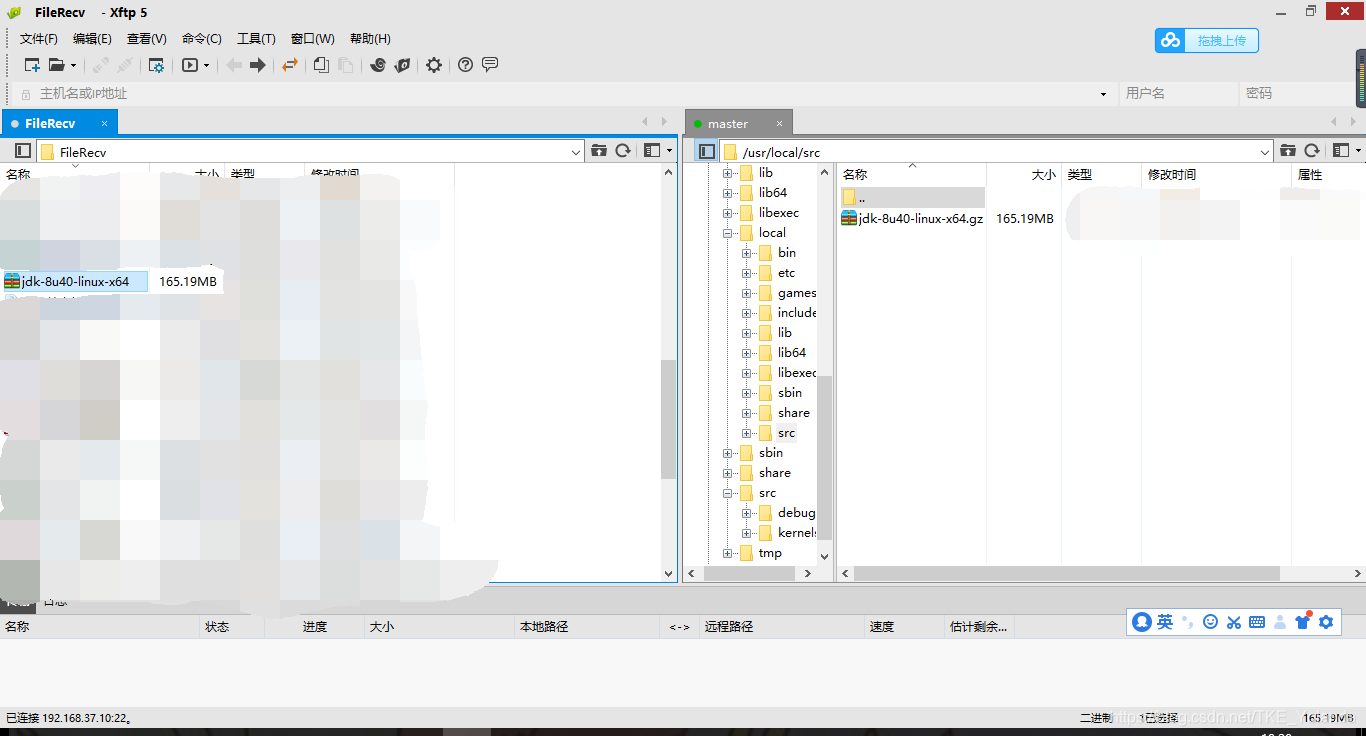
7.3 解压JDK安装包
# cd /usr/local/src/ #进入安装的目录
# tar zxvf jdk-8u40-linux-x64.gz #解压JDK安装包
7.4 配置JDK环境变量
# vim ~/.bashrc #配置JDK环境变量
添加以下内容
JAVA_HOME=/usr/local/src/jdk1.8.0_40
JAVA_BIN=/usr/local/src/jdk1.8.0_40/bin
JRE_HOME=/usr/local/src/jdk1.8.0_40/jre
CLASSPATH=/usr/local/jdk1.8.0_40/jre/lib:/usr/local/jdk1.8.0_40/lib:/usr/local/jdk1.8.0_40/jre/lib/charsets.jar
PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
分发到其他节点
# scp /root/.bashrc root@slave1:/root/.bashrc
# scp /root/.bashrc root@slave2:/root/.bashrc
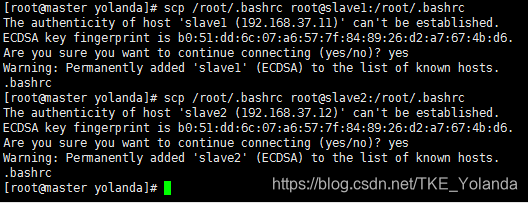
7.5 JDK拷贝到其他服务器
# scp -r /usr/local/src/jdk1.8.0_40 root@slave1:/usr/local/src/jdk1.8.0_40
# scp -r /usr/local/src/jdk1.8.0_40 root@slave2:/usr/local/src/jdk1.8.0_40
8.安装hadoop
8.1 本机下载hadoop安装包
8.2 传输至虚拟机
过程同上
8.3 解压hadoop安装包
# cd /usr/local/src/
# tar zxvf hadoop-2.6.5.tar.gz
8.4 修改hadoop配置文件
# cd /usr/local/src/hadoop-2.6.5/etc/hadoop/ #进入目录
8.4.1 配置hadoop-env.sh文件
# vim hadoop-env.sh
将JAVA_HOME文件配置为本机JAVA_HOME路径
export JAVA_HOME=/usr/local/src/jdk1.8.0_40
8.4.2 配置yarn-env.sh文件
# vim yarn-env.sh
将JAVA_HOME文件配置为本机JAVA_HOME路径(这里首先去掉这一行前面的#)
export JAVA_HOME=/usr/local/src/jdk1.8.0_40
8.4.3 配置slaves文件
# vim slaves
删除原有内容,改为以下内容
slave1
slave2
8.4.4 配置core-site.xml文件
#vim core-site.xml
在 < configuration >< /configuration > 中添加以下内容
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.37.10:9000</value>
</property>
<property>
<name>hadoop.tmp.dir< /name>
<value>file:/usr/local/src/hadoop-2.6.5/tmp</value>
</property>
这里需要注意:第一个value后面改成自己master的ip地址。第二个value这里改成自己的hadoop路径
8.4.5 复制mapred-site.xml.template文件,并命名为mapred-site.xml
# cp mapred-site.xml.template mapred-site.xml
配置mapred-site.xml文件
# vim mapred-site.xml
在 < configuration >< /configuration > 中添加以下内容
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
8.4.6 配置yarn-site.xml文件
# vim yarn-site.xml
在 < configuration >< /configuration > 中添加以下内容
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8035</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
8.5 创建一个临时文件和目录
# mkdir /usr/local/src/hadoop-2.6.5/tmp
# mkdir -p /usr/local/src/hadoop-2.6.5/dfs/name
# mkdir -p /usr/local/src/hadoop-2.6.5/dfs/data
8.6 配置环境变量
# vim ~/.bashrc #配置环境变量
添加以下内容
HADOOP_HOME=/usr/local/src/hadoop-2.6.5
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
分配到其他节点
# scp /root/.bashrc root@slave1:/root/.bashrc
# scp /root/.bashrc root@slave2:/root/.bashrc
# source ~/.bashrc #刷新环境变量
8.7 拷贝安装包到其他服务器
# scp -r /usr/local/src/hadoop-2.6.5 root@slave1:/usr/local/src/hadoop-2.6.5
# scp -r /usr/local/src/hadoop-2.6.5 root@slave2:/usr/local/src/hadoop-2.6.5
8.8 启动集群
8.8.1 初始化namenode
# hadoop namenode -format
8.8.2 启动集群
# cd /usr/local/src/hadoop-2.6.5
# start-all.sh
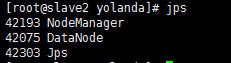
8.9 集群状态
master
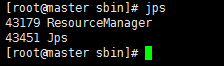
slave1

slave2
9.监控网页

