文章目录
1.容器化思维
- 容器的本质是一个进程以及运行该进程所需要的各种依赖,我们不需要去备份一个容器,而是应该把需要备份的数据放在容器外挂的volume里或者数据库里。
- 若要进入容器,进行程序调试的话:
docker exec -it <containerName> bash
-
Docker的日志管理方法
(1)在容器内收集
(2)在容器外收集
(3)在专用容器只能收集 -
通过veth pair连接两个network namespace
缺点:如果有更多的network namespace需要连接,那就要引入虚拟网桥
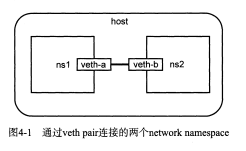
如闪图4-1进行配置,过程如下:
都是在主机上输入:
(1)创建两个network namespace ns1,ns2
ip nets add ns1
ip nets add ns2
(2)创建veth pair设备veth-a,veth-b
ip link add veth-a type veth peer name veth-b
(3)将网卡分别放置到两个namespace中
ip link set veth-a nets ns1
ip link set veth-b nets ns2
(4)启动2张网卡
ip nets exec ns1 ip link set veth-a up
ip nets exec ns2 ip link set veth-b up
(5)分配IP
ip netns exec ns1 ip addr add 10.0.0.1/24 dev veth-a
ip netns exec ns2 ip addr add 10.0.0.2/24 dev veth-b
(6)验证
ip nets exec ns1 ping 10.0.0.2
2.如何将容器连接到本机?
- (1)要使容器和容器主机处于同一个网络,那么容器和主机应该处在一个二层网络中。即:把两台机器连接到同一个交换机或者连在不同的级联的交换机上
- (2)在虚拟网桥中,可以将容器连在一个二层网络中,只要将主机的网卡桥接到虚拟网络中,就能将容器和主机的网络连接起来
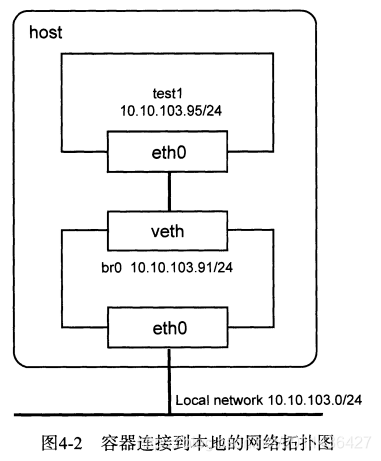
目标:test1容器可以与本地主机相互访问,并且容器可以通过本地网络的网关
10.10.103.254访问外部网络。
如上图所示:本地网络为10.10.103.0/24,网关是:10.10.103.254
主机ip:10.10.103.91/24,网卡为eth0
容器test1:需要配置的ip:10.10.103.95/24
(1)启动一个名为test1的Docker容器
docker run -itd --name test1 --net-none ubuntu /bin/bash
(2)创建一个供容器连接的网络br0
brctl addr br0
ip link et br0 up
(3)将主机的eth0桥接到br0,并把eth0的ip配置在br0上,由于是远程操作,
会导致网络断开,因此放在一条命令中执行
ip addr add 10.10.103.91/24 dev br0;\
ip addr del 10.10.103.91/24 dev eth0;\
brctl addif br0 eth0;\
ip route del default;\
ip route add default via 10.10.103.254 dev br0
(3)找到test1的PID,保存到pid中
pid=$(docker inspect --format '{{ .State.Pid }}' test1)
将容器的network namespace添加到/var/run/nets目录下
mkdir -p /var/run/netns
ln -s /proc/$pid/ns/net /var/run/netns/$pid
(4)创建用于连接网桥和Docker容器的网卡设备
将veth-a连接到br0网桥中
ip link veth-a type veth peer name veth-b
brctl addif br0 veth-a
ip link set veth-a up
(5)将veth-b放到test1的network namespace中,命名为eth0,并为
其配置IP和默认路由
ip link set set veth-b netns $pid
ip netns exec $pid ip link set dev veth-b name eth0
ip netns exec $pid ip link set eth0 up
ip netns exec $pid ip addr add 10.10.103.95/25 dev eth0
ip netns exec $pid ip route add default via 10.10.103.254
- pipework:容器的SDN解决方案,可以在复杂场景下将容器连接起来 ,功能主要有:
(1)支持Linux网桥连接容器并配置容器IP地址
(2)支持使用macvlan设备将容器连接到本地网络
(3)支持DHCP获取容器的IP
(4)支持Open vSwitch
(5)支持设置网卡MAC地址以及配置容器VLAN
3. pipework跨主机通信:桥接方式
- (1)为了隔离Docker容器间的网络和主机网络,需要额外使用一块网卡桥接Docker容器。
思路:在所有主机上用虚拟网桥将本机的Docker容器连接起来,然后将一块一块网卡加入到虚拟网络中,使所有主机上的虚拟网桥级联在一起,这样,不同主机上的Docker容器也就如同连在了一个大的逻辑交换机上。 - (2)为解决不同机器上的Docker容器可能获得相同的IP地址,解决办法是:为每一台主机上的Docker daemon指定不同的–fixed-cidr参数,将不同主机上的Docker容器的地址限定在不同的网段中。
- (3)eg如下,如图4-3
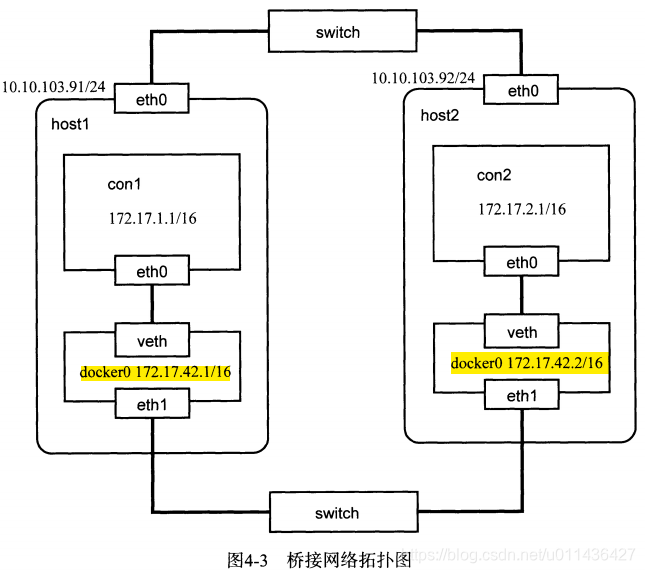
两台Ubuntu的主机host1和host2,每台主机上有两块网卡eth0和eth1.
两个主机的主网卡eth0连在主机的局域网环境中,IP分别为:
10.10.103.91/24和10.10.103.92/24.
两个主机的网卡eth1用来桥接不同主机上的Docker容器,因此eth1不需要配置IP。
host1主机上的docker0的IP为172.17.42.1/16,其IP范围限制在172.17.1.0/24
host2主机上的docker0网桥地址修改为172.17.42.2/16,其IP范围限制在172.17.2.0/24网段,然后将eth1桥接到
docker0中。
具体配置:
(1)在host1上的操作(暂时):
echo ‘DOCKER_OPTS="--fixed-cidr=172.17.1.1/24"' >> /etc/default/docker
service docker stop
service docker start
将eth1网卡接入到docker0网桥
brctl addif docker0 eth1
(2)在host2上的操作(暂时)
echo ‘DOCKER_OPTS="--fixed-cidr=172.17.2.1/24"' >> /etc/default/docker
为了避免和host1上的docker0的IP冲突,修改docker0的ip
ifconfig docker0 172.17.42.2/16
service docker stop
service docker start
将eth1网卡接入到docker0网桥
brctl addif docker0 eth1
or:
在host2上的操作(永久):写入/etc/network/interfaces目录下
auto docker0
iface docker0 inet static
address 172.17.42.2
netmask 255.255.0.0
bridge_ports eth1
bridge_stp off
bridge_fd 0
(3)两个主机上分别创建容器,并用nc测试
host1操作:
docker run -it --rm --name con1 ubuntu /bin/bash
进入容器操作:
ifconfig eth0
route -n
在主机操作:nc -l 172.17.1.1 9000
host2操作:
docker run -it --rm --name con2 ubuntu /bin/bash
进入容器操作:
ifconfig eth0
nc -w 1 -v 172.17.1.1 9000
总结:
(1)桥接方式:是将所有主机上的Docker容器放在一个二层网络中,他们之间的
通信是由交换机直接转发,不通过路由器。
(2)数据从容器从con1:172.17.1.1——>容器con2:172.17.2.1
查看本身的路由表发现目的地址和自己处于同一网段,那么就不需要发往网关,
con1通过ARP广播获取到con2的MAC地址;
构造以太网帧发往con2即可;
docker0网桥充当普通的交换机转发数据帧,数据流经的路径如图4-3中两个容器
的eth0网卡所连接的路径
(3)该例子不同主机的容器在同一子网,但是主机在同一个子网
4.pipework跨主机通信:直接路由
- (1)为了避免不同主机上的Docker容器使用相同的IP,所以应该为不同的主机分配不同的IP子网。
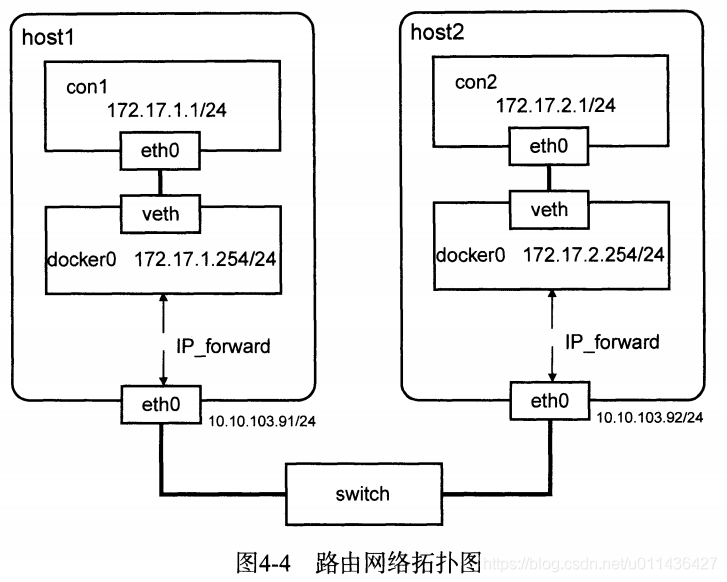
- (2)eg:如图4-4
命令如下:
两台主机host1,host2,每台主机有1块网卡。
host1的IP地址为:10.10.103.91/24,Docker容器在172.17.1.0/24子网中
host2的IP地址为:10.10.103.92/24,Docker容器在172.17.2.0/24子网中
路由规则:所有目的地址为172.17.1.0/24的包都被转发至host1,
目的地址为172.17.2.0/24的包都被转发至host2
(1)在host1主机上操作
ifconfig docker0 172.17.1.254/24
service docker restart
添加路由规则:目的地址为172.17.2.0/24的包都被转发至host2
route add -net 172.17.2.0 netmask 255.255.255.0 gw 10.10.103.92
配置iptables
iptables -t nat -F POSTROUTING
iptables -t nat -A POSTROUTING -s 172.17.1.0/24 ! -d 172.17.0.0/16 -j MASQUEREAD
docker run -it --name con1 ubuntu /bin/bash
在con1容器中:
nc -l 9000
(2)在host2上操作
ifconfig docker0 172.17.2.254/24
service docker restart
添加路由规则:目的地址为172.17.1.0/24的包都被转发至host1
route add -net 172.17.1.0 netmask 255.255.255.0 gw 10.10.103.91
配置iptables
iptables -t nat -F POSTROUTING
iptables -t nat -A POSTROUTING -s 172.17.2.0/24 ! -d 172.17.0.0/16 -j MASQUEREAD
docker run -it --name con2 ubuntu /bin/bash
在con2容器中:
nc -w 1 -v 172.17.1.1 9000
总结:
(1)该例子不同主机的容器在不在一子网,但是主机在同一个子网
(2)从con1发往con2的包,首先发往con1的网关docker0:172.17.1.254,
然后通过查看主机的路由的路由得知,要将包发给host2:10.10.103.92,包
到达host2后,再转发给host2的docker0:172.17.2.254,最后达到容器con2中
(3)与桥接网络的区别:
桥接网络中,所有主机上的容器都在172.17.0.0/16这个大网中,这从docker0的
IP:172.17.42.1/16可以看出。
在直接路由的方法中,不同主机上的Docker容器不在同一个网络中,他们有不同的
网络号。
host1的docker0的ip是从host1的docker0上获取的;
桥接网络是二层通信,通过MAC地址转发;
直接路由为三层通信,通过IP地址进行路由转发。
(4)(了解即可)启动Docker daemon时会创建下面的iptables规则:用于容器与外界通信
-A POSTROUTING -s 172.17.0.0/16 ! -o docker0 -j MASQUEREAD
从con1发往con2的包,在主机eth0转发出去时,这条规则会将包的源地址改为
eth0地址:10.10.103.91,so,con2看到包是从10.10.103.91发过来的
5.单主机Docker容器的VLAN划分
- 在交换机中划分子网,,隔离广播域的思路形成了VLAN
- VLAN(Virtual Local Area Network)即:虚拟局域网,把一个大型交换网络划分为许多个独立的广播域
- 在多租户的云环境中,VLAN是一个最基本的隔离手段。
- 多交换机VLAN划分的eg:如下图4-5
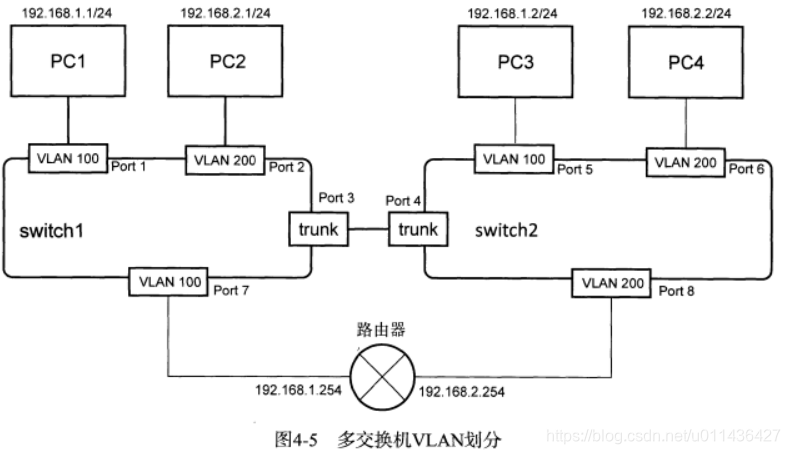
(1)PC1和PC3属于VLAN100,PC2和PC4属于VLAN200,所以PC1和PC3处于同一个二层网络,PC2和PC4处于同一个二层网络
Por1,2,5,6,7,8属于access端口,经过access端口的数据包会被打上tag标签;
当数据帧从交换机内部通过access端口发送时,数据帧的VLAN ID和access端口的VLAN ID一致,access端口才接收此帧
(2)PORT3,4为trunk端口,trunk端口是交换机和交换机之间的多个VLAN通道,表明只允许带有这些VLAN ID的数据帧可以通过
- 单主机Docler容器的VLAN划分如下:
Docker默认网络下,所有的容器都连在docker0网桥上,docker0网桥是普通的Linux网桥,不支持VLAN功能
eg如下:
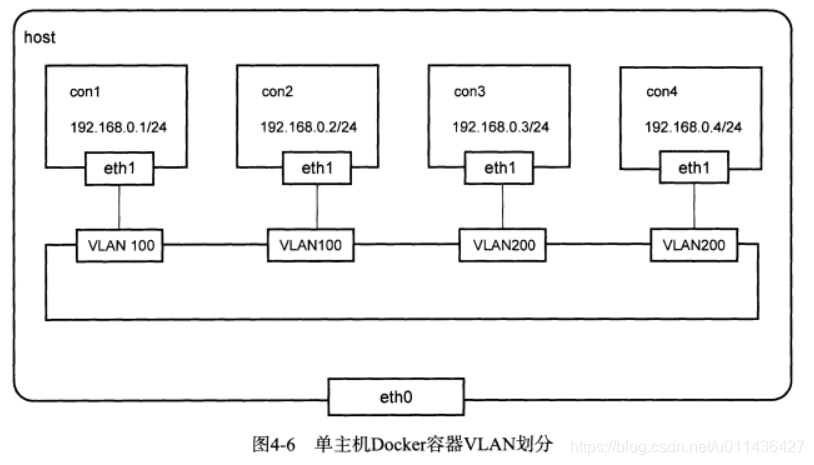
为了方便操作,使用Open vSwitch代替docker0进行VLAN划分
上述的四个容器都在同一个IP网段中,但是实际上它们是二层隔离的两个网络,属于不同的广播域
(1)在主机A上操作
在主机A上创建四个容器
docker run -itd --name con1 ubuntu /bin/bash
docker run -itd --name con2 ubuntu /bin/bash
docker run -itd --name con3 ubuntu /bin/bash
docker run -itd --name con4 ubuntu /bin/bash
用pipework将con1,con2划分到一个VLAN中
pipwork ovs0 con1 192.168.0.1/24 @100
pipwork ovs0 con2 192.168.0.2/24 @100
用pipework将con3,con4划分到一个VLAN中
pipwork ovs0 con3 192.168.0.3/24 @100
pipwork ovs0 con4 192.168.0.4/24 @100
pipework配置完成后,每个容器都多了一块eth1网卡,eth1连在ovs0网桥上,并且进行了VLAN的隔离
con1和con2可以通信,但无法与con3或者con4通信
pipework就是将veth pair的一端加入到ovs0网桥,但不需要trunk端口
6.多主机Docker容器的VLAN划分
- 多主机VLAN划分的前提是跨主机通信
- eg:如下图4-7

(1)大致方法:
用桥接的方式将所有容器连接在一个逻辑交换机上,再根据具体的情况进行VLAN的划分;
桥接需要将主机的一块网卡桥接到容器所连接的Open vSwitch网桥上,即需要一块额外的网卡eth1
这里,将不同VLAN的容器设在同一个子网中,仅仅是为了演示隔离的效果
con1和con3属于VLAN100;
con2和con4属于VLAN200;
物理交换机上连接host1和host2的端口应设置为trunk端口;
两个主机的eth1没有设置VLAN限制
(2)具体如下:
在host1上:
socker run -itd --name con1 ubuntu /bin/bash
docker run -itd --name con2 ubuntu /bin/bash
pipework ovs0 con1 192.168.0.1/24 @100
pipework ovs0 con2 192.168.0.2/24 @200
ovs-vsctl add-port ovs0 eth1;
在host2上:
socker run -itd --name con3 ubuntu /bin/bash
docker run -itd --name con4 ubuntu /bin/bash
pipework ovs0 con1 192.168.0.3/24 @100
pipework ovs0 con2 192.168.0.4/24 @200
ovs-vsctl add-port ovs0 eth1;
说明:主机在同一个子网
7.多租户下的Overlay网络简介
- (1)pipework跨主机通信,桥接和直接路由的方式必须保证主机在同一个子网中。 eg:若两个数据中心的Docker容器需要通信时,这种方法就会失效
- (2)Overlay网络就是隧道技术,就是将一种网络协议包装在另一种协议中传输的技术。 eg:如果有两个使用IPv6的站点之间需要通信,而它们之间的网络使用IPv4协议,此时,就需将IPv6的数据包装在IPv4中传输。
- (3)当前的Overlay技术由:VXLAN和NVGRE
- (4)在普通的网络传输中,源IP地址和目的IP地址是不变的,而二层的帧头在每个路由器节点上都会改变,这是TCP/IP协议的规定。
- (5)用于封装传输数据的协议有一个类似VLAN ID的标识,以区分不同的隧道。如图4-8

8.GRE实现Docker容器跨网络通信(容器在同一个子网)
- 如何才能使两个办公地点相互通信?
由于两个地点的主机都处在NAT转化之下,so,两地的主机并不能直接进行ping或者ssh操作。通过在双方路由器上配置GRE隧道就可以实现。 - 要求:路由器要配置一个GRE隧道的网卡设备。eg:GRE协议封装的是IP包,实现了一个VPN的功能。
- GRE实现Docker容器跨网络通信eg,如图4-12
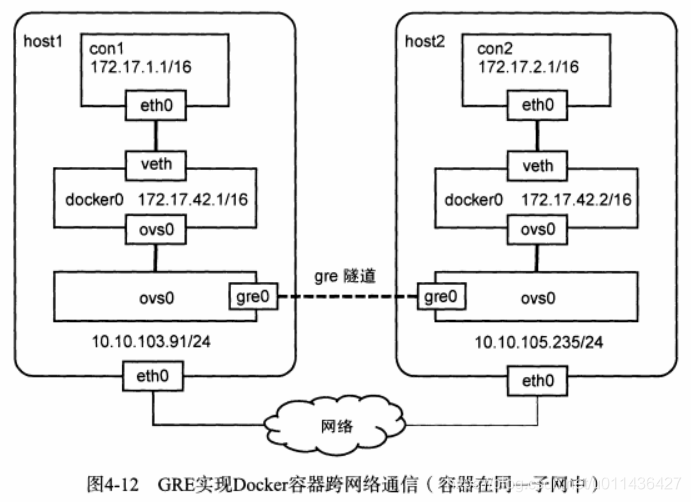
目前普遍的方法是结合Open vSwitch虚拟交换机;
两台主机处在不同的网络中;
host1的IP为10.10.103.91/24,host2的IP为10.10.105.235/24
为了解决两台主机上IP地址冲突问题,使用--fixedicidr参数对容器的IP进行限制;
ovs0为Open VSwitch网桥,用来创建GRE隧道,并于docker0网桥相连;
(1)在host1操作:
echo 'DOCKER_OPTS="--fixed-cidr=172.17.1.1/24"'>>/etc/default/docker
service docker restart
创建ovs0,并与docker0相连
ovs-vsctl add-br ovs0
brctl addif docker0 ovs0
在ovs0上创建GRE隧道
ovs-vsctl add-port ovs0 gre0 -- set interface gre0 type=gre options:remote_ip=10.10.105.235
(2)在host2上操作:
echo 'DOCKER_OPTS="--fixed-cidr=172.17.2.1/24"'>>/etc/default/docker
避免与host1的docker0的ip冲突,修改
ifconfig docker0 172.17.42.2/16
service docker restart
创建ovs0,并与docker0相连
ovs-vsctl add-br ovs0
brctl addif docker0 ovs0
在ovs0上创建GRE隧道
ovs-vsctl add-port ovs0 gre0 -- set interface gre0 type=gre options:remote_ip=10.10.103.91
(3)验证
在host1上操作:
docker run -it --rm --name con1 ubuntu /bin/bash
在容器中操作:
nc -l 172.17.1.1 9000
在host2上操作:
docker run -it --rm --name con1 ubuntu /bin/bash
在容器中操作:
nc 172.17.1.1 9000
(4)说明:
尽管不同主机上的容器IP有不同的范围,但是它们还是属于同一个子网(172.17.0.0/16)
9.GRE实现Docker容器跨网络通信(容器在不同的子网)
- eg:如图4-13
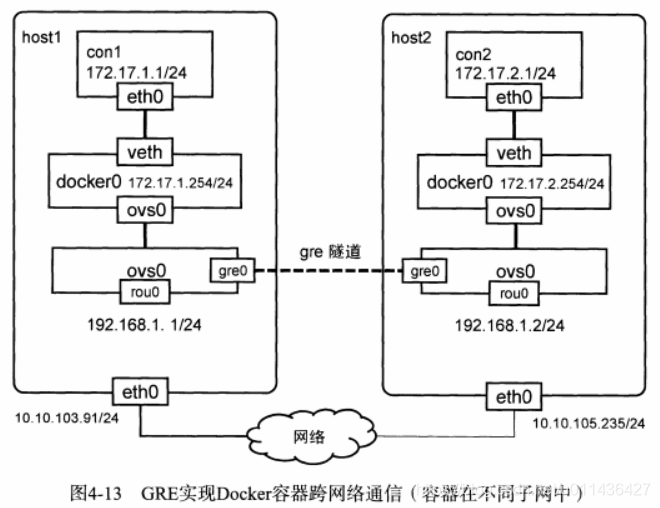
使用Open vSwitch的隧道模式;
host1:10.10.103.91/24,con1:172.17.1.0/24
host2:10.10.105.235/24,con2:172.17.2.0/24;
由于两台主机不再同一个子网中,容器间通信不能再使用直接路由的方式,而需依赖Open vSwitch建立的GRE隧道
(1)host1设置
使得Docker容器的IP在172.17.1.0/24网络中
ifconfig docker0 172.17.1.254
service docker restart
将ovs0连在docker0上
ovs-vsctl add-br ovs0
brctl addif docker0 ovs0
在ovs0上创建一个internal类型的端口rou0,并分配一个私有IP
ovs-vsctl add-port ovs0 rou0 -- set interface rou0 type=internal
ifconfig rou0 192.168.1.1/24
将Docker容器的流量路由到rou0
rout add-net 172.17.0.0/16 dev rou0
创建GRE隧道
ovs-vsctl add-port ovs0 gre0 -- set interface gre0 type=gre options:remote_ip=10.10.103.91
删除Docker创建的iptables规则
iptables -t nat -D POSTROUTING -s 172.17.1.0/24 ! -o docker0 -j MASQUEREAD
创建自己的规则
iptables -t nat -A POETROUTING -A 172.17.0.0/16 -o eth0 -j MASQUEREAD
(2)host2设置
使得Docker容器的IP在172.17.2.0/24网络中
ifconfig docker0 172.17.2.254
service docker restart
将ovs0连在docker0上
ovs-vsctl add-br ovs0
brctl addif docker0 ovs0
在ovs0上创建一个internal类型的端口rou0,并分配一个私有IP
ovs-vsctl add-port ovs0 rou0 -- set interface rou0 type=internal
ifconfig rou0 192.168.1.1/24
将Docker容器的流量路由到rou0
rout add-net 172.17.0.0/16 dev rou0
创建GRE隧道
ovs-vsctl add-port ovs0 gre0 -- set interface gre0 type=gre options:remote_ip=10.10.105.235
删除Docker创建的iptables规则
iptables -t nat -D POSTROUTING -s 172.17.2.0/24 ! -o docker0 -j MASQUEREAD
创建自己的规则
iptables -t nat -A POETROUTING -A 172.17.0.0/16 -o eth0 -j MASQUEREAD
(3)验证:
在host1上:
docker run -it --name con1 ubuntu /bin/bash
在容器中
nc -l 9000
在host2上:
docker run -it --name con2 ubuntu /bin/bash
在容器中
nc -w 1 -v 172.17.1.1 9000
- 该网络模型与K8S类似,此处将一个容器视作为一个pod
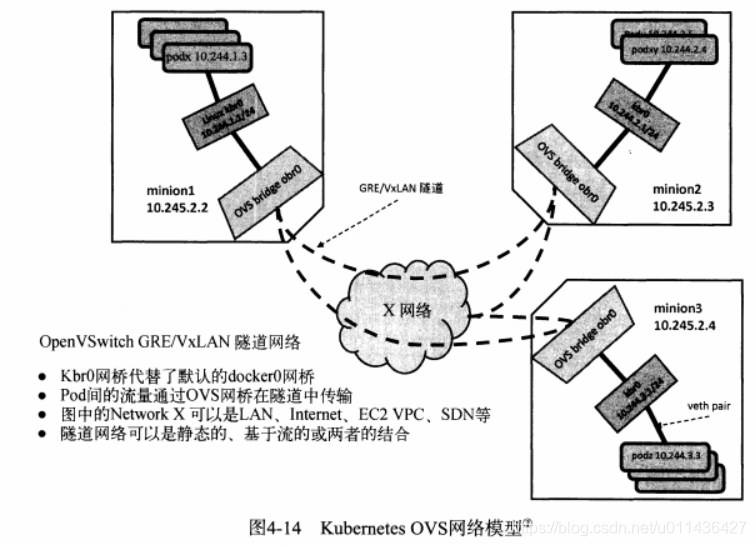
10.OpenStack的GRE网络模型介绍
- Overlay网络在虚拟化场景下除了实现虚拟机之间的跨网络通信外,还可以填补VLAN的不足,满足多用户的隔离的需求
- eg:如图4-15
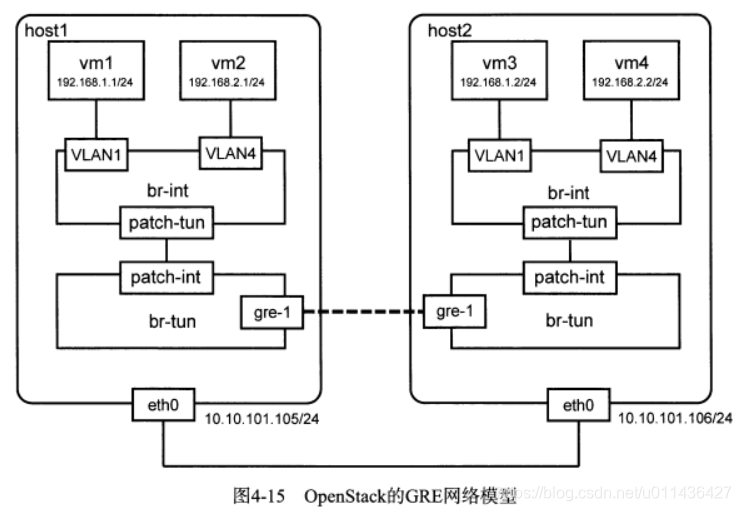
如图是OpenStack集群中的两台计算节点的网络连接图
每台主机有两台虚拟机,vm1和vm3属于租户A,处在一个子网;
vm2和vm4属于租户B,处在一个子网中。
4个vm都连在br-int网桥上,且有vlan标识,vm1和vm3的vlan id=1,vm2和vm4的vlan id=4
br-int是Open vSwitch交换机,它依据MAC地址和VLAN ID转发数据;
br-tun是隧道网桥,它依据流表来转发数据
11.Dockerfile最佳实践
- Dockerfile是Docker用来构建镜像的文本,包含自定义的指令和格式。
- docker build命令从Dockerfile中构建镜像,这个过程与传统分布式集群的编排配置过程很相似,且提供了一系列统一的资源配置语法。用户可以用统一的语法命令,通过统一的配置文件,可以在不同的平台上分发,使用时,还可以根据配置文件进行自动化构建。
- Dockerfile与镜像配合使用,使Docker在构建时,可以充分利用镜像的功能进行缓存
- Dockerfile实践心得
(1)给镜像打上标签,docker build -t =“ruby:2.0-on build”
(2)谨慎选择基础镜像
(3)尽量将Dockerfile文件中相同的都放在前面,而将不同的部门放在后面
(4)使用RUN curl来获取远程URL中的压缩包,这样可以删除解压后不再需要的文件,并且不需要在镜像中再添加一层;
尽量使用docker volume共享文件,而不是使用ADD或者COPY指令添加文件到镜像中;
(6)为了避免缓存问题,RUN apt-get update && apt-get install -y package-bar package-foo package-baz;
如果需要更新一个包eg:foo,直接使用指令:RUN apt-get install -y foo
在Docker中,镜像之间有层级关系,像一棵树。我们可以在任一层建立一个容器。so,不要将所有的命令写在一个RUN指令中(很像源码控制)。
(7)不要在Dockerfile中做端口映射
因为Docker的核心概念是:可重复性和可移植性。端口映射应在docker run命令中用-p参数指定。
(8)使用Dockerfile共享Docker镜像,Dockerfile文件可以加入版本控制
12.Docker容器的监控手段
(1)
查看当前的运行的容器信息
docker ps
-a参数可以列出已停止的所有容器的信息
docker ps -a
(2)
列出所有顶层镜像的信息
docker images
查看所有中间层的镜像的信息
docker images -a
(3)docker stats只有在选用libcontainer作为执行驱动时,才可以使用
容器状态信息统计:包括CPU,内存,块设备IO,网络IO
docker stats redis-master
开发者可以使用stats API将容器的运行状态信息传递到自己构建的应用中,以实现容器的系统监控
stats API(GET/containers/(id)/stats)
echo -e "GET /containers/redis-slave1/stats HTTP/1.0\r\n\" | nc -U /var/ryn/docker.sock
(4)查看镜像或容器的底层详细信息
了解镜像或容器的完整构建信息,包括:基础配置,主机配置,网络设置,状态信息等
-f参数:设定输出格式
docker inspect -f {{.NetworkSettings.IPAddress}} 9bec172.17.0.2
(5)查看正在运行的容器中的进程的运行情况
docker top 9bec
(6)
查看容器与主键之间的端口映射关系
docker port bc0a
- 常用的容器监控工具
(1)Google cAdvisor:监控应用
在启动cAdvisor后,它会在后台运行,并暴露8080端口,用户可以访问:http://localhost:8080来查看cAdvisor
还支持输出状态信息到InfluxDB数据库进行存储和读取;
支持将容器的统计信息以Prometheus标准指标形式输出,并存储在指定的/metrics HTTP服务端点,以便通过Prometheus应用
来查看cAdvisor;还提供了丰富的API接口服务cAdvisor Remote RESET API
(2)Datadog:监测云端应用
利用Docker所使用的内核结构cgroups获取Docker的性能指标
(3)Prometheus
是一个开源服务监控系统和时间序列数据库;
使用Prometheus时,一般结合container-exporter使用,其可以收集以libcontainer为执行驱动的容器的各类性能指标,并将
数据提供给Prometheus使用;
13.实现服务发现、服务发布与订阅的关键技术:高可用配置中心etcd
-
etcd
(1)是键值存储仓库,用于配置共享和服务发现
(2)特点:基于HTTP+JSON的API,用curl命令就可以轻松使用;可选SSL客户认证机制;每个实例每秒支持1千次写操作;使用Raft算法充分实现了分布式
(3)etcd主要解决的是分布式系统中的数据一致性的问题,而分布式系统中的数据分为控制数据(数据量小但更新访问频繁)和应用数据 -
etcd场景1:服务发现
(1)在同一个分布式集群中的进程或服务,互相感知并建立连接,这就是服务发现。eg:了解集群中是否有进程在监听UDP或TCP端口,并通过对应的字符串信息就可以进行查找和连接
(2)解决服务发现问题的三大支柱:
一个强一致性,高可用的额服务存储目录;
一种注册服务和监控服务健康状态的机制;
一种查找和连接服务的机制;
eg1:服务提供者在服务发现仓库注册,服务请求者在仓库中查找,最后通过查找的细节进行连接。

eg2:在etcd中注册某个服务名字的目录,在该目录下存储可用的服务节点的IP。
eg以Docker为承载的前端在服务发现目录中查找可用的中间件,中间件再找到服务后端,以此快速构建起一个动态和高可用的架构
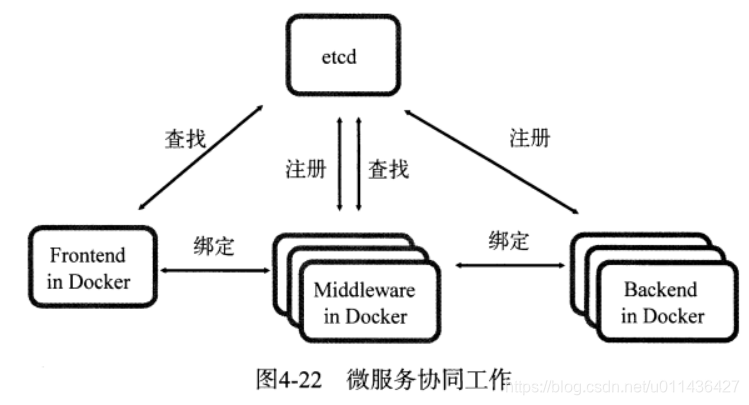
eg3:应用中的某个实例随时都有可能故障重启,此时,通过etcd的服务发现功能可以解决动态配置问题:动态地配置域名解析(路由)中的信息
-
etcd场景2:消息发布与订阅
(1)在分布式系统中,最合适的组件间通信方式是消息发布与订阅机制
(2)构建一个配置共享中心,需要什么?
数据提供者:在这个配置中心发布消息;
消息使用者: 订阅 他们关心的主题,一旦相关主题有消息发布,就会实时通知订阅者 -
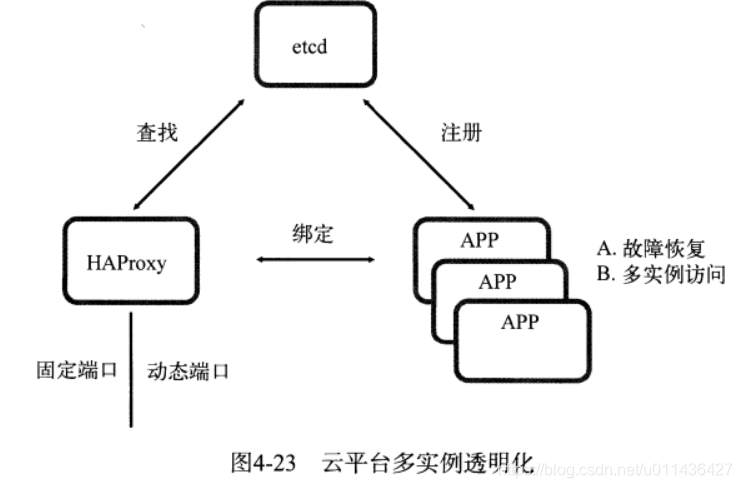
etcd场景3:负载均衡
(1)在分布式系统中, 为了保证服务的高可用以及数据的一致性,通常会部署多份数据和服务,以此来达到对等服务
(2)实现数据访问时的负载均衡,可将用户的访问流量分流到不同的机器上 -
etcd场景4:分布式通知与协调
(1)与消息发布与订阅类似
(2)不同系统都在etcd上对同一个目录进行注册,同时设置Watcher监控该目录的变化,当某个系统更新了etcd的目录,那么设置了Watcher的系统就会收到通知(异步通知),并作出相应的处理 -
etcd场景5:分布式锁与竞选
(1)etcd使用Raft算法保持了数据的全局强一致性,因此要实现分布式锁。
(2)分布式的锁服务有两种实现方式:
保持独占:所有试图获取锁的用户最终只有一个可以得到,etcd实现了一套分布式锁原子操作CAS(CompareAndSwap)的API。在多个节点同时创建某个目录时,只有一个能成功,该用户即可认为是获得了锁
控制时序:即所有视图获取锁的用户都会进入等待队列,获取锁的顺序是全局唯一的,同时决定了队列的执行顺序。
(3)分布式锁完成Leader竞选: 对于长时间的CPU计算或者I/O操作,只需要由竞选出的Leader计算处理一次,再把结果复制给其它的Follower即可,节省计算资源。 -
etcd场景6:分布式队列
(1)与分布式锁的控制时序用法类似,即创建一个先进先出的队列,保证顺序
(2)其他方式:在保证队列到达某个条件时,再统一按顺序执行 -
etc场景7:集群监控
(1)Watcher机制:当某个节点消失或者有变动时,Watcher机制会第一时间发现并告知用户
(2)设置TTL key,心跳来判断该节点是否存活 -
etcd vs ZooKeeper
(1)etcd:go语言,简单,使用HTTP作为接口;使用raft算法;数据一更新就会进行持久化;
(2)ZooKeeper:Java语言实现,部署复杂;Paxos强一致性算法难;只提供Java和C两种语言的接口;
