概述
什么是容器?
容器是用于盛放元素的
由于盛有许多的元素,容器都是可以迭代遍历的
最常用的容器包括【元组】、【列表】、【字典】、【集合】等
字符串是有序字符集,本质上也是容器
我们在对比和讨论容器的特性时,最常考虑的因素有:
1、是否有序
2、是否可重复
3、如何访问其中的元素
4、是否可以编辑
5、如何遍历
第一节:字符串
字符串操作符
+,用于字符串连接*,用于多次重复
例如:
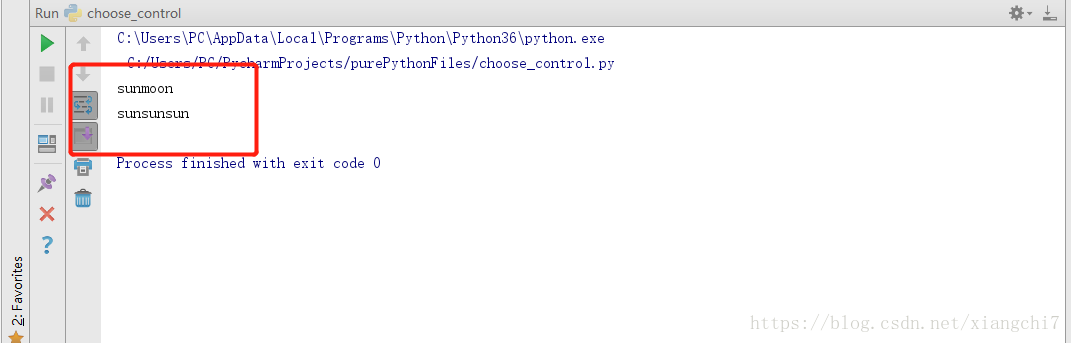
words = "sun"
words2 = "moon"
print(words + words2)
print(words * 3)
执行结果:
字符串长度
如果我们想知道一段字符串到底有多长,可以用len()进行查看,而不是一个一个数
例:
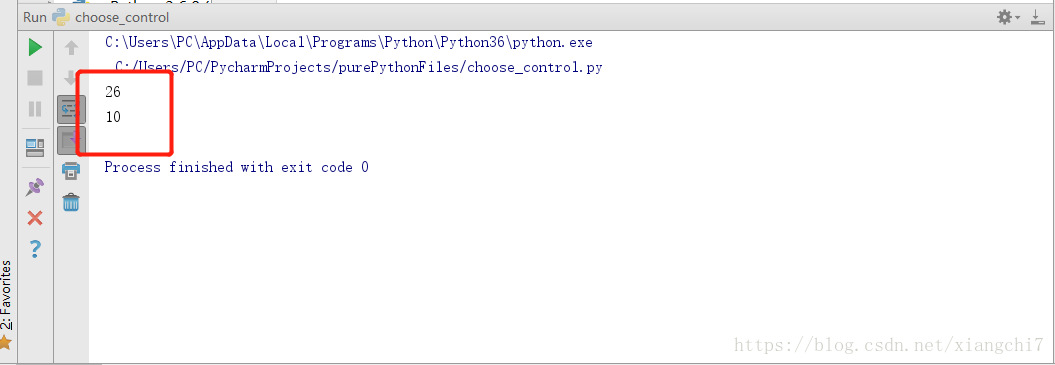
#这里有26个字母,或者更多时,使用len()
words = "abcdefghijklmnopqrstuvwxyz"
print(len(words))
#字符串的长度,包含了空格在内
words2 = "I love you"
print(len(words2))
执行结果:
比较字符串大小
字符串之间的比较,是按当前字符集中序号的顺序排列,前小后大
print("abc" > "def") # False,按当前字符集中序号的顺序排列
print("中国" > "美帝") # False,按当前字符集中序号的顺序排列
字符串截取(切片)
字符串[开始位置:结束位置:步长]
开始结束位置的原则是:含头不含尾,即结束位置的那个字符不会被截取
步长2代表每2个取第一个,3代表每三个取第一个
步长为-N时,代表从后向前截取,仍然是每N个取一个
例如:
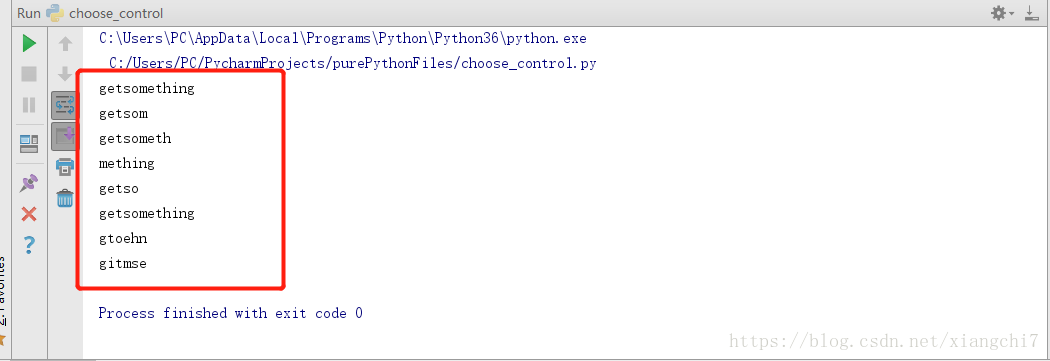
mstr = "getsomething"
# 从0载取到总长度(最后)
print(mstr[0:len(mstr)])
#从0截取到第5位(注意含头不含尾,所以以6做结束)
print(mstr[0:6])
#从0截取到倒数第4位
print(mstr[0:-3])
#从第5位截取到最后
print(mstr[5:])
#从0截取到第4位
print(mstr[:5])
#从头截到尾
print(mstr[:])
#从0截取到最后,步长为2
print(mstr[0::2])
#从头截到尾,步长为-2
print(mstr[::-2])
执行结果:
判断有无子串
- 使用
in关键字可以判断子串是否在大串中 - 使用
find函数返回子串出现的位置,如子串不存在则返回-1 - 使用
index函数同样返回子串位置,但子串不存在就会报错
例如:
mstr = "天下武功唯快不破"
#"武功"是否在mstr里面
print("武功" in mstr) # True
#"武术"是否在mstr里面
print("武术" in mstr) # False
#在mstr里寻找"不破"
print(mstr.find("不破")) # 6
#在mstr里寻找"武术"
print(mstr.find("大破")) # -1
#在mstr里出现""武功的下标是?
print(mstr.index("武功")) # 2
print(mstr.index("武术")) #此方法找不到会报错
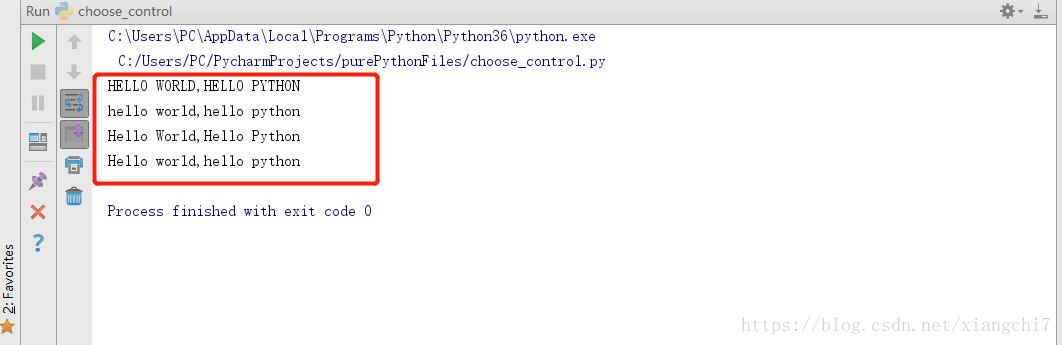
字符串的格式化
capitalize(),首字母大写title(),每个单词的首字母大写lower(),全小写upper(),全大写
例如:
mStr = "hello world,hello python"
#字母全大写
print(mStr.upper())
#字母全小写
print(mStr.lower())
#所有单词首字母大写
print(mStr.title())
#仅开头首字母大写
print(mStr.capitalize())
执行结果:
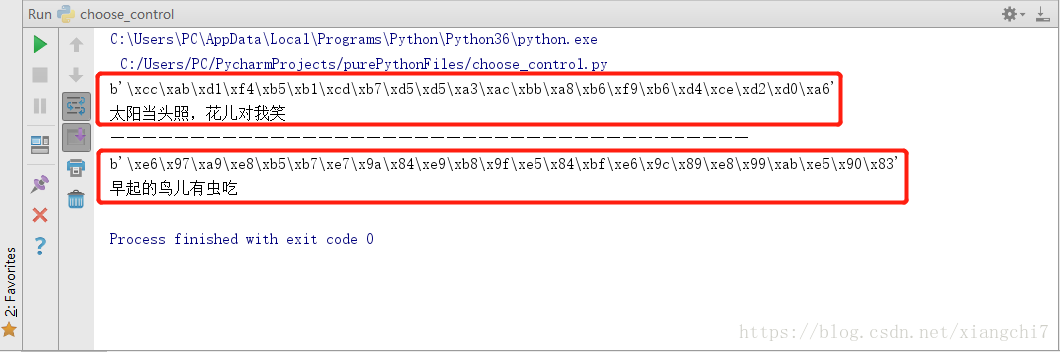
编码解码
encode(),编码为字节decode(),将字节解码为字符串,注意主语是字节而非字符串
例如:
#例1
words = "太阳当头照,花儿对我笑"
#以gbk字符集编码将字符串编码为字节数组
wordBytes = words.encode(encoding="gbk")
print(wordBytes)
#以gbk字符集编码将字节数组解码为字符串
turnBytes = wordBytes.decode(encoding="gbk")
print(turnBytes)
print("——"*20)#此处只为分隔
例2:
words2 = "早起的鸟儿有虫吃"
#以utf-8字符集编码将字符串编码为字节数组
wordBytes2 = words2.encode(encoding="utf-8")
print(wordBytes2)
#以utf-8字符集编码将字节数组解码为字符串
turnBytes2 = wordBytes2.decode(encoding="utf-8")
print(turnBytes2)
执行结果:
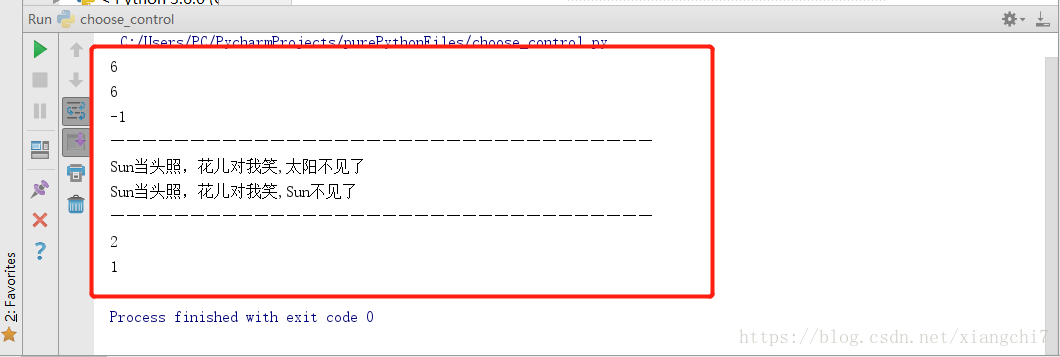
搜索与替换
find(),寻找子串位置,没有返回-1index(),寻找子串位置,没有报错count(),统计子串出现次数replace(),替换子串为新的字符串
例如:
mStr = "太阳当头照,花儿对我笑,太阳不见了"
#搜索“花儿”的位置
print(mStr.find("花儿"))
#搜索出现“花儿”的下标
print(mStr.index("花儿"))
#搜索“flower”的位置,-1表示子串不存在
print(mStr.find("flower"))
#搜索出现“flower”的下标位置,注意当子串不存在,将会报错,而不是返-1
# print(mStr.index("flower")) # ValueError: substring not found
print("——————————————————————————————————")#此处只为分隔
#将“太阳”替换为Sun,替换1处
print(mStr.replace("太阳", "Sun", 1))
#将全部“太阳”替换为“Sun”
print(mStr.replace("太阳", "Sun")) # fuck world,fuck python 全部hello替换为fuck
print("——————————————————————————————————")#此处只为分隔
#数一数子串“太阳”出现的次数
print(mStr.count("太阳"))
#在0-6位字符中,子串“太阳”出现的次数
print(mStr.count("太阳", 0, 6)) # 1 hello子串出现的次数,范围为0-6位字符
执行结果:
判断头尾与数字
isdigit(),判断是否为数字子串startswith(),判断是否以子串开头endswith(),判断是否以子串结尾
例如:
words = "太阳当头照,花儿对我笑"
words2 = "3145926"
#判断words是不是数字字符串
print(words.isdigit()) # False
#判断words2是不是数字字符串
print(words2.isdigit()) # True
#判断words是不是以“太阳”子串开头
print(words.startswith("太阳")) # True
#判断words是不是以“Sun”子串开头
print(words2.startswith("Sun")) # False
#判断words是不是以“笑”子串结尾
print(words.endswith("笑")) # True
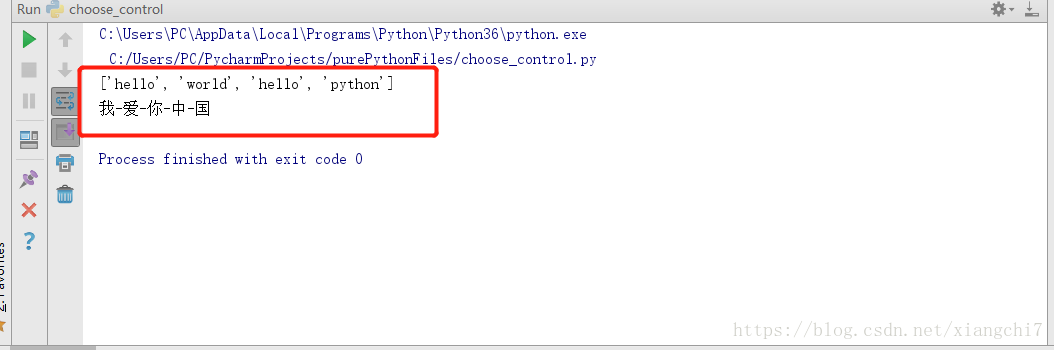
拆开与重组
split(“,”),以逗号切分子串,形成一个列表join(),用分隔符连接子串,主语为分隔符,参数为字符串
例如:
words = "hello,world,hello,python"
#将字符串words用“,”分割成四个字符串
print(words.split(","))
words2 = "我爱你中国"
#将字符串打散为字符,并以-连接形成新字符串
print("-".join(words2))
执行结果:
第二节:元组
元组的特点
- 元组是一种
有序、不可编辑的元素容器; - 可以通过
下标访问元组中的元素; - 其它迭代器对象(如列表、字符串等)可以通过类型强转转换为元组对象;
创建元组
- 通过
( )直接赋值创建 - 将多个值赋值给一个变量,则该变量是元组类型
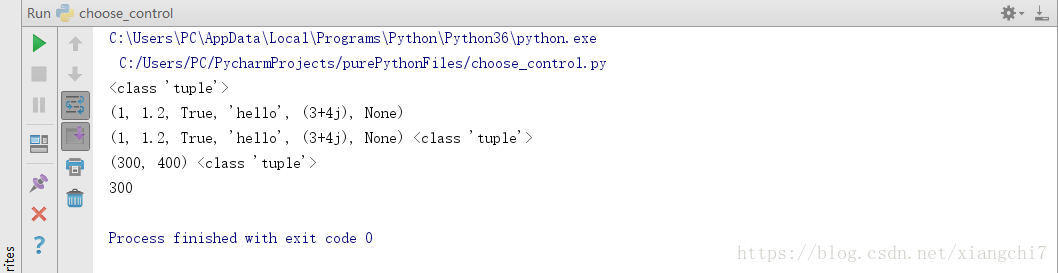
例:
#直接使用括号可创建元组
mtuple = ()
print(type(mtuple))
#元组可以通过括号直接赋值,值的类型可以多样化(整形、浮点型、字符串、复数等)
mtuple2 = (1, 1.2, True, "hello", 3 + 4j, None)
print(mtuple2)
#将多个值赋值给一个变量,则该变量是元组类型
ytuple = 1, 1.2, True, "hello", 3 + 4j, None
print(ytuple,type(ytuple))
#指定变量个数形成的元组,可直接找到指定变量
ytuple2 = width, height = 300, 400
print(ytuple2,type(ytuple2))
print(width)
执行结果:
下标访问元素
mtuple = ("dog", "cat", "bird", "fish", "panada", "bear")
# 元组通过使用“[]”和下标进行访问
print(mtuple[2]) # bird
print(mtuple[-1]) # bear
# 遍历元组
for i in mtuple:
print(i)
元组不可编缉
元组不可以对里面的元素进行修改或删除,但可以删除整个元组
mtuple = ("dog", "cat", "bird", "fish", "panada", "bear")
# mtuple[1] = "apple"
print(mtuple) # 报错,元组不可编辑
#删除元组
del mtuple
print(mtuple) # 报错,元组已经不复存在了!NameError: name 'mtup' is not defined
元组的操作
+,连接两个元组为一个大元组
*,将元组元素重复多次
in,判断元组中是否包含某元素
例如:
#两个元组进行相加
print((1, 2, 3) + (4, 5, 6)) # (1, 2, 3, 4, 5, 6)
#元组乘以2
print((1, 2, 3) * 2) # (1, 2, 3, 1, 2, 3)
#判断2是否在元组中
print(2 in (1, 2, 3)) # True
#判断-2是否在元组中
print(-2 in (1, 2, 3)) # False
截取元组(切片)
截取方式:元组对象
[开始位置:结束位置:步长]
开始结束位置的原则是:含头不含尾,即结束位置的那个字符不会被截取
步长2代表每2个取第一个,3代表每三个取第一个
步长为-N时,代表从后向前截取,仍然是每N个取一个
mtuple = ("dog", "cat", "bird", "fish", "panada", "bear")
#截取第3-5位(含头不含尾,所以5要向后一位)
print(mtuple[3:6]) # ('fish', 'panada', 'bear')
#截取第3-倒数第2位
print(mtuple[3:-1]) # ('fish', 'panada')
#截取第3往后的所有
print(mtuple[3:]) # ('fish', 'panada', 'bear')
#截取开头-倒数第3位
print(mtuple[:-2]) # ('dog', 'cat', 'bird', 'fish')
#从头到尾的所有
print(mtuple[:]) # ('dog', 'cat', 'bird', 'fish', 'panada', 'bear')
#从头到尾的所有中,每2取1
print(mtuple[::2]) # ('dog', 'bird', 'panada')
#从头到尾的所有中,每-2取1
print(mtuple[::-2]) # ('bear', 'fish', 'cat')
相关函数
len(mtuple),求元组长度max(mtuple),求元组中的最大值min(mtuple),求元组中的最小值tuple(iterable),将其它迭代器对象转换为元组
例如:
mtuple = (0, 1, 2, 3)
#元素的长度
print(len(mtuple)) # 4
#元素的最大值
print(max(mtuple)) # 3
#元素的最小值
print(min(mtuple)) # 0
#将列表转换为元组
print(tuple([5, 6, 7, 8])) # (5, 6, 7, 8)
#将字符串中的字符打散为元组
print(tuple("hello")) # ('h', 'e', 'l', 'l', 'o')
第三节:列表
列表的特点
- 列表是
可编辑的、有序、可重复的元素集 - 列表中的元素是可以动态
增删和修改的 - 列表的元素通过
下标进行访问
创建列表
- 一般创建
- 推导式创建
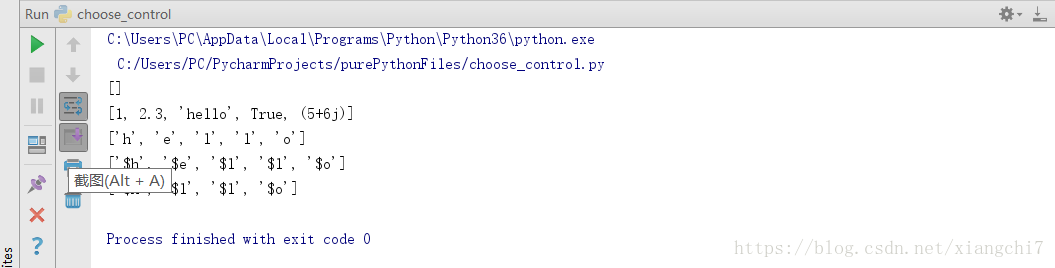
例如:
#普通创建
mlist = [] # 创建了一个空列表,里面没有元素
print(mlist)
ylist = [1, 2.3, "hello", True, 5 + 6j] # 直接赋初值创建,里面有5个元素,元素类型也是多样的
print(ylist)
# 推导式创建
alist = [c for c in "hello"]
print(alist)
blist = ["$" + c for c in "hello"]
print(blist)
clist = ["$" + c for c in "hello" if c != "e"]
print(clist)
执行结果:
下标访问元素
mlist =["dog", "cat", "bird", "fish", "panada", "bear"]
#列表的长度
print(len(mlist)) # 6
#通过“[]”和下标访问列表中的元素
print(mlist[1]) # cat
列表的编缉、遍历与删除
删除时注意有两种方法
- 使用
del——此方法直接从内存中删除列表,不复存在 - 使用
clear——此方法会让列表为空列表
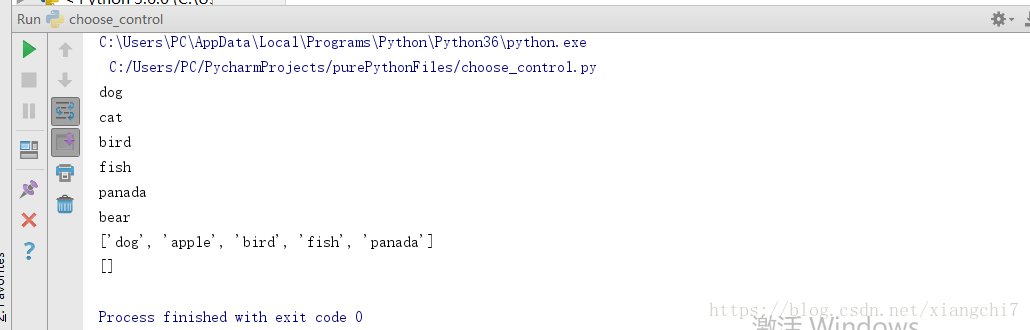
例如:
mlist = ["dog", "cat", "bird", "fish", "panada", "bear"]
#对列表进行遍历
for i in mlist:
print(i)
#对列表进行编缉
mlist[1] = "apple"
del mlist[5]
print(mlist)
#删除列表
# del mlist
mlist.clear()
print(mlist)
执行结果:
列表的操作
列表的操作符与元组相同
+,连接两个列表为一个大列表
*,将元组元素重复多次
in,判断列表中是否包含某元素
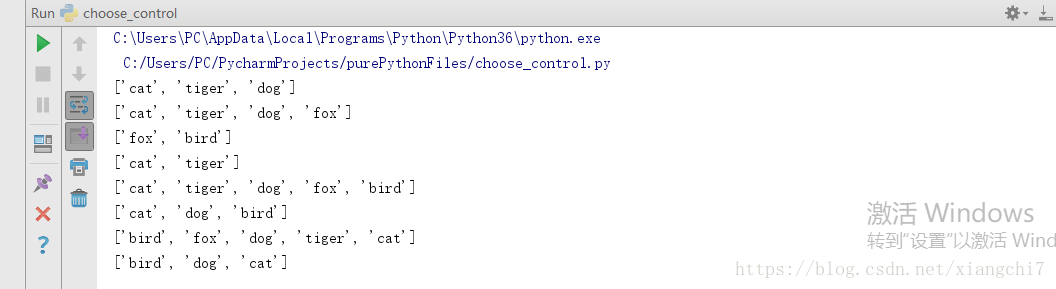
例如:
list1 = ["cat","tiger","dog","fox","bird"]
list2 = ["老鼠","大水牛","小兔子"]
#两个列表进行相加
print(list1+list2) # ['cat', 'tiger', 'dog', 'fox', 'bird', '老鼠', '大水牛', '小兔子'
#列表乘以2
print(list2*2) # ['老鼠', '大水牛', '小兔子', '老鼠', '大水牛', '小兔子']
#判断是否在列表中
print("cat" in list1) # True
print("大蟒蛇" in list2) # False
截取列表(切片)
列表的截取与元组相同
list1 = ["cat","tiger","dog","fox","bird"]
# 截取结果含头不含尾
#截取下标从0-2
print(list1[0:3])
#截取下标从0-倒数第2
print(list1[0:-1])
#截取下标从3-最后
print(list1[3:])
#截取下标从开头-倒数第4
print(list1[:-3])
#截取下标从头到尾
print(list1[:])
#截取下标从头到尾,每2取1
print(list1[::2])
#截取下标从头到尾,每-1取1
print(list1[::-1])
#截取下标从头到尾,每-2取1
print(list1[::-2])
执行结果:
相关函数
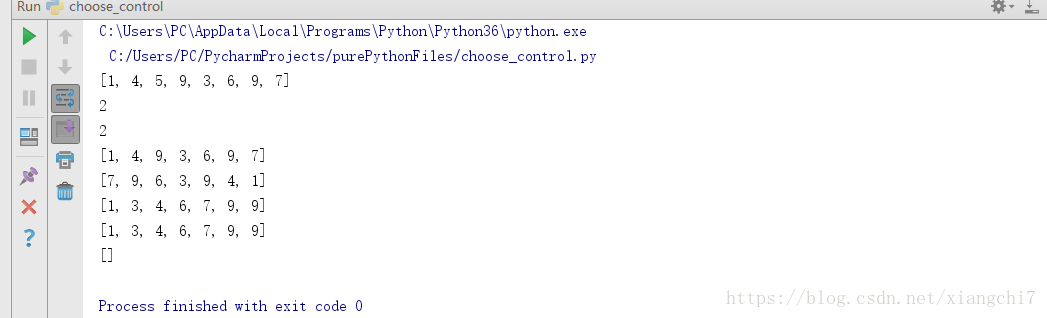
append(),插入一个元素count(),统计元素出现的个数index(),返回元素下标pop(index),弹出并返回指定下标的元素remove(index),移除指定的元素reverse(),将列表逆序sort(),列表排序copy(),拷贝列表clear(),清空列表
用法:
numbs = [1,4,5,9,3,6,9]
#插入一个元素
numbs.append(7)
print(numbs)
#统计某元素出现的次数
print(numbs.count(9))
#元素找出下标
print(numbs.index(5))
#移除指定的元素
numbs.remove(5)
print(numbs)
#将列表逆序
numbs.reverse()
print(numbs)
#列表排序
numbs.sort()
print(numbs)
#拷贝列表
print(numbs.copy())
#清空列表
numbs.clear()
print(numbs)
执行结果:
第四节:集合
集合的特点
- 集合是
无序、不重复的元素容器,用set()表示 - 由于无序,集合
无法通过下标访问 - 集合不重复的特性,常常用于进行
去重操作
创建集合
- 普通创建
- 推导式创建
例如:
#普通创建
# 创建空的集合,
mset = set()
print(mset)
# 直接赋值创建集合(无序)
yset = {1, 2.3, "4", complex(5, 6), False, None} # True==1,False==0
print(yset) # {{False, 1, 2.3, None, (5+6j), '4'}
# 推导式创建集合
iset = {i for i in range(1, 6)}
print(iset) #{1, 2, 3, 4, 5}
aset = {i for i in range(2, 11, 2)} # 从2-10间每二取一
print(aset) #{2, 4, 6, 8, 10}
# 推导式创建集合+ 条件过滤
bset = {i for i in range(2, 11) if i % 2 == 0}
print(bset) #{2, 4, 6, 8, 10}
#注意,这结果是字符串的相加,“i”必须也是字符串
cset = {"$" + str(i) for i in range(2, 11) if i % 2 == 0}
print(cset) #{'$6', '$8', '$4', '$10', '$2'}
# 打散字符串形成集合
eset = {i for i in "hello"}
print(eset) #{'h', 'e', 'l', 'o'}
# 推导式创建:遍历字符串 + 条件过滤
dset = {i for i in "hello world hello python" if i != "o"}
print(dset) #{'w', 'p', 't', 'n', 'l', 'y', ' ', 'r', 'd', 'h', 'e'}
集合的操作
&求交集|求并集-求差集(B集后没有的元素)^求异同集in判断是否在集合中
mset1 = {1, 2, 3, 4, 5}
mset2 = {4, 5, 6, 7, 8}
# 集合操作符
print(mset1 & mset2) # 交集
print(mset1 | mset2) # 并集
print(mset1 - mset2) # mset1有,而mset2没有的数
print(mset1 ^ mset2) # mset1没有或mset2没有
#判断是否在集合中
print(1 in mset1) # True
print(-1 in mset2) # False
相关函数
set(iterable)可迭代对象转为集合sorted()排序clear()清空
例如:
#将可迭代对象转化为集合
mset = set([1,3,2,5,4])
print(mset) # {1, 2, 3, 4, 5}
yset = {1,5,8,3,6,2}
#排序(排后变成列表)
print(sorted(yset)) # [1, 2, 3, 5, 6, 8]
# 以下三行等效于sorted(yset):先转化为列表再对列表排序
mlist = list(yset)
mlist.sort()
print(mlist) # [1, 2, 3, 5, 6, 8]
#清空集合
yset.clear()
print(yset) # set()
第五节:字典
字典的特点
- 字典用于
存储键值对数据 - 访问时根据
键去访问值 - 字典是
可以编辑的,包括增删键值对,修改键对应的值 - 字典的遍历,通常是通过字典类方法
items()来进行遍历的,每个item既包含了键又包含了值
创建字典
例如:
# 创建空字典
mdict = {}
print(mdict) # {}
ydict = dict()
print(ydict) # {}
# 赋值创建
adict = {"牛奶": 3.5, "巧克力": "5元3盒", "购物袋": "免费"}
print(type(adict)) # <class 'dict'>
print(adict) # {'牛奶': 3.5, '巧克力': '5元3盒', '购物袋': '免费'
键访问元素的值
字典访问通过键去访问值
例如:
# 访问字典
mdict = {"牛奶": 3.5, "巧克力": "5元3盒", "购物袋": "免费"}
print(mdict["牛奶"]) # 3.5
print(mdict["购物袋"]) # 免费
# 访问并不存在的键,报KeyError
# print(mdict["冰红茶"]) # KeyError: '冰红茶'
字典的编缉、遍历与删除
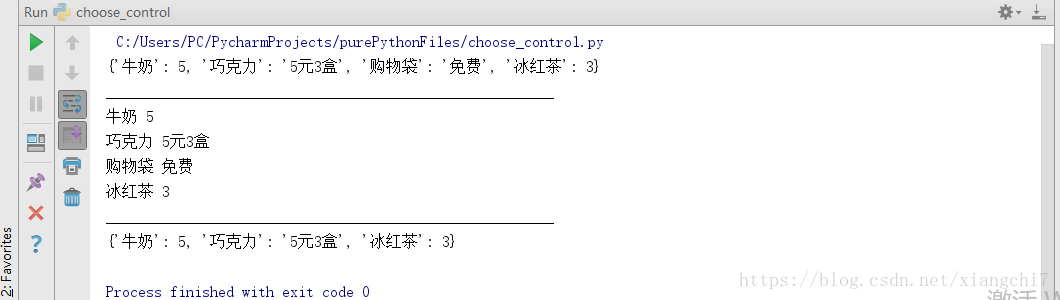
例:
# 字典的编缉(更新)
mdict = {"牛奶": 3.5, "巧克力": "5元3盒", "购物袋": "免费"}
# 修改元素值
mdict["牛奶"] = 5
#添加新的元素
mdict["冰红茶"] = 3
print(mdict)
print("________________________________________________________")
# 字典的遍历
for k, v in mdict.items():
print(k, v)
print("________________________________________________________")
del mdict["购物袋"] # 删除一个元素(键值对)
print(mdict)
# 删除整个字典
del mdict
执行结果:
相关函数
- 內建函数
len(mdict),获得键值对个数
str(mdict),将字典转化为纯字符串(类似于json字符串) - 字典函数
copy(),拷贝字典
formkeys(),由一堆键快速生成字典,值先填充为默认
items(),得到用于遍历的所有键值对
keys(),得到所有键
values(),得到所有值
setdefault(“key”, None),设置键的默认值,没有这个键就设置一个默认值,有这个键则什么都不做
update(dict2),以dict2为蓝本更新数据
pop(),弹出一个指定的键值对
popitem(),弹出最后一个键值对
clear(),清空字典
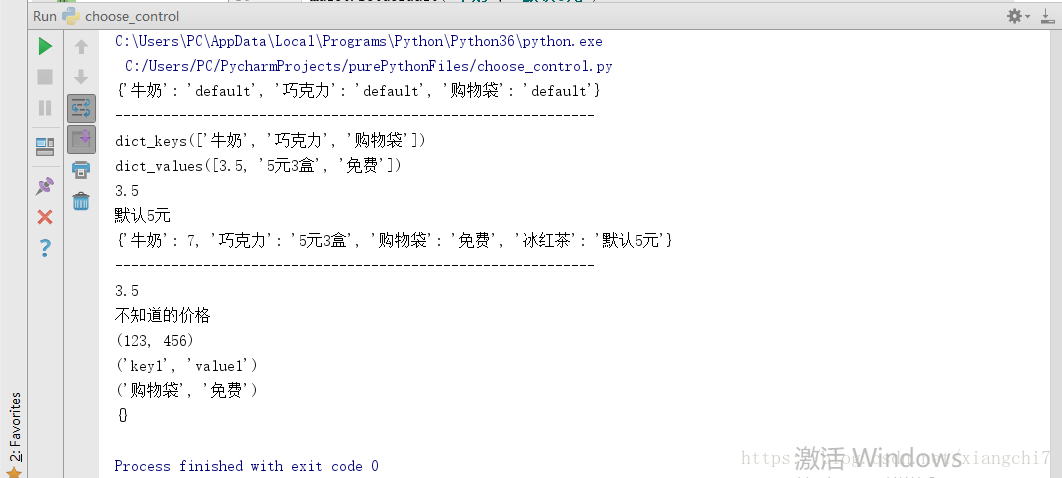
例如:
# 参数1("牛奶","巧克力","购物袋")=键集
# 参数2"default"=所有键的默认值
newDict = dict.fromkeys(("牛奶", "巧克力", "购物袋"), "default")
print(newDict)
print("------------------------------------------------------------")
mdict = {"牛奶": 3.5, "巧克力": "5元3盒", "购物袋": "免费"}
#字典中的键集
print(mdict.keys())
#字典中的值集
print(mdict.values())
# 为键设置缺省值(如果该键值对不存在,则创建并赋值为默认值,如果存在则不做任何改动)
mdict.setdefault("牛奶", "默认5元")
mdict.setdefault("冰红茶", "默认5元")
print(mdict["牛奶"]) #值并未变动
print(mdict["冰红茶"]) #创建了新的键值
# 以mdict2为基准更新mdict,发现mdict中count的值变为和mdict2相同了
mdict2 = {"牛奶": 7}
mdict.update(mdict2)
print(mdict)
print("------------------------------------------------------------")
adict = {"牛奶": 3.5, "巧克力": "5元3盒", "购物袋": "免费", "key1": "value1", 123: 456}
# 弹出并删除一个值,默认为"不知道的价格"
print(adict.pop("牛奶", "不知道的价格")) #弹出了个已有的键,并获取它的值
print(adict.pop("冰红茶", "不知道的价格")) # 弹出一个不存在的键,值就为默认值
# 从尾部逐个弹出,item呈元组的形式
print(adict.popitem())
print(adict.popitem())
print(adict.popitem())
# 清空字典
adict.clear()
print(adict)
执行结果:
第六节:容器的扩展
定长参数与变长参数
变长参数使用"*_"
例:
x,*_,z = 1,2,3,4,5
print(*_) # 2 3 4
a,b,c = (5,6,7)
print(a,b,c) # 5 6 7
字典中添加元素
+——列表的相加extend()——兼并另一个可迭代对象append()——末尾追加单个元素insert()——插入某个元素
例如:
a = [1,2,3]
b = [4,5]
c = (6,7)
d = "hello"
#列表兼并另一个列表(即列表的相加)
a += b
print(a) # [1, 2, 3, 4, 5]
#列表兼并另一个可迭代对象(可以是列表,也可以是元组等)
#注意:如果兼并的是字符串,则会把字符串视为可迭代对象
a.extend(c)
print(a) # [1, 2, 3, 4, 5, 6, 7]
#列表末尾追加单个元素
a.append(d)
print(a) # [1, 2, 3, 4, 5, 6, 7, 'hello'
#在指定位置插入某个元素
a.insert(0,"begin")
print(a) # ['begin', 1, 2, 3, 4, 5, 6, 7, 'hello']
浅拷贝
copy()
a = [1,2,["a","b"]]
b = a
print(b)
print("------------------------------------------------------")
#浅拷贝,拷贝之后是另外的东西,c不再是a,或b,只是值相同
c = a.copy()
print(c)
#虽然整体地址不同,但元素地址还是相同
print(id(a),id(a[0]),id(a[1]),id(a[2]))
print(id(c),id(c[0]),id(c[1]),id(c[2]))
print("------------------------------------------------------")
#对a或c的元素进行编缉,不会影响对方,元素是基本类型
a.insert(0,3)
print(a,c)
#对a或c的元素内的元素进行编缉,则会影响对方,元素内的元素是对象类型
a[-1].append(4)
print(a,c)
执行结果:
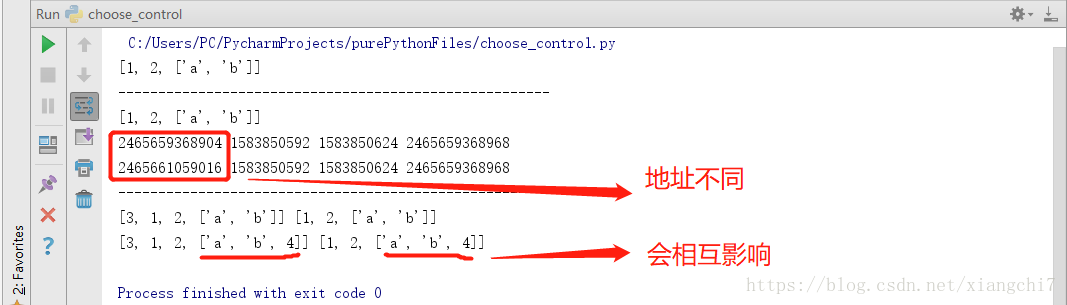
总结:
基本类型的传参,是值拷贝
对象类型的传参,是地址引用
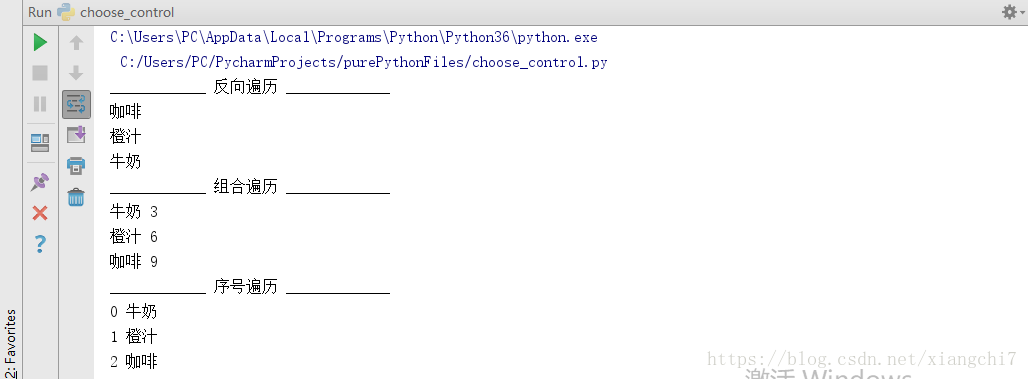
花式遍历列表
reversed()——反向遍历zip()——组合遍历enumerate()——序号遍历
例如:
mlist = ["牛奶","橙汁","咖啡"]
ylist = [3,6,9]
print("____________ 反向遍历 _____________")
alist = reversed(mlist)
for i in alist:
print(i)
print("____________ 组合遍历 _____________")
for m,y in zip(mlist,ylist):
print(m,y)
print("____________ 序号遍历 _____________")
for x,i in enumerate(mlist):
print(x,i)
执行结果:
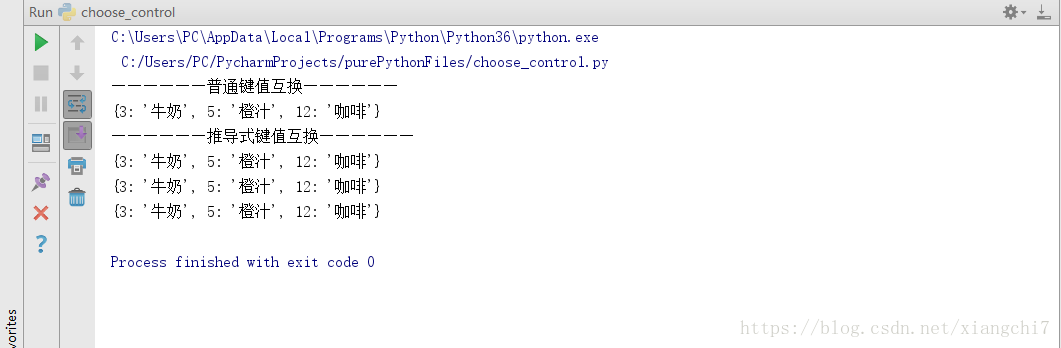
字典的键值互换
- 普通键值互换
- 推导式键值互换
例如:
d = {"牛奶":3,"橙汁":5,"咖啡":12}
print("——————普通键值互换——————")
dic = {}
for k,v in d.items():
dic[v]=k
print(dic)
print("——————推导式键值互换——————")
#方法一:推导式+元组转字典
print(dict([(v,k) for k,v in d.items()]))
#方法二:推导式+字典
print({v:k for k,v in d.items()})
#方法三:推导式+组合遍历+字典
print({v:k for k,v in zip(d.keys(),d.values())})
#方法四:推导式+组合遍历+元组转列表+列表转字典
print(dict([(v,k) for k,v in zip(d.keys(),d.values())]))
执行结果:
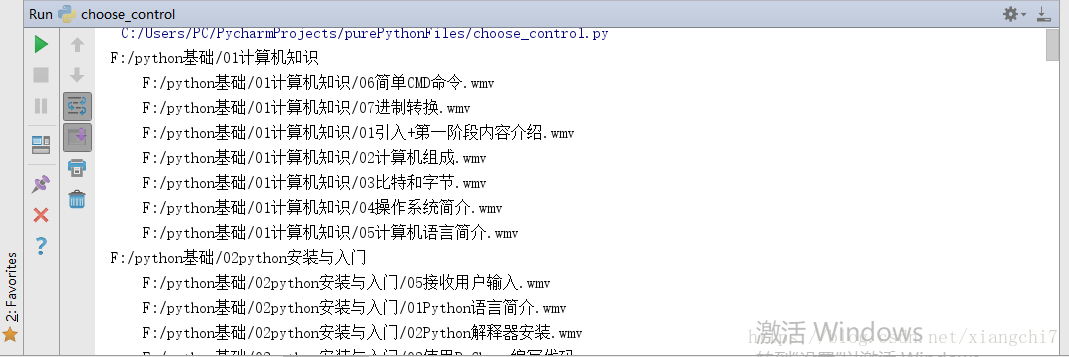
第七节:深广遍历
深度遍历(递规实现)
import os
from tkinter import filedialog
#基于递规的深度遍历
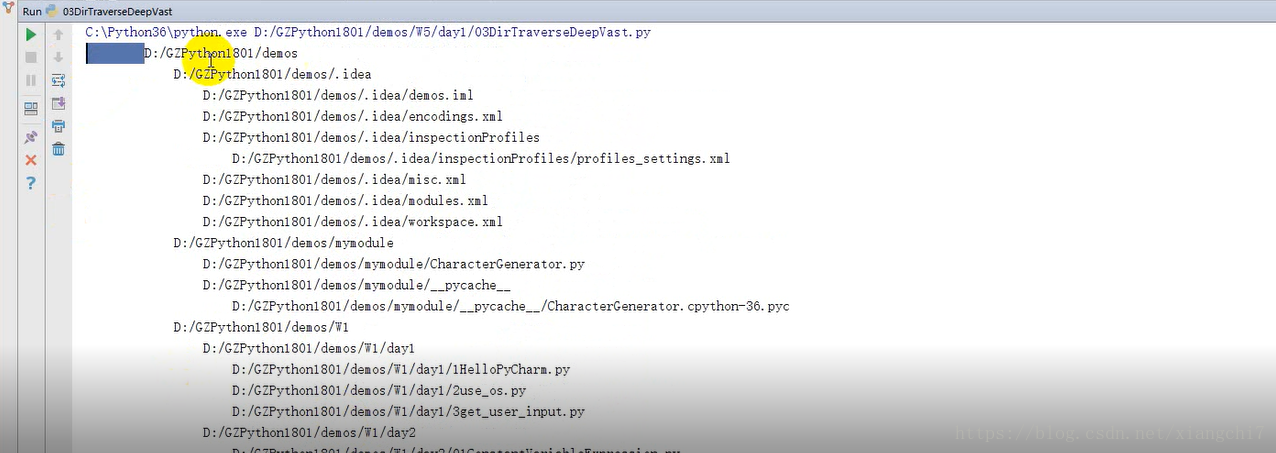
def traverseDir(dirPath):
#列出当前路径下的所有文件
filenames = os.listdir(dirPath)
#遍历所有文件
for name in filenames:
#文件全名 = 路径 + "/" + 文件名
name = dirPath + "/" +name
#计算当前路径的缩进,突出层级关系
indent = name.count("/") - 2 #这里不一定是2,具体以文件夹所在位置为准
#打印(缩进+文件全名)
print("\t" * indent + name)
#如果是子文件夹,就继续递规下一个文件
if os.path.isdir(name):
traverseDir(name)
if __name__ == '__main__':
traverseDir(filedialog.askdirectory())
pass
执行结果:
广度遍历(列队实现)
广度遍历与深度遍历相反,深度遍历是把一个文件夹遍历干净才轮到下一个文件夹,广度遍历是按层级遍历,由浅入深,一层遍历完才能执行下一层的文件内容,队列是一种先入先出的数据结构
ollections.deque()——队列,用于容纳元素,可以从头部或尾部弹出元素
import os
from tkinter import filedialog
import collections
def traverseDirVast(dirPath):
# 定义一个队列,用于装路径,先把父路径放入(当然用列表也没问题)
PQ = collections.deque()
PQ.append(dirPath)
#如果容器不为空
while len(PQ):
#从队列容器头中拿出一个路径
path = PQ.popleft()
#并罗列这一层级内容
filenames = os.listdir(path)
for name in filenames:
# 计算一下下层级的缩进,并打印文件路径名
name = path + "/" + name
indent = name.count("/") - 2 #这里不一定是2,具体以文件夹所在位置为准
print("\t" * indent + name)
#对文件进行判断,如果是文件夹,继续放入队列容器,
if os.path.isdir(name):
PQ.append(name)
if __name__ == '__main__':
traverseDirVast(filedialog.askdirectory())
执行结果:
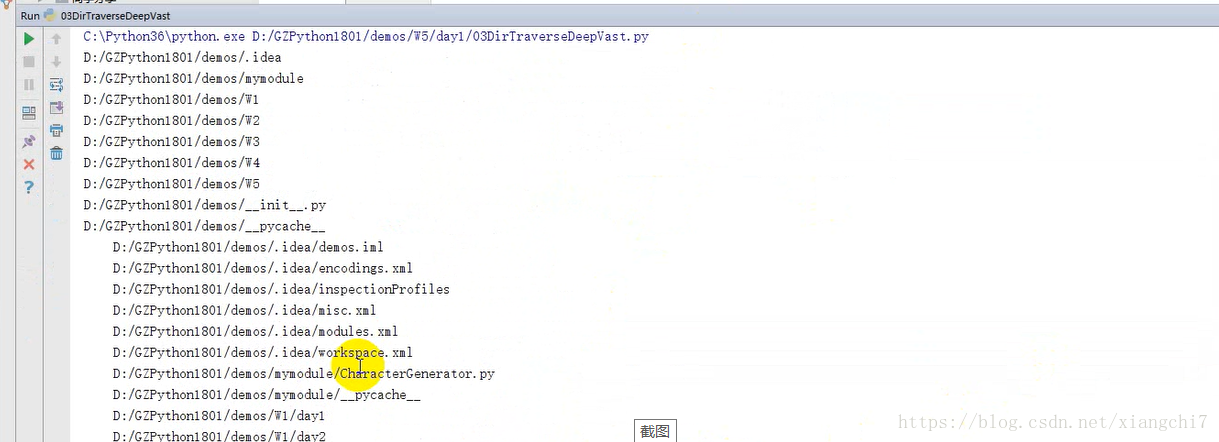
深度遍历(栈实现)
栈,也是使用队列,但是是一种先入后出的数据结构
import os
from tkinter import filedialog
import collections
def traverseDirDeep(dirPath):
# 定义一个栈,用于装路径,先把父路径放入
pStack = collections.deque()
pStack.append(dirPath)
#如果容器不为空
while len(pStack):
#从队列容器尾巴中拿出一个路径
path = pStack.pop()
#计算一下当前路径缩进,打印
indent = path.count("/") - 2 # 这里不一定是2,具体以文件所在位置为准
print("\t" * indent + path)
#判断该路径是否是文件夹,如果是,罗列它的子文件
if os.path.isdir(path):
filenames = os.listdir(path)
#逆序将所子文件放入栈中
for name in reversed(filenames):
#子文件名
name = path + "/" + name
pStack.append(name)
if __name__ == '__main__':
traverseDirDeep(filedialog.askdirectory())
执行结果: