贝叶斯分类是一类分类算法的总称,这类算法均以贝叶斯定理为基础,故统称为贝叶斯分类,而朴素贝叶斯分类可谓是里面最简单、入门的一种。
首先关于贝叶斯定理,感觉简单而伟大,前些天一直在看吴军的数学之美(没看过的极力推荐)系列文章,看到自然语言处理从规则模型到统计模型转变的时候,语言的识别准确率上升好几个等级,以至于今天的语言识别到达很强大的地步,同时对于搜索引擎,网页搜索的准确率,也上升好多。这其中的最最重要的就是使用了贝叶斯准则,运用一种统计学的概念,将识别搜索的结果可能性最大化。由此我联想到当今的图像识别领域,其实和自然语言处理一样(当然实现上较之复杂多),现在的感觉就和当初自然语言的规则模型一样,受到条条框框的限制,那么图像识别为什么不也弄一个统计识别模型来呢?贝叶斯定理实现的关键是需要历史,需要样本,需要基础来训练,语言识别有非常多的语料库正好可以用,那么图像识别当然也可以有图像库拿来训练,只不过对图像,其本身不是最小单元,需要再进行处理,这一点一定程度上加大了它与语言的区别。其次图像本身的性质决定了它不是单一的元素存在,比如给你一副图像,里面可能有好几个物体可以识别。所以这一切也决定了它的困难。但是统计模式下的图像识别感觉更具有价值,只待一种方法将图像视为最小单元的算法,那个时候图像的识别将真正上升一个等级,而与之孕育而生的产业、科技,比如机器人、人工智能将会在现实中崛起。
再来谈贝叶斯分类。现实生活中,我们常常会遇到这样的问题,比如一个东西我们知道了可以分为好几类,那么现实是我们拿到一个东西后开始并不知道它属于哪一个类,我们所知道的是拿到这个东西后,对其身上的特征进行分析,把它的特征都分析出来了。比如一个人吧,我们要将其分成男女(有点不恰当,现实是你一看就知道,但是看,你也是看了其典型特征才知道的),假设一眼看不出来男女,机器没那么智能。那么对于这个人我们首先分析其特征,可以是体重,身高,头发长短,鼻子嘴巴耳朵大小等等。那么现在的问题是已知了这些特征来判断这个人是男是女,把这些特征用xi表示,男女用yi表示,那么在概率上讲问题就变化为已知特征下是男女的概率了,用数学表示就是:
那么问题的描述用数学就是:
- x是一个样本,
x=a1,a2,...,an ,其中ai 就是x的一个特征。 - x所属的类可能是:
C=y1,y2,...,yn - 计算
P(y1|x),P(y2|x),...,p(yn|x) - 找到其中最大值并属于这类,
P(yk|x)=maxP(y1|x),P(y2|x),...,p(yn|x)$,那么$x∈yk
看看上面4步,就是第三步不知道怎么办。还好伟大的贝叶斯定理告诉了我们怎么办。贝叶斯定理如下:
这个定理怎么解释呢?还是以上述男女分别为例,假设x取两个特征,身高体重,详细点的值就是身高170,体重50,那么这个人是男是女。则数学表示就是
- 是男性的概率,P(男|(身高=170,体重=50))=P((身高=170,体重=50)|男)*P(男)/P((身高=170,体重=50)),假设身高与体重这两个特征独立没有关系,那么P((身高=170,体重=50)|男)=P(身高=170|男)*P(体重=50|男),这个应该好理解,因为独立,两个连在一起的概率就是分别的概率相乘,再看看P((身高=170,体重=50)),这是什么,身高体重使我们的观察量,它的概率是多少,既然是观察量,无论是男是女,这个值是一样的,也就是是定值了,姑且认为是1吧,再看看P(男)是多少,我们训练样本,那么在所有训练样本中,每个样本属于哪一类是知道的,比如我选了50个人,其中30男20女,那么对于这个训练样本P(男)=3/5,这一项也就是样本中某一类的概率。好了最终P(男|(身高=170,体重=50))=P(身高=170|男)*P(体重=50|男)*P(男)。
- 同理是女性的概率:P(女|(身高=170,体重=50))=P(身高=170|女)*P(体重=50|女)*P(女)。
继续往下求,以男的为例,现在的问题就转变为求P(身高=170|男)*P(体重=50|男)*P(男),P(男)说了怎么办,那么P(身高=170|男)和P(体重=50|男)怎么办,这个时候就是训练样本大发神威的作用了。P(身高=170|男)的意思表示男的里面身高为170的概率,既然求男的里面身高是170的概率,因为我们有一大堆训练样本,好了把样本里面的男的挑出来,单看男的里面身高规律,我们再去统计一下,假设发现30个男的,有15个男的升高在170左右,其他的都不在,那么我们是不是可以认为男的里面身高为170的概率就是15/30=0.5了呢?当然可以。同理可以算出男的里面体重为50的概率。至于怎么根据这些值算这个概率,有很多讲究,比如我们认为人的身高符合正态分布,那么我们用一个正态分布函数去拟合身高的概率密度函数不就可以了吗?求出身高这些值得均值与方差,然后用
好了再整理一下整体的步骤:
(1)确定用于分类的训练样本集,这个样本集中,每个样本有多少个特征,以及样本属于哪一个类别要明确。
(2)计算每个类别的概率
(3)统计计算在各类别下各个特征属性的条件概率估计。也就是
至于P(x|y)怎么算,一般对于连续变化的数值,可以用正态分布函数来模拟它的概率密度。
至此训练完成,那么如何分类?分类是相对测试样本而言的,这个时候你是不知道测试的样本的分类的,只知道它的特征。好了,假设来了一个测试样本x,它的特征都知道,它属于哪一类呢?用下面公式:
假设各个特征独立(一般也都认为独立,即使有一点关系也忽略了,比如身高与体重,你能说完全没有关系,身高100的体重能有100?)既然独立那么上述转化为:
这样把这个样本
这里面有一些小的细节问题可以优化一下:
当有些特征
P(x|y) 在训练样本中没有出现,而在测试样本时出现了怎么办,你不能把P(x|y) 设置为0吧,这样乘积为0了,这个时候我们把特征x对应下的频数加1,话句话说将它认为加一点,设置为一个小的量。当样本多了,每个样本特征数多了的时候,我们知道上述是一些列p的乘积,想想每个p在0-1之间,然后在相乘,假设每个样本由100个特征,那就是100个0-1的p相乘,得是多小的一个数?小到一定程度的时候计算机直接溢出了,或者四舍五入变为0了,最后一堆0你怎么比较属于哪一类?这个时候我们采取将上述概率计算左右都取对数,对数函数对于0-1之间的数是单调变化的,原来的p大,那么log(p)也大,所以没有影响。这样可以把数据都拉回来。相乘这个时候就变为相加了。
下面在matlab下用一个实例说明朴素贝叶斯算法。
首先是样本的选择,这个样本曾经在
聚类之详解FCM算法原理及应用
里面用过,是关于种子分类的,每个种子有7个特征,种子分为3类,共210个样本,样本下载地址:
http://archive.ics.uci.edu/ml/datasets/seeds#
将数据存为txt保存到matlab工作目录下,编写一个bayes.m的脚本,具体程序如下:
clc
clear
close all
data = load('data.txt');
%选择训练样本个数
num_train = 50;
choose = randperm(length(data));%构造随机选择序列
train_data = data(choose(1:num_train),:);
test_data = data(choose(num_train+1:end),:);
mu = zeros(3,7);
sigma = zeros(3,7);
pc = zeros(3,1);
%training
for i = 1:3 %3类
index = find(train_data(:,8)==i);
pc(i) = length(index)/num_train;
data_index = train_data(index,:);
for j = 1:7 %每类7个特征
mu(i,j) = mean(data_index(:,j));
sigma(i,j) = var(data_index(:,j));
end
end
%testing
ture_num = 0;
for i = 1:length(test_data)
test_simple_data = test_data(i,:);
for j = 1:3
for k = 1:7
p(j,k) = 1/sqrt(2*pi*sigma(j,k))*...
exp(-(test_simple_data(k)-mu(j,k))^2/2/sigma(j,k));
end
end
log_p = sum(log(p),2)+log(pc);
[~,index_maxP] = max(log_p);
predict(i) = index_maxP;
if index_maxP == test_simple_data(8)
ture_num = ture_num + 1;
end
end
accuracy = ture_num/length(test_data);
plot(test_data(:,8),'or')
axis([0,length(test_data),0,5])
hold on
plot(predict,'+');
hold on
plot(abs(predict'-test_data(:,8)));
title(['the accuracy is : ',num2str(accuracy)]) 程序中可以看到,这里我们将每一个特征认为是服从正态分布的,同时训练样本选择是随机挑的,所以每次结果会不一样。
看看训练样本选择50个(测试样本210-50)下的结果:
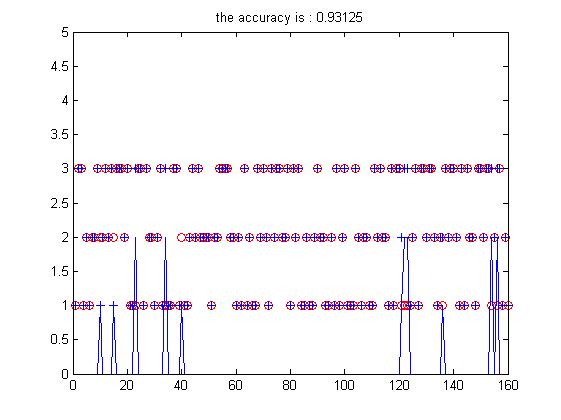
加号与圈在一起证明分对了,不在一起就错了,并且用一个尖尖凸显出来。可以看到这一次准确率有0.93。改变训练样本个数去试验其他的情况吧。我试验了多次,普遍准确率都在0.9左右,这个结果是不是还算可以。