1. N-GRAM
定在应用中,需要计算一个句子的概率,一个句子是否合理就看他的可能性大小,这里的可能性大小就是用概率来衡量:
如在机器翻译中:
P(high winds tonite) > P(large winds tonite)
拼写检查中:
上面的例子显示了计算一个句子的概率来判断它是否合理,下面用概率语言进行描述:
我们需要计算一个序列句子的概率: P(W)=P(w1,w2,w3,w4,w5....wn)
其中我们也需要计算一个相关的任务,比如P(W5|w1,w2,w3,,w4)表示在w1234后出现w5的概率,即下一个词出现的概率。
像这样计算P(W)或者P(wn|w1,w2...)的模型叫做语言模型(language model 简称LM)。通俗来看,语言模型其实就是看一句话是不是人说出来的,如果用机器翻译出现若干候选项后,可以使用语言模型挑选一个最靠谱的结果。
如何计算P(W)呢?用条件概率的链式规则,链式规则常常用来评估随机变量的联合概率,规则如下:
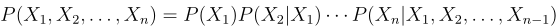
即:
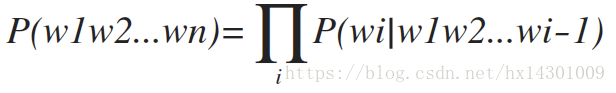
按照链式规则,举个例子:
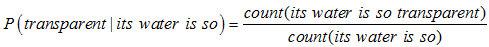
可是事实上,如果这样计算,实际上是不行的,原因有2个:
1.直接这样计算会导致模型的参数空间过大,一个语言模型的参数就是所有的这些条件概率,试想;假设词典大小为|V|,则按上面的方式计算 :P(w5|w1,w2,w3,w4),每一个wi的取值都有词典大小种,即|wi|=|v|,这样光是计算Count(w1w2w3w4w5)就有|V|^5个参数,而且这还不包括P(w4|w1,w2,w3)的个数,可以看到这样计算条件概率会使得参数个数太多。
2.数据稀疏严重。如果按照这样计算,比如计数分子its water is so transparent,这种句子出现的次数是很少的,这样计算的结果会使得过多的条件概率趋近于0,因为我们没看到足够的文本来统计。
因此,通过马尔科夫假设进行化简上面的计算:马尔科夫假设是指: 假设第wi个词语只与它前面的k个词语相关,这样我们就得到前面的条件高绿计算简化如下:

这样我们的P(W)计算化简如下:
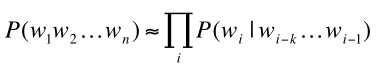
当k=0时,这时候对应的模型叫做一元模型(Unigram model),即wi与前面的0个词相关,也就是wi不与任何词相关,每个词之间互相独立,
P(W)计算如下:
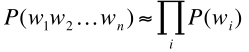
当k=1时,对应的模型叫做二元模型(Bigram model),此时wi与它前面一个词相关,P(W)计算如下:
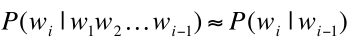
当k=N-1,模型成为n元模型,即N-Gram。
总的来说,N-gram模型有一些不足,因为有些语句存在一个长依赖关系,如:
the computer which i had just put into the machine rom on the fifth floor crashed.
这句话中,假如我们要预测crashed出现的概率,采用二元模型的话,则crash与floor并没有什么相关,得到的可能性就会很小,而crashed与主语computer的相关性很大,但是n-gram没有捕捉到这个信息。
参数估计
要计算出模型中的条件概率,这些条件概率也称为模型的参数,得到这些参数的过程称为训练。用最大似然法估计下面的条件概率:
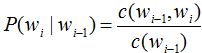
其中C(wi-1)表示wi-1出现的次数,是count的首字母c,举个例子:

其中<s></s>分别表示一个句子的开头和结束,计算这段文本的二元模型如下:
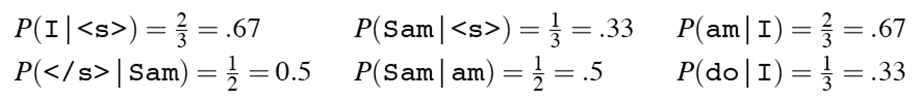
就是简单的计数然后相除
再看一个例子,这个例子来自大一点的语库(下面表格就画出一部分词),为了计算对应的二元模型的参数P(wi|wi-1),我们要先计算出C(wi-1,wi),然后计算出C(wi-1),再用除法获得条件概率。可以看到对于C(Wi-1,wi)来说,wi-1有语库词典大小(记作|V|)的可能取值,Wi也是,(因为Wi可以为语库中任意一个单词,所以有|V|种可能)
所以C(wi-1,wi)要计算的个数有|V|^2. 如下图所示:
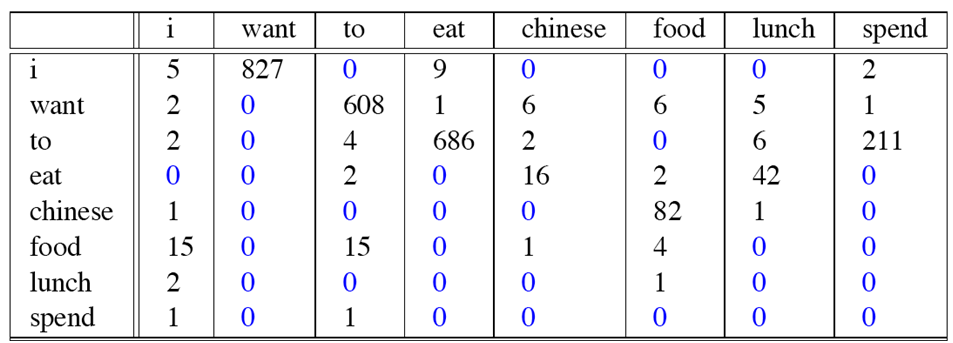
C(wi-1的计算结果如下):

那么二元模型的参数计算结果如下:
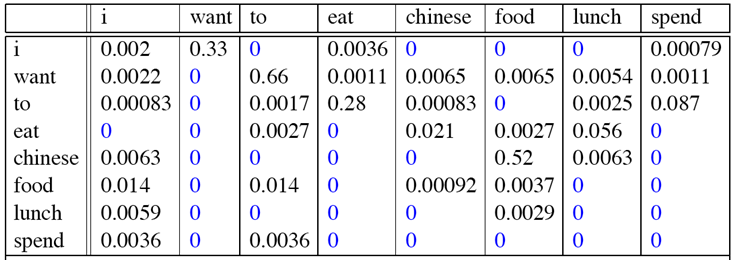
比如:计算P(want|I)=0.33如下:
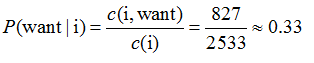
P(<s>i want english food </s>)=P(want | i)✖️P(english | want)✖️P(food | english) ✖️P(</s>| food)=0.000031
我们再看下二元模型所捕捉到的一些实际信息:

实际上常常在对数空间里面计算概率,原因有2个:
1.防止溢出,可以看到,如果计算的句子稍微长点,那么最后得到的概率会很小,甚至会溢出,通过取log,可以让值变大,不会溢出(如0.001,取完log为-3)
2.对数空间里面加法可以代替乘法,log(p1 p2)=log p1 + log p2,这样计算更快。
建立N-GRAM模型这里老师推荐了开源工具包,SRILM( http://www.speech.sri.com/projects/srilm/),以及开源的N-GRAM数据集:http://ngrams.googlelabs.com/
语言模型的评价:
一般来说,我们在训练集上得到语言模型的参数(即各个条件概率),在测试集里面测试模型的性能,那么如何去衡量一个语言模型的好坏呢?比较两个模型AB的好坏,一种外在评价就是讲AB放在一个具体任务中看看那个准确率高,但是这样方法的缺点是过于耗时,在实际情况中往往需要花费过多的时间才能得到结果。另一种方式是使用下面介绍的困惑度,但是注意:困惑度并不是上述外在评价的一个好的近似,所以一般使用在试点实验上。所谓试点实验就是一个小规模的初步研究,来评估一些性能。
困惑度
困惑度的基本评价方式是对测试集赋予高概率值的模型更好,一个句子的困惑度(PP)定义如下:
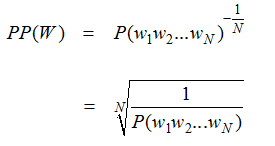
对于二元模型,该公式为:
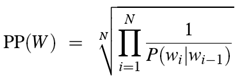
可以看到,概率越大,困惑度越小,即小的困惑度等于号的模型,且当wi之间相互独立时(一元模型),且各个概率均为P时,公式为:
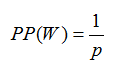
比如计算一个只包含0-9数字序列的困惑度,每个数字发生的概率是1/10.那么我们得到困惑度PP(W)=10.
数据稀疏问题
数据稀疏问题,就是由于有限的语句,产生了0概率问题,从前面一个例子来看:

这个二元模型里面也是相当多的条件概率为0
我们再来看个例子:
在某个训练集中:
从这个训练集中,我们训练得到模型,因为denied the offer在训练集中从没发生过,所以:
P(offer|denied the)=0
测试集如下:
。。。。denied the offer
,,,,denied the loan
当我们用这个模型测试时,结果上面2个概率均为0,模型试图说明这个句子不太可能出现,而事实上他只是没有出现在训练集中,所以N-Gram通常只有在训练集与测试集很相似时预测结果才比较好,而这里出现的0概率问题,也会导致无法计算困惑度,因为分母会变成0.解决N-Gram的0概率问题是很有必要的,下面讨论一些方法:
平滑方法:
平滑方法是用来解决上面语言模型的0概率问题,它的解决问题的基本思想是:把在训练集中看到的概率分一点给未看到的,并保持概率和为1.我们看一个例子图:对某个训练集,计算P(w | denied the)后的统计图:
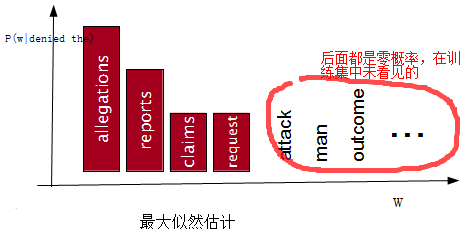
经过平滑方法后,就变成了:
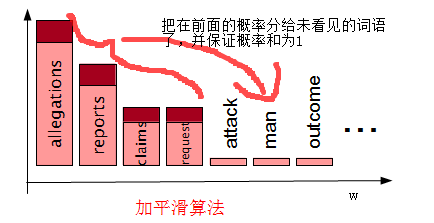
下面看一些具体的平滑算法:
1. Laplace平滑
又称为加1平滑,加1是由于其基本思想是保证所有计数结果至少出现1次,比如二元模型:
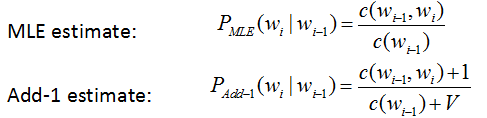
这里V是语库词汇量的大小,可以想想为什么分母要加V,因为要保证概率和为1啊。即固定w,对于某个条件概率P(Wi | W)要有:
p(w1|w)+p(w2|w)+...=1
即:
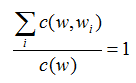
现在分子上每一个计数都+1了,那么所有分子一共加了V个1,这样分母就也要+V才可以使得和为1
现在用Laplace平滑来将前面的例子重新计数:
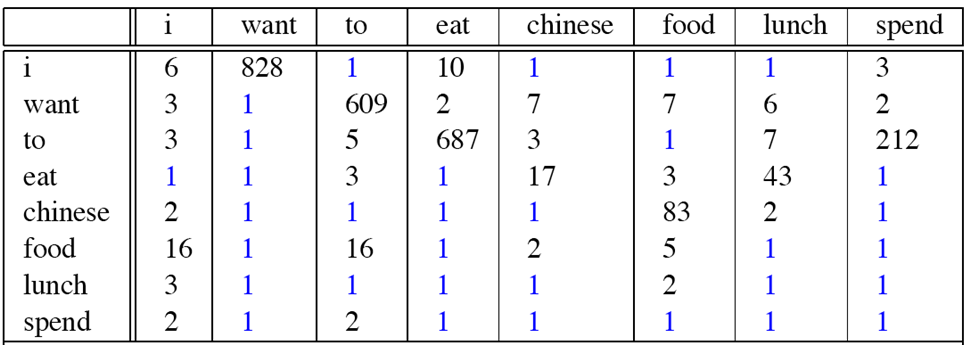
可以看到每行的各个值都+1了,同理C(Wi)中每个值都加了V
最后得到的概率为:(注:语库词汇大小不止表格画出的,表格就画出了一部分词作为例子)
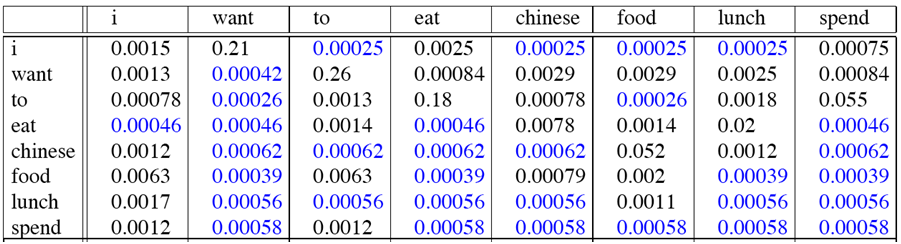
我们最开始讲的平滑算法,都是将看见的概率分一点给未看见的,我们重新计数以下,看看到底分了多少:现在利用平滑后的概率计算新的计数:

利用这个公式,我们来看看各个词都被分了多少:
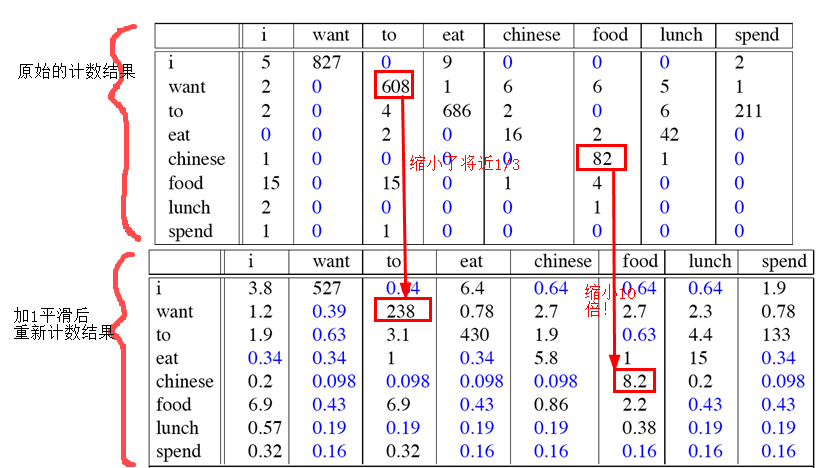
可以看到,对于语言模型,加1平滑并不是一个好的平滑方法,因为它将某些原来的计数大幅度消减用来补偿那些未看见的计数。但是某些情况,它还是效果不错的。
删除插值
删除插值使用线性插值的手段,将高阶模型和低阶模型做线性组合,例如计算三元语法时,把一元语法,二元语法和三元语法结合起来,每种语法用线性权值λ来加权,公式如下:
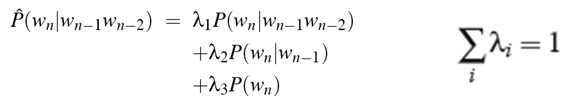
还可以吧每个lambda看成上下文相关的函数,进一步扩展该公式为:(这里没看明白)
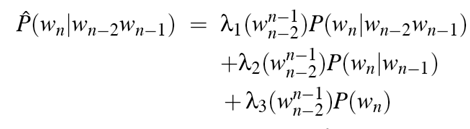
为了确定参数λi,将原始语料中一部分作为留存数据(held-out data),即现在有三个数据集:

用最小化留存数据的困惑度来求得λi:
1.求出training data初始模型,并初始化λi
2.数据集选择留存数据,选择λi使得下面的概率最大化:

Stupid backoff
backoff是退避的意思,回退的含义是比如要计算P(Wn| Wn-2,Wn-1),但是没有相关的三元统计,就可以使用二元语法来估计它。如果没有相关的二元统计,那么就用一元语法来估计它。对于一些庞大的语料库,比如google N-gram语料库,不能直接拿来用,需要进行剪枝,缩小其规模,如:仅仅使用出现概率大于阈值的n-gram,去掉一些高阶的n-grams等,另外在存储效率上,也可以改变存储的数据结构,改变数据类型等方法。对于这类大规模语料建立的语言模型,所用的平滑方法叫做Stupid backoff:
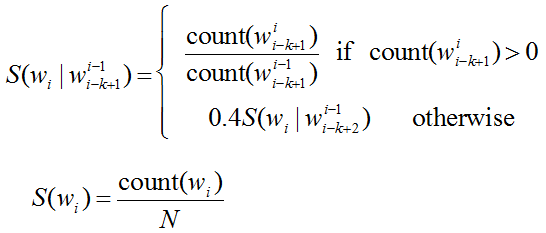
更好的平滑算法:
前面介绍了加一平滑,效果不是很好,更一般的,我们有加K平滑,形式如下:

其中分母V仍然是语料词汇量的大小。
现在把这个式子转换一下:
令: m=KV
将m带入加k平滑算法中:
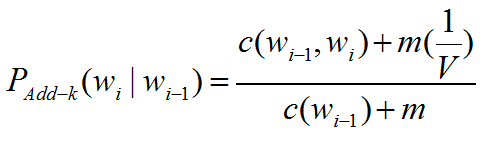
再得到如下公式,与一元模型概率相关:(如何推导?)
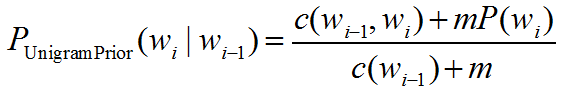
Unigram Prior平滑效果比较好,但是对于语言模型来说还不够好。下面介绍Good-Turing,Kneser-Ney,Witten-Bell,这几种平滑算法都是用我们只出现一次的计数去估计未看见的
Good-Turing(古德-图灵)平滑算法
Good-Turing估计是许多数据平滑技术的核心。它的基本思想是:将统计参数按出现次数聚类(如果 #(xj ) = #(xj‘), then θ[j] = θ[j’]),出现一次的多少,出现两次的多少,等等,然后用出现次数加一的类来估计当前类。比如,用出现次数为n+1的类来估计出现次数为n的类。
先介绍一个记号Nc=频数c的频数,举个例子,对于如下文本:
Sam I am I am Sam I do not eat
分别统计每个单词的出现次数:
I =3 Sam =2 am=2 do = 1 not = 1 eat =1
那么可以得到:N1=3(出现次数为1的单词有3个) N2=2 N3=1 ,那么c*Nc=频数为c的次数(即出现次数为c的单词共出现了几次)
Good-Turing估计θ(r)为:

首先必须保证所有元素出现的概率的和应该是1.
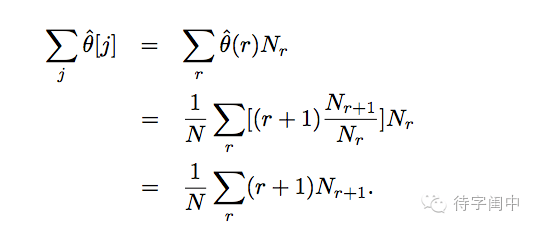
由于
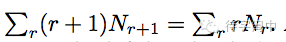
所以
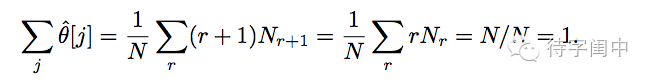
对于Good-Turing估计的具体推导,请点击阅读原文或是参考 http://www.cs.cornell.edu/courses/cs6740/2010sp/guides/lec11.pdf
了解这个之后,再举个例子来直观地理解Good-Turing,假设现在某人在钓鱼且结果如下:
10 carp,3 perch, 2 whiteFish, 1 trout, 1 salmon , 1 eel=18 fish
那么下一条鱼是trout的概率是多少呢?因为上面trout出现了一次,所以概率为1/18.那么下一条鱼是新品种的鱼的概率呢?
因为Good-Turing是将看过一次的计数去估计未看见的,上面N1=3,所以概率是3/18,如果用这样的假设的话,只看过一次的概率就要打折分给未看见的,所以前面第一个问题下一条鱼的概率一定会小于1/18,下面看一下Good-Turing计算公式:


其中 : 
所以对下一条是未看见的鱼的种类的概率:
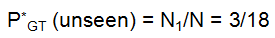
那么下一条是仅看过一次的鱼种类的概率就如下计算:
