- 机器学习中分类和预测算法的评估:
- 准确率
- 速度
- 强壮性(算法中当有噪音和某些值缺失时,算法能否依然很好)
- 可规模性
- 可解释性(能否很好的解释模型)
一、什么是决策树?
1、判定树(决策树)是一个类似于流程图的树结构,其中,每个内部节点表示在一个属性上的测试,每一个分支代表一个属性输出,而每个树叶结点代表类或类分布。树的最顶层是根结点。
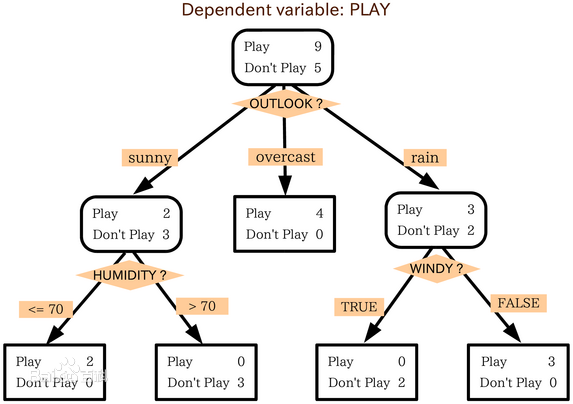
2.决策树是机器学习中分类方法中的一个重要算法
3.熵(entropy)概念:
信息和抽象如何度量?
1948年,香农提出了“信息熵(entropy)”的概念。
一条信息的信息量大小和它的不确定性有直接的关系,要搞清楚一件非常非常不确定的事情,或者是我们一无所知的事情,需要了解大量信息==》信息量的度量等于不确定性的多少。
比特(bit)来衡量信息的多少。
信息熵计算公式:
变量的不确定性越大,熵也就越大。

二、决策树归纳算法(ID3)
选择属性判断结点
信息获取量/信息增益(Information Gain):
Gain(A) = Info(D) - Infor_A(D)
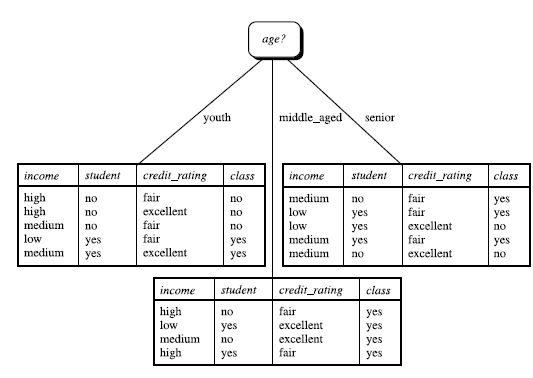
通过A来作为结点分类获取了多少信息,下图是根据年龄、收入、是否为学生、信用度来判断一个人是否要购买电脑
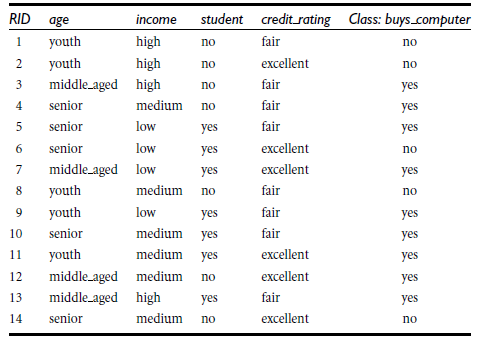

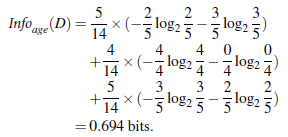
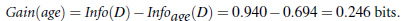
类似,Gain(income) = 0.029
Gain(student) = 0.151
Gain(credit_rating) = 0.048
所以,由于age属性的信息增益最大,选择age作为第一个根结点。
重复此过程。。。
下面是直接调用sklearn包的代码:
from sklearn.feature_extraction import DictVectorizer#sklearn对数据输入格式有要求,不能是类型的数据,必是整形的数据,所以需要转换
import csv#原始数据存在于csv文件里
from sklearn import preprocessing
from sklearn import tree
from sklearn.externals.six import StringIO
#读取csv文件
allElectronicsData = open(r'D:\data\decisiontree.csv','rt')
reader = csv.reader(allElectronicsData)
#headers = reader.next()#headers指的是特征
headers = next(reader)#headers是csv文件的第一行数据
print(headers)
featureList = []#featureList是特征值,例如年龄、信用度等
labelList = []#labellist是标签值,也就是结果是否买电脑
for row in reader:
labelList.append(row[len(row) - 1])
rowDict = {}
for i in range(1,len(row) - 1):
rowDict[headers[i]] = row[i]
featureList.append(rowDict)
print(featureList)
#利用python进行转化
vec = DictVectorizer()
dummyX = vec.fit_transform(featureList).toarray()#特征值的列表,是0,1的列表
print("dummyX:"+str(dummyX))
print(vec.get_feature_names())
print("labellist:"+str(labelList))
lb = preprocessing.LabelBinarizer()
dummyY = lb.fit_transform(labelList)
print("dummyY:"+str(dummyY))
clf = tree.DecisionTreeClassifier(criterion = 'entropy')#不带参数默认是基尼系数
#criterion = ‘entrropy’使用ID3方法
clf = clf.fit(dummyX,dummyY)
print("clf:"+str(clf))
#生成一个dot树,可用dot命令生成pdf文件
with open("allElectronicInformationGainOri.dot",'w') as f:
f = tree.export_graphviz(clf,feature_names=vec.get_feature_names(),out_file = f)
#oneRowX是拷贝出一条数据,修改一些特征值,来进行测试
oneRowX = dummyX[0,:].reshape(1,-1)
print("oneRowX:"+str(oneRowX))
newRowX = oneRowX
newRowX[0][0] = 1
newRowX[0][2] = 0
print("newRowX:"+str(newRowX))
predictedY = clf.predict(newRowX)
print("predictedY:"+str(predictedY))
下面是decisiontree.csv的内容:
运行结果为:
运行cmd,生成的allElectronicInformationGainOri.dot文件可以用dot生成pdf文件(实现需要安装Graphviz:(http://www.graphviz.org),然后需要配置环境变量,在path中添加)
命令:dot -Tpdf allElectronicInformationGainOri.dot -o test.pdf
结果为:




三、机器学习实战
1、程序清单3-1
计算给定数据集的香农熵
from math import log
#计算给定数据集的香农熵
def calcShannonEnt(dataSet):
numEntries = len(dataSet) #计算数据集中实例的总数
labelCounts = {} #创建一个数据字典
for featVec in dataSet:
currentLabel = featVec[-1] #数据字典的键值,是数据集最后一列的数值
if currentLabel not in labelCounts.keys(): #如果当前键值不存在,则扩展字典并将当前键值加入字典
labelCounts[currentLabel] = 0
labelCounts[currentLabel] += 1 #每个键值都记录了当前类别出现的次数
shannonEnt = 0.0
for key in labelCounts:
prob = float(labelCounts[key])/numEntries #计算类别发生的概率
shannonEnt -= prob*log(prob,2) #用这个概率计算香农熵
return shannonEnt
#创建数据集
def createDataSet():
dataSet = [[1,1,'yes'],
[1,1,'yes'],
[1,0,'no'],
[0,1,'no'],
[0,1,'no']]
labels = ['no surfacing','flippers']
return dataSet,labels
myDat,labels = createDataSet()
print(myDat)
print(labels)
print(calcShannonEnt(myDat))
运行结果为:
2、程序清单3-2
按照给定特征划分数据集

def splitDataSet(dataSet,axis,value):#dataSet待划分的数据集 axis划分数据集的特征 value需要返回的特征值的值
retDataSet = [] #创建新的list对象
for featVec in dataSet:
if featVec[axis] == value:
reducedFeatVec = featVec[:axis]
#L = ['haha','xixi','hehe','heihei','gaga']
#>>> L[:3] 若第一个索引为0,可以省略
# ['haha', 'xixi', 'hehe']
#>>> L[-2:]
#['heihei', 'gaga']
reducedFeatVec.extend(featVec[axis+1:])
retDataSet.append(reducedFeatVec)
return retDataSet
print(splitDataSet(myDat,0,1))
print(splitDataSet(myDat,0,0))
运行结果
3、程序清单3-3
选择最好的的数据集划分方式

def chooseBestFeatureToSplit(dataSet):
numFeatures = len(dataSet[0]) - 1 #数据集中的特征数
baseEntropy = calcShannonEnt(dataSet) #计算整个数据集的香农熵
bestInfoGain = 0.0
bestFeature = -1
for i in range(numFeatures):
featList = [example[i] for example in dataSet]
uniqueVals = set(featList) #创建唯一的分类标签列表,从列表中创建集合是python语言得到列表中唯一元素值得最快方法
newEntropy = 0.0
for value in uniqueVals:
subDataSet = splitDataSet(dataSet,i,value)
prob = len(subDataSet)/float(len(dataSet))
newEntropy+=prob*calcShannonEnt(subDataSet)
infoGain = baseEntropy - newEntropy
if(infoGain>bestInfoGain):
bestInfoGain = infoGain
bestFeature = i
return bestFeature
4.程序清单3-4
创建树的函数代码
import operator
#多数表决
def majorityCnt(classList):
classCount = {}
for vote in classList:
if vote not in classCount.keys():
classCount[vote] = 0
classCount[vote] += 1
sortedClassCount = sorted(classCount.iteritems(),key=operator.itemgetter(1),reverse=True)
#key=operator.itemgetter(1)或key=operator.itemgetter(0)决定以字典的键排序还是以字典的值排序
#0为以键排序,1为以值排序
#reverse(是否反转)默认是false,如果reverse=True,则反转由大到小排序
return sortedClassCount[0][0]
#创建树的代码
def createTree(dataSet,labels):
classList = [example[-1] for example in dataSet]
#print("classList第一个元素为:"+classList[0])
#print("classList第一个元素的数量为:"+str(classList.count(classList[0])))
#print("classList列表的长度为:"+str(len(classList)))
if classList.count(classList[0]) == len(classList): #类别完全相同则停止继续划分
return classList[0]
#print("dataSet[0]为:"+str(dataSet[0])) #输出dataSet[0]为:[1, 1, 'yes']
#print("dataSet[0]的长度为:"+str(len(dataSet[0])))
if len(dataSet[0]) == 1: #遍历完所有特征时返回出现次数最多的类别***(dataSet[]如果只有一个特征,那就返回这个特征个数最多的那个)
return majorityCnt(classList)
bestFeat = chooseBestFeatureToSplit(dataSet)
bestFeatLabel = labels[bestFeat]
#print("bestFeatLabel为:"+bestFeatLabel)
myTree = {bestFeatLabel:{}}
#print("最开始myTree为:"+str(myTree))
del(labels[bestFeat])
featValues = [example[bestFeat] for example in dataSet]
uniqueVals = set(featValues)
#print("uniqueVals:"+str(uniqueVals))
for value in uniqueVals:
subLabels = labels[:]
# print("subLabels:"+str(subLabels))
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet,bestFeat,value),subLabels)
return myTree
myDat,labels = createDataSet()
myTree = createTree(myDat,labels)
print(myTree)
print(myDat)
print(labels)
运行结果为:
