系统性风险与非系统性风险
假设有一资产在可行集内,坐标为(σ1,r1),我们知道CML的方程为E(RP) = Rf + [(E(RM) - Rf) / σM] × σP,将r1代入E(RP) 可得σP1,σP1就是系统性风险,σ1 - σP1为非系统性风险。系统性风险可看做是公司外部的不可控的市场风险,无法通过分散消除;非系统性风险是由公司自身因素引发的,可以通过分散消除。
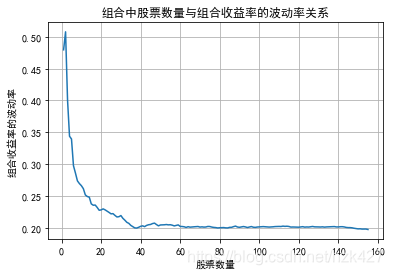
下面以2016-2018年的上证180指数的成分股为例来模拟投资组合,且剔除了在该时段内上市的公司数据,最终保留155支股票。做法是在组合中逐渐增加成分股股票数量N,并且保证每支股票等权重(均为1/N),计算出N个组合的波动率。可以预测随着组合中成分股数量的增加,分散化带来的好处越来越大,组合的波动率会逐渐下降。
import numpy as np
import pandas as pd
df=pd.read_excel('C:/Users/lenovo/Desktop/155支成分股日收盘价.xlsx',index_col=0)
#若不指定索引为日期列,它会自动生成一列索引
df.describe()
Out[1]:
洛阳钼业 华友钴业 口子窖 ... 首创股份 白云机场 浦发银行
count 731.000000 731.000000 731.000000 ... 731.000000 731.000000 731.000000
mean 5.244309 56.553228 40.662859 ... 5.259658 13.992517 14.021341
std 1.635156 29.425595 8.710005 ... 1.495235 1.969342 2.744419
min 3.060000 14.120000 28.260000 ... 3.020000 9.760000 9.260000
25% 3.960000 34.285000 34.045000 ... 4.150000 12.500000 11.710000
50% 4.490000 47.950000 36.560000 ... 4.770000 14.010000 13.170000
75% 6.740000 82.685000 46.385000 ... 6.410000 15.230000 16.480000
max 9.690000 132.090000 66.000000 ... 9.400000 19.890000 18.450000
[8 rows x 155 columns]
可以发现该数据共有155支股票以及731个交易日的日收盘价数据。下面计算每支股票的对数收益率,并且生成不同数量股票对应的投资组合的收益波动率:
r=np.log(df/df.shift(1))
r=r.dropna()
n=155
volp=np.zeros(n)#生成存放投资组合收益率序列波动率的初始数组
for i in range(1,n+1):
w=np.ones(i)/i#生成权重数组1/N
cov=252*r.iloc[:,0:i].cov()#依次计算股票间的年协方差
volp[i-1]=np.sqrt(w@cov@w)#@与np.dot一样表示矩阵的内积,最后一个w自动转换为列向量
然后画图,发现N在30以上时就已经达到最优分散化效果了:
import matplotlib.pyplot as plt
from pylab import mpl
mpl.rcParams['font.sans-serif']=['SimHei']
mpl.rcParams['axes.unicode_minus']=False
plt.plot(range(1,156),volp)
plt.xlabel('股票数量')
plt.ylabel('组合收益率的波动率')
plt.title('组合中股票数量与组合收益率的波动率关系')
plt.grid()
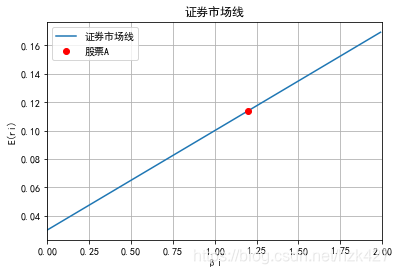
模型表达式的应用及证券市场线
资本资产定价模型的表达式为E(Ri) = Rf + βi × [E(Rm) - Rf],E(Ri)是资产i的预期收益率,E(Rm)是所有可投资资产组合(即市场组合)产生的收益率,βi是资产i的预期收益率与市场收益率敏感性的反映。
假定股票A的β值为1.2,无风险利率为3%,市场组合收益率为10%,求股票A的预期收益率,并在证券市场线上标出该点:
def r(rf,beta,rm):
return rf+beta*(rm-rf)
rf,beta,rm=0.03,1.2,0.1
ri=r(rf,beta,rm);ri
Out[3]: 0.114
x=np.arange(0,2.0,0.01)#np.arange()支持步长为小数
plt.plot(x,rf+x*(rm-rf),label='证券市场线')
plt.plot(beta,rf+beta*(rm-rf),'ro',label='股票A')
plt.xlabel('βi')
plt.ylabel('E(ri)')
plt.xlim(0,2)
plt.title('证券市场线')
plt.legend()
plt.grid()
CAPM的实证检验
使用资本资产定价模型的关键在于估计斜率值β,下面以2016年-2018年沪深300指数的日收盘价为市场组合数据,从上述df数据框中挑出第1只股票,使用线性回归估计这只股票的β,进而写出CAPM表达式:
import statsmodels.api as sm
hs300=pd.read_excel('C:/Users/lenovo/Desktop/16-18沪深300指数.xlsx',index_col=0)
rhs=np.log(hs300/hs300.shift(1))
rhs=rhs.dropna()
rhs.describe()
Out[5]:
沪深300指数
count 730.000000
mean -0.000194
std 0.011610
min -0.071853
25% -0.005143
50% 0.000359
75% 0.005065
max 0.042262
y=r.iloc[:,0];y.head()#取出第一支股票的收益率序列
Out[6]:
日期
2016-01-05 -0.020101
2016-01-06 0.094387
2016-01-07 -0.104591
2016-01-08 0.047568
2016-01-11 -0.063073
Name: 洛阳钼业, dtype: float64
rhs_addc=sm.add_constant(rhs)
model=sm.OLS(y,rhs_addc).fit()
model.summary()
Out[7]:
<class 'statsmodels.iolib.summary.Summary'>
"""
OLS Regression Results
==============================================================================
Dep. Variable: 洛阳钼业 R-squared: 0.284
Model: OLS Adj. R-squared: 0.283
Method: Least Squares F-statistic: 289.0
Date: Mon, 03 Feb 2020 Prob (F-statistic): 7.85e-55
Time: 16:34:19 Log-Likelihood: 1641.2
No. Observations: 730 AIC: -3278.
Df Residuals: 728 BIC: -3269.
Df Model: 1
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
const 0.0002 0.001 0.188 0.851 -0.002 0.002
沪深300指数 1.3874 0.082 17.000 0.000 1.227 1.548
==============================================================================
Omnibus: 112.290 Durbin-Watson: 2.045
Prob(Omnibus): 0.000 Jarque-Bera (JB): 250.210
Skew: 0.848 Prob(JB): 4.65e-55
Kurtosis: 5.313 Cond. No. 86.2
==============================================================================
print('洛阳钼业股票的CAPM模型表达式为R={:.4f}+{:.4f}×Rm。'.format(model.params[0],model.params[1]))
洛阳钼业股票的CAPM模型表达式为R=0.0002+1.3874×Rm。
