在gensim的主题模型中,直接集成了doc2vec模块,其中一个重要的例子就是情感分类的。对应的项目主页为:https://linanqiu.github.io/2015/10/07/word2vec-sentiment/。
1、Doc2Vec的简单介绍
Word2vec已经非常成熟并且得到了众多的运用,推动了深度学习在自然语言处理领域取得了巨大进展。在word2vec的基础上,来自google的Quoc Le和Tomas Mikolov在2014年提出了Doc2Vec模型,该模型能够实现对段落和文档的嵌入式表示,原始论文地址如下:https://cs.stanford.edu/~quocle/paragraph_vector.pdf。
其架构如下所示:
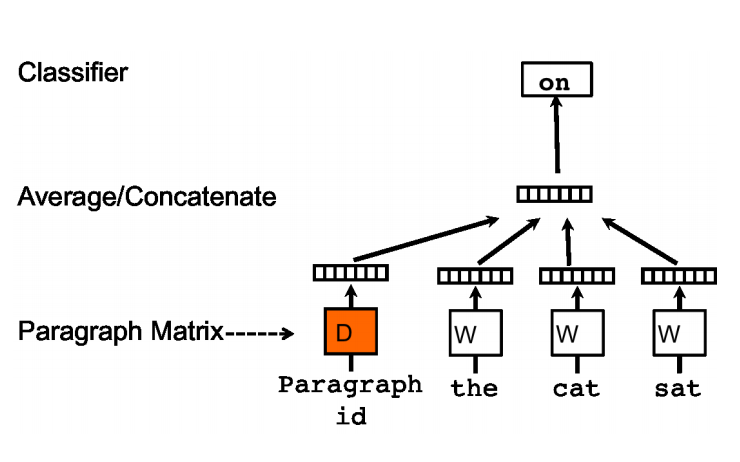
在上图中,可见其与word2vec的区别在于加了一个paragraph id的输入。即每个段落/句子都被映射到向量空间中,可以用矩阵D的一列来表示。每个单词同样被映射到向量空间,可以用矩阵W的一列来表示。然后将段落向量和词向量级联或者求平均得到特征,预测句子中的下一个单词。这个段落向量/句向量也可以认为是一个单词,它的作用相当于是上下文的记忆单元或者是这个段落的主题,这种训练方法被称为Distributed Memory Model of Paragraph Vectors(PV-DM)
其代码也非常简洁,主要由三行组成:
1、调用doc2vec
2、建立词汇表
3、开始训练。
sources = {'test-neg.txt':'TEST_NEG', 'test-pos.txt':'TEST_POS', 'train-neg.txt':'TRAIN_NEG', 'train-pos.txt':'TRAIN_POS', 'train-unsup.txt':'TRAIN_UNS'}
log.info('TaggedDocument')
sentences = TaggedLineSentence(sources)
log.info('D2V')
model = Doc2Vec(min_count=1, window=10, size=100, sample=1e-4, negative=5, workers=7)
model.build_vocab(sentences.to_array())
model.train(sentences.sentences_perm(), epochs=model.iter, total_examples=model.corpus_count)
# log.info('Epoch')
# for epoch in range(10):
# log.info('EPOCH: {}'.format(epoch))
# model.train(sentences.sentences_perm())注:代码在新版的gensim中,无需用for epoch的方式来训练,如果用了这种方法会报错如下:
You must specify either total_examples or total_words, for proper job parameters updation
直接利用如下语句则可解决这种问题。
model.train(sentences.sentences_perm(), epochs=20, total_examples=model.corpus_count)
2、实验结果
当设置epochs为5的时候,可以见到其准确率约为82.6%

而设置epochs为20的时候,可以见到其准确率约为85.6%