SVM已经过时,有没有必要再去学习?
SKlearn已将把各种模型都已经封装好了,调用就行了,还有没有必要再去学习这些算法?
重要的是发现问题,解决问题的一个过程?推导过程很重要
如果关注KKT,凸优化和SVM本质并没有什么关系。
每一个深度学习算法都会有大量的变种,在这种情况下应该学习如何能通过发现一个问题,改进算法,解决一个问题,这种思路才是机器学习的精髓。
基础知识:对线性分类模型和向量矩阵求导有大概的了解
1、线性分类模型主要有四种不同的方法,线性判别函数、生成式模型、判别式模型以及贝叶斯观点下的Logistic回归。
2、我们直接考虑对原始输入空间
进行分类,当然也适用于对输入变量进行一个固定的变换
。判别函数是一个以向量
个类别中的某一个类别(
)的函数。
二分类
线性判别函数为
如果,则它被分到
中,否则被分到
中。
注:是不是和上一篇讲超平面的函数一样!!!
多分类
‘one-versus-the-rest'方法使用
个分类器,每个分类器是一个二分类问题,分开属于
‘one-versus-one'方法使用
个分类器,每个数据点的类别根据这些判别函数中的大多数输出类别确定。但是这也可能会产生输入空间无法分类的区域,如图所示。
引入一个
对于一个数据点最大,就把它分到
之间的决策面为
。这样的决策区域总是单连通的,并且是凸的。
对于二分类问题也可以构造基于两个线性函数和
的判别函数,只是前述方法更简单且是等价的。


更多参考:
https://www.jianshu.com/p/8d59f38792e5
Pattern Recognition and Machine Learning (Information Science and Statistics)
向量矩阵求导
。。。。。。自学
开始SVM
按照以下问题成文:
- 由线性分类任务开始
- 为何需要最大化间隔
- 怎么解决凸二次规划问题
- 对偶问题的求解
- SMO算法
- 核函数的由来和使用
- SVM与LR的异同
1、SVM由线性分类开始

- 无间隔的决策边界(超平面)
w.x+b>=0 正样本
w.x+b<=0 负样本
- 有间隔的决策边界(超平面)
- w.x+b>=1 正样本
w.x+b<=-1 负样本

- 把两个约束条件简化成一个前面是间隔,后面的1是人为设定的阈值,等号成立的时候,就是表明样本点在决策边界傍边的间隔上
这就找到了第一个约束条件
看不懂这儿吗??我是假设的
- 当x为正时,y=1
- 当x为负时, y=-1
点到超平面的距离
平面:
样本空间中的任意一点 x,到超平面(w,b)的距离,可以表示为
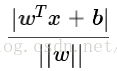
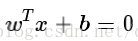
我们需要找到超平面来分开两类数据
这个超平面要离两类样本足够远,是的分隔最大。即最终需要确定菜蔬w和b连个参数,是的距离最大。
x1是负样本,
=-1,w=1,则x1=1+b
x2是正样本,
- 求出x1与x2的间隔:
- 划重点结论:间隔大小和数据集没有任何关系,只要知道了法向量w,就可以顺利求出间隔大小.这是一个神奇的结论。
最大化间隔:
首先明白:SVM的目标是给定了一个训练集,如何找到一个决策边界(超平面),使得正负样本正确区分,并且决策边界(超平面)距离每个样本点距离(间隔)足够大。
- 所以,就是求得
- 等价于
- 等价于
- 等价于
- 这么转化纯粹是为了方便计算
- 计算任务就变成了,寻找一个满足下列约束的w
s.t.
做到这一步,这是一个典型的线性支持向量机(线性SVM)
如何优化最大间隔
我们可以看到,上面的基本型目标函数是二次的,约束条件是线性的,这是一个凸二次规划问题。可以直接用现成的优化计算包求解。但若利用“对偶问题”来求解,会更高效。
1、凸优化说的是这么一回事情:可以想象成给我一个凸函数,我要去找到最低点。当然凸优化是一个很大很厉害的领域,在这里,我们只需要知晓这个问题是这么一回事。然后,这回事要怎么样求解,就好,有兴趣的朋友可以参考凸优化的概念或者Stephen Boyd & Lieven Vandenberghe 的《Convex Optimization》。
2、二次规划:
目标函数和约束条件都为
变量的线性函数,叫做-----线性规划问题。
目标函数为变量的二次函数和约束条件为变量的线性函数,叫做-----二次规划问题。
目标函数和约束条件都为非线性函数,叫做-----非线性规划问题。3、拉格朗日对偶性,即,通过给每一个约束条件加上一个拉格朗日乘子。然后定义出拉格朗日函数,通过拉格朗日函数将约束条件融合进目标函数中。目的是,
只需要通过一个目标函数包含约束条件,便可以清楚解释问题。
- 拉格朗日把一个带约束条件的函数极值的算法,转变成一个不带约束条件函数极值算法。 找到一个alpha值,使得L最大
-
未知变量是阿尔法,w和b
分别对w和b求偏导,令偏导等于0
- 对alpha求偏导,令其等于零
-
- 对b求偏导 ,令其等于零
-
- 因此,w可以看做支持向量的线性组合
-
坐标提升 SMO
把
带入L,得
则L的值取决于
u是一个待预测的样本点,则
则alpha大部分值是0,极少有值,有值得alpha对应的x叫做支持向量
怎么求alpha才是KKT,SMO,QP等等要解决的问题核方法
大部分分类问题都是非线性的,很难找到一条直线把他们区分开
可以经过转换,使他转变成线性问题
核方法:
变换前的点乘:
只需要知道变换后的点乘:
,就很难跑完大数据任务。?啥意思,我还没看懂
