【深度学习】神经网络介绍
1 神经元
2 激活函数
3 感知机与多层网络
4 误差反向传播
参考:周志华《机器学习》
"神经网络是由具有适应性的简单单元组成的广泛并行互连的网络,它的组织能够模拟生物神经系统对真实世界物体所作出的交互反应" [Kohonen, 1988] .
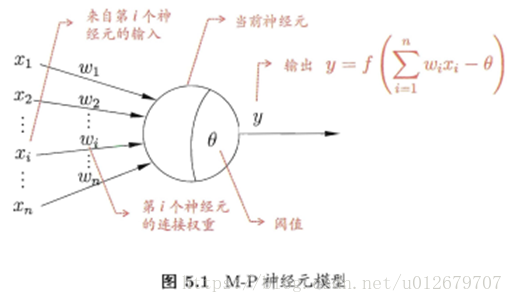
1.神经元模型
神经网络中最基本的成分是神经元 (neuron)模型,即上述中提到的"简单单元"。在生物神经网络中,每个神经元与其他神经元相连,当它"兴奋"时,就会向相连的神经元发送化学物质,从而改变这些神经元内的电位。如果某神经元的电位超过了一个"阔值"(threshold) , 那么它就会被激活,即"兴奋 "起来,向其他神经元发送化学物质。
现在常用的是:M-P神经元模型。在这个模型中,神经元接收到来自n个其他神经元传递过来的输入信号。这些输入信号通过带权重的连接( connection)进行传递,神经元接收到的总输入值将与神经元的阀值进行比较,然后通过"激活函数" (activation function) 处理以产生神经元的输出。
注意,每层有10 个神经元,两两连接,则有100个参数,其中90个连接权和10个阈值。
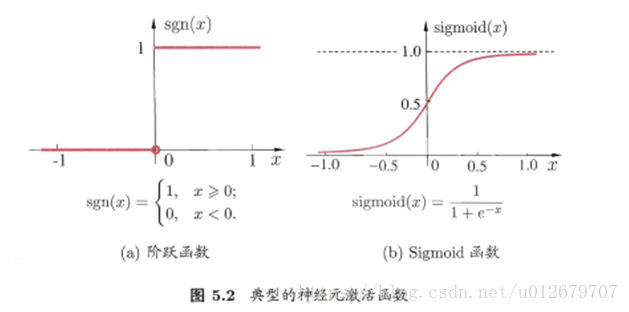
2.激活函数
理想中的激活函数是图5.2(a)所示的阶跃函数,它将输入值映射为输出值0或1。显然,"1"对应于神经元兴奋,"0"对应于神经元抑制。然而,阶跃函数具有不连续、不光滑等不太好的性质,因此实际常用Sigmoid函数作为激活函数。典型的 Sigmoid 函数如图5.2(b) 所示,它把可能在较大范围内变化的输入值挤压到 (0,1) 输出值范围内,因此有时也称为 "挤压函数" (squashing function)。
3.感知机与多层神经网络
感知机(Perceptron)由两层神经元组成,如图5.3所示,输入层接收外界输入信号后传递给输出层,输出层是M-P神经元,亦称"阈值逻辑单元" (thresholdlogic unit) 。

感知机能容易地实现逻辑与、或、非运算。注意到
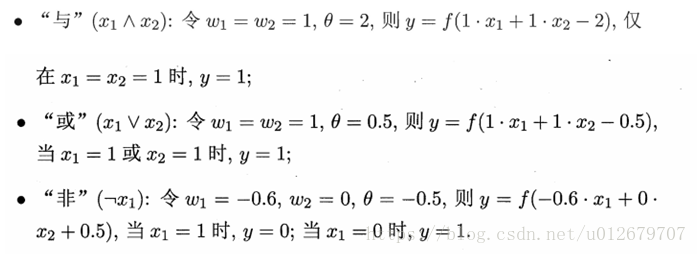
那么,感知机是如何学习的呢?
给定训练数据集,权重
感知机的学习规则非常简单,对训练样例(x,y),若当前感知机的输出为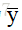

其中η∈(0,1)称为学习率。从式(5.1)可看出,若感知机对训练样例 (x,y) 预测正确,即
注意,感知机只有输出层神经元进行激活函数处理,即只拥有1层功能神经元,其学习能力非常有限。事实上,上述与、或、非问题都是线性可分的问题。可以证明,若两类模式是线性可分的,即存在一个线性超平面能将它们分开。
如图5.4(a)-(c)所示,若两类模式是线性可分的, 必存在一个线性超平面能将它们分开,则感知机的学习过程一定会收敛,故而求得适当的权向量w=

那感知机的学习能力非常有限,只能解决线性可分问题,要解决非线性可分问题,怎么办呢?
要解决非线性可分问题,需考虑使用多层功能神经元。例如图5.5中这个简单的两层感知机就能解决异或问题。图5.5 (a)中,输出层与输入居之间的一层神经元,被称为隐含层,隐含层和输出层神经元都是拥有激活函数的功能神经元。

多层神经网络
常见的神经网络多层级结构,每层神经元与下层神经元全互连。神经元之间不存在同层连接,也不存在跨层连接. 这样的神经网络结构通常称为"多层前馈神经网络",其中输入层神经元接收外界输入,隐层与输出层神经元对信号进行加工,最终结果由输出层神经元输出。
即:输入层神经元仅是接受输入,不进行函数处理,隐居与输出层包含功能神经元.
因此,只需包含隐层,即可称为多层网络。神经网络的学习过程,就是根据训练数据来调整神经元之间的"连接权"以及每个功能神经元的阈值。换言之,神经网络"学"到的东西,蕴涵在连接权与阈值中。

4.误差反向传播
使用神经网络时,大多是在使用 BP 算法进行训练。并且,BP算法不仅可用于多层前馈神经网络,还可用于其他类型的神经网络,例如训练递归神经网络 RNN。但通常说 "BP网络"时,一般是指用BP算法训练的多层前馈神经网络。
图5.7给出了一个拥有d个输入神经元、L个输出神经元、q个隐层神经元的多层前馈网络结构。
各参数含义如下:


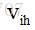


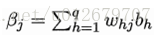
假设隐含层和输出层神经元都使用图5.2(b)中的Sigmoid函数。


BP 是一个法代学习算法,在迭代的每一轮中采用广义的感知机学习规则对参数进行更新估计,与式(5.1 )类似,任意参数υ 的更新估计式为
υ ← υ +Δv . (5.5)
下面我们以图5.7中隐层到输出层的连接权
BP算法基于梯度下降策略,以目标的负梯度方向对参数进行调整。对式(5.4)的误差


学习率η∈(0,1)控制着每一轮迭代中的更新步长,学习率太大则容易振荡,太小则收敛速度又会过慢。但有时为了精细调节,可令式(5.11)与(5.12)使用η1,式(5.13)与(5.14)使用η2 ,两者未必相等。即可在不同的层使用不同的学习率。

BP算法的目标是:最小化训练集D上的累积误差。

但我们上面介绍的"标准BP算法"每次仅针对一个训练样例更新连接权和阔值,也就是说,5.8中算法的更新规则是基于单个的Ek推导而得。
如果类似地推导出基于累积误差最小化的更新规则,就得到了累积误差反向传播算法。累积BP算法与标准BP算法都很常用。
标准BP和累积BP算法的比较:
一般来说,标准BP算法每次更新只针对单个样例,参数更新得非常频繁,而且对不同样例进行更新的效果可能出现"抵消"现象。因此,为了达到同样的累积误差极小点,标准BP往往需进行更多次数的迭代。累积BP算法直接针对累积误差最小化,它在读取整个训练集D一遍后才对参数进行更新,其参数更新的频率低得多。但在很多任务中,累积误差下降到一定程度之后,进一步下降会非常缓慢,这时标准BP往往会更快获得较好的解,尤其是在训练集D非常大时更明显。
多层神经网络有多神奇?
只要具有包含足够多神经元的隐层,多层前馈网络就能以任意精度逼近任意复杂度的连续函数。
然而,如何设置隐层神经元的个数仍是个未决问题,实际应用中通常靠"试错法" (trial-by-error)调整.
那神经网络有何缺点?
正是由于其强大的表示能力,BP神经网络经常遭遇过拟合。其训练误差持续降低,但测试误差却可能上升。
那如何避免过拟合?
有两种策略常用来缓解BP网络的过拟合。
第一种策略是"早停" : 将数据分成训练集和验证集,训练集用来计算梯度、更新连接权和阈值,验证集用来估计误差。若训练集误差降低但验证集误差升高,则停止训练,同时返回具有最小验证集误差的连接权和阈值。
第二种策略是"正则化",其基本思想是在误差目标函数中增加一个用于描述网络复杂度的部分,例如连接权与阈值的平方和。仍令Ek表示第k个训练样例上的误差,Wi表示连接权和阙值,则误差目标函数(5.16) 变为:

其中λ∈(0,1)用于对经验误差与网络复杂度这两项进行折中,常通过交叉验证法来估计。
增加连接权与阈值平方和这一项后,训练过程将会偏好比较小的连接权和阈值,使网络输出更加"光滑"从而对过拟合有所缓解。
为何选择梯度下降法?
基于梯度的搜索是使用最为广泛的参数寻优方法。在此类方法中,我们从某些初始解出发,迭代寻找最优参数值。每次迭代中,我们先计算误差函数在当前点的梯度,然后根据梯度确定搜索方向。例如,由于负梯度方向是函数值下降最快的方向,因此梯度下降法就是沿着负梯度方向搜索最优解。
若误差函数在当前点的梯度为零,则已达到局部极小,更新量将为零,这意味着参数的迭代更新将在此停止。显然,如果误差函数仅有一个局部极小,那么此时找到的局部极小就是全局最小;然而,如果误差函数具有多个局部极小,则不能保证找到的解是全局最小。对后一种情形,我们称参数寻优陷入了局部极小,这显然不是我们所希望的。

如何跳出局部极小?

------------------------------------------- END -------------------------------------