前言:
以下是我课程的一个报告,内容不包括代码的具体实现。如果您是为了学代码而来,就不用在这个网页浪费时间了。此报告发出旨在欲与大家讨论下,你们觉得能否通过对文本的向量表示的学习,让分类器学习出文本类别。
论文录用率预测分析报告
0引言:
众所周知,计算机领域的学术会议有很多,分为A+,A,B,C,L共5个档次。其中A+属于顶级会议,基本是这个领域的杰出者参与和关注最多的会议。
A类也是非常好的会议,尤其是一些热门的研究方向,A类的会议投稿多录用率低,部分A类会议影响力逐步逼近A+类会议。B类的会议分两种,一种称为盛会级,参与的人多,发表的论文也多,论文录用难度比上两个级别要低很多,通常是行业内的学者们年度交流的好时机。一种是专业级的小会,圈子往往比较小,但是也有一些相对质量不错的成果发表。另外B类也是一个分水岭,是区分精华成果和普通成果的分界线,再求其次的C类会议知名度就低很多了,而L级的会议更多。除此以外计算机还有更多的会议不在排名内,属于更不入流的会议。
本文第一部分为数据集描述;第二部分为分类预测,旨在区分A类论文和C类论文;第三部分为结果分析,主要分析了不同的模型的效果,及对初始问题的讨论。
1数据集描述:
ICML和ACML近五年来的论文:http://proceedings.mlr.press/
提取论文的题目、摘要,采用doc2vec模型建立论文的表示向量。再采用机器学习分类方法预测一篇文章能否被ICML录用(即是否属于A类文章)。


图1:浏览器论文格式
近五年的数据中,ICML论文数要远多于ACML,数据已经达到了不平衡的状态。也因此考虑“数据过采样和欠采样或加权”、“离散点检测”两种方法去解决该问题。

图2:爬虫核心代码


图3:ACML和ICML数据集
同时为了最终的模型预测,又分别爬了13年的ACML和ICML论文作为测试数据。
![]()
![]()
以及其他A+类文章数据(好吧,这个是从舍友那里直接拿的):
![]()
![]()

图4:A+类数据集格式
2分类预测:
2.1逻辑回归算法

图5:文本向量表示

图6:建立逻辑回归分类器
将icml.txt和acml.txt数据集文本利用doc2vec建立向量表示(向量长度50),并将icml.txt作为正例,acml.txt作为反例训练逻辑回归分类器。最终将分类器保存,用于后面数据分析。
A类预测Label为1,C类预测Label为0。
分类器在13年icml(A类会议)文章测试结果(13年icml文章60多篇,取50篇做测试):
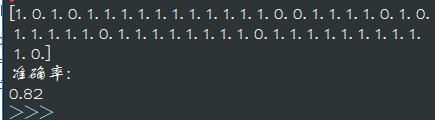
图7:逻辑回归分类器对13年icml论文分类结果
13年acml文章32篇(C类会议),分类器预测结果:

图8:逻辑回归分类器对13年acml论文分类结果
可以发现分类器在A类文章的识别上,比C类准确的多。也就是说,分类器把大部分文章归为了A类文章。与其说分类器对icml论文预测的准确率为80%。不如说,对每一篇文章分类器有80%的概率归为A类文章。
虽然在分类器训练时将A类数据的权重有意减小,但仍有可能是icml(A类)数据量大于acml(C类)数据量导致的分类器对A类特征学习的过拟合。
因为分类器的训练数据是icml会议和acml会议,用13年的icml会议做测试。并不能确定分类器学习的是A类文章和C类文章等级的差异,还是icml会议论文和acml会议论文内容的不同。
既然分类器在识别icml(A类)文章上效果能达到80%,那换个A类会议的预测效果如何呢?
AAAI,美国人工智能协会,A+类会议:

图9:逻辑回归分类器在aaai会议数据集上的分类结果
准确率瞬间跌到了57%,aaai会议中大部分内容为机器学习,其余文章也属于人工智能范畴。这就更加让我确定,分类器学习的就是文章内容的差异(准确点说,只是icml和acml五年来论文内容的不容),而没有学到文本的等级差异。
打个比方,分类器学到了文章的主题内容,比如“机器学习”。但是一个A类文章说的是“机器学习”,一个C类文章说的也是“机器学习”,那分类器有很大可能性认为这两篇文章属于一类。而不是我们认为的分类器学到了什么是A类文章,什么是C类文章。
2.2离散点检测模型
除了训练分类器时修改数量多的数据的权重,或者采用欠采样、逆采样的方法之外。完全可以将多的那类文章作为模型训练的数据集,而将少的那一类作为离散点样本。利用离散点检测的方法来鉴别出离散点与正常点。
将icml近两千篇文章全部取出,训练模型。再将测试集的所有数据与此模型进行相似性对比,判断测试集中的数据是否为离散点,如果某样本是离散点则认为该样本不属于此模型(即不属于A类,从而判定为时C类文章)。
采用Ellipticalenvelope算法,模型的原理上求出训练集在空间的重心和方差,然后根据高斯密度估算每个点被分配到重心的概率。如果某点的概率满足某一条件,则认为该点不是离群点。
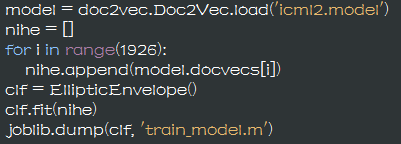
图10:Ellipticalenvelop离散点检测模型训练
它在acml(C类)数据集上的准确率比逻辑回归分类器效果好很多。


图11:离散点模型在acml(C类)测试集上的预测结果
基本上是全对的,c类里面有90%的数据认为不属于这个模型,也就是属于C类。那本该属于这个模型的数据呢?


图12:离散点检测模型在icml(A类)测试集上的预测结果
顶死算是60%,就是说离散点模型和逻辑回归模型的分类效果恰好反了过来,逻辑回归模型把大部分文章归为了A类,而离散点检测模型将大部分数据归为了C类文章。
换用个A类会议:
NIPS,神经信息处理系统大会,是一个关于机器学习和计算神经科学的国际会议。该会议固定在每年12月举行,NIPS是机器学习领域的顶级会议。在中国计算机学会的国际学会会议排名中,NIPS为人工智能领域的A类会议。
介绍完了会议,看下预测结果吧。


效果说是惨不忍睹也不足为过,在测试的数据集方面,已尽可能的选择内容相似的文章进行测试了,但仍旧分不出来好的效果。换句话说,我的理解上分类器给数据打的数据标签,根本就不是我们认为的A类和C类的逻辑标签,而仅仅是文章内容上的差异度,与等级无关。
2.3可视化
放弃web服务器的搭建,使用python标准库tkinter,设计简单GUI进行模型预测的可视化。

图13:GUI界面
从icml测试集中拿出一条数据进行测试:

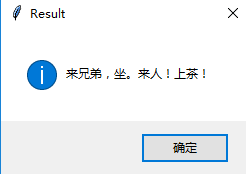

图14:icml测试集可视化展示
acml测试集中拿出一条数据进行测试:



图15:acml数据集可视化展示
3结果分析及总结:
此问题最开始的目的旨于让分类器学习出会议文章的类别(或者说是级别),但在实现的过程中,发现无论什么模型,都没办法很好的将类别特征学习出来。
换种思维来想,换做人来做判断,我们会根据什么来判断文章的类别?
1.难度。读不懂的那些就是A类,差不多知道说什么的就是C类。问题交给计算机,怎样让它理解什么是懂的,什么是不懂的?
2.理解性。一个本来不懂的知识,看完一篇文章后,有了一种顿悟的感觉。好文章,A类。一个本来不懂得知识,看完一篇文章后,想撕书。不知所言,思维混乱,还有了新的问题。差评,C类。问题交给计算机,怎么让他知道什么是“顿悟”的感觉?如果以学习到新数据就算的话,那差劲到语句不通的文章肯定让计算机获得了新的数据呀。
而且反过来看,这两种方法的还互相矛盾着,1看不懂的是A,2里乱七八糟看不懂的就成了C。
虽然文本的向量表示上不具有很好的可解释性,但我们仍旧可以确定的一点就是空间向量点的表示中包含着文本里词与词之间的关系,而不是将文本中的每个词孤立出来表示的向量。话句话说,向量表示是文本内容,而我们却想让它能够分别出文章的好坏。两个问题的水平就完全不对等了。文章的好坏不是能够从语言上反应出来的。
回到模型训练方面,我们希望空间向量点表示的是文章的类别,测试数据的向量点离某一类的距离越近,我们就认为属于这一类的可能性越高。
但是向量表示的是文章内容,距离上的靠近,只能说明两篇文章内容上的相似,而没办法说明两篇文章属于一个级别。
再换种想法,如果C类和A类不同,那对于A+类。它和A相似度低,和C类相似度同样低,该划分到哪一类?因为在空间向量上,并没有显示出来类别的顺序,分类器并不知道哪一块空间上的点比A类文章的等级高,哪一块空间上的点比A类文章的等级低。因为在空间点的距离上能显示出来的只有离A类很远罢了。

例如,在思维逻辑上我们认为B比A差,应该分到C类里面,而A+比A还优秀,应当分到A类中。但在数据表示上A+和B对于A没有区别,因为距离差不多,两类与A的相似性也就被认为是一样的了。
以上为数据处理整个流程及思考。
参上。
