这是一篇发表于今年EMNLP上一篇关于文本理解的文章,更准确的来说应该是解决NLP中的短文本语义匹配和神经信息检索(neural information retrieval,NIR)中共同存在的语义匹配问题。
NLP中的很多任务的中间环节或是基本原理都会多多少少的涉及到文本语义匹配,例如在文本分类(text classification)中,模型需要通过编码输入文本间的语义表示来计算最后的匹配得分;在阅读理解(reading comprehension)中,在最后定位正确答案的具体区域之前,同样需要根据语义相关从语料库中找到相关的文本……因此。语义匹配是NLP中的一个基本问题,通过词嵌入、LSTM、Transformer或预训练模型来获取输入的表示,最后通过计算表示向量间的距离来得到匹配分数。
随着深度学习在NLP中的成功,将神经网络应用到IR中来提升检索模型的性能成为了一个自然而然的想法。IR主要关注的仍然是一个匹配问题:当用户给定查询时,模型需要根据一定的匹配规则从文档集中找到相关的文档。在深度学习之前主要是基于统计信息进行检索排序,例如使用BM25、TF-IDF等;接着研究人员将word2vec等分布式语义表示模型应用到IR中,基本原理就是比较查询向量和文档向量的余弦相似度,例如DRMM、k-NRM等;最近随着预训练模型的出现,pre-traing + fine tune 成为了NLP中很多任务新的处理范式,因此也就有人将其应用到了IR中的Reranking环节中,借助预训练模型强大的表示能力,最后可以取得不错的效果。
SIGIR 2019 Outline Generation Understanding the Inherent Content Structure of Documents
如上所述可知,相关性匹配和语义匹配在文本相似度建模中都各有优势,而且两者并不是彼此分隔的,如果将两种方式结合到一起使用,那么最后得到的结果应该是比单一一种方式的结果要好。因此,作者在本文中提出了一种混合模型HCAN(Hybrid Co-Attention Network),从模型的名字中我们也可以猜到模型的基本思想,HCAN主要包含以下三个模块:
- 混合编码模块
- 相关性匹配模块
- 语义匹配模块
最后,作者在几个数据集上进行实验证明了想法的合理性和有效性。
HCAN
模型的架构如下所示:
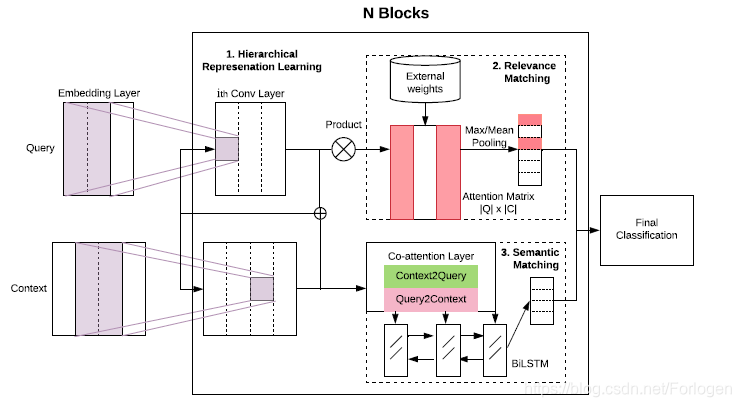
模型的输入为查询(query)和与之比较的文本(context),目标就是让模型判断两者间的匹配程度。为了捕获短语级的表示,这里使用了三种类型的encoder,作者将其称为deep、wide和contextual。
- Deep Encoder:堆叠多层的卷积层,表示向量经过多层的卷积来得到高层的表示
- Wide Encoder:并行的将表示向量通过拥有不同卷积核的卷积层,分别得到每一层对应的表示向量
- Contextual Encoder:使用双向的LSTM来获取长程依赖特征
三种类型的encoder在理想情况下应该起到一种互补的效果,前两种可以显式控制卷积核大小且速度更快,最后一个更容易捕获长程特征。
Relevance Matching
假设将查询和文本的表示记为 和 ,首先两者做乘积得到相似性矩阵 , 就表示 和 的相关性分数,将其正则化处理后得到 ,最后将其通过Softmax就得到了位于[0, 1]之间的相关性分数。前一模块使用了三种类型的encoder得到不同层级的表示,但是查询中不同的phrase和对应的文本之间匹配的重要性应该是不同的。因此,作者这里在softmax层之前将它们通过了两种类型的池化层(max-pooling和mean-pooling),又计算了每一部分的IDF值作为对应的权重,因此最后输入到softmax中的为:
Semantic Matching
这里的语义匹配就是使用了Co-Attention来计算查询向量和文本向量之间的注意力分数,将其作为语义匹配得分,没有什么特别的地方,具体细节可见原文。
通过上述的过程得到了相关性特征和语义匹配特征,最后将两者进行拼接后送入到MLP中来计算最终的分数,对应的损失项自然就是负对数似然。
Experiment
作者在四个任务上进行了实验来验证模型的有效性,任务和对应的数据集如下:
- Answer Slection:TrecQA
- Paraphrase Identification: TwitterURL
- Semantic Textual Similarity: Quera dataset
- Tweet Search: TREC Microblog
实验结果如下所示:
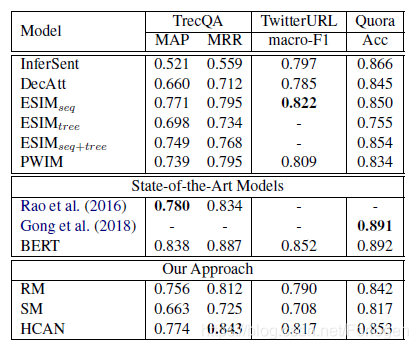
从结果中可以看出,本文所提出的方法比起BERT环视查了一些,但是普遍优于其他的baselines。
关于比较三种encoder之间的比较、学习效率和定性评估的实验部分详见原文~
EMNLP 2019 Abstract Text Summarization: A Low Resource Challenge
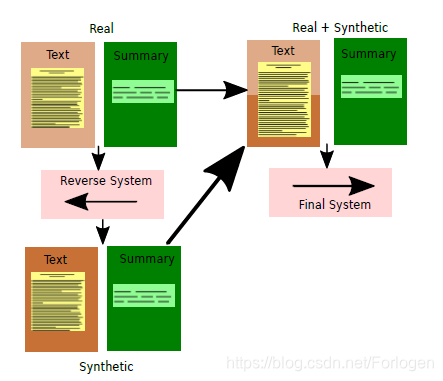
这是一篇短文,借鉴了机器翻译中的back-translation的思想通过数据增广来解决低资源下的生成式文本摘要问题,个人觉得没有什么有趣的地方,有兴趣的可查看原文。
这里推荐一篇FACEBOOK的关于低资源机器翻译任务的报道:Recent advances in low-resource machine translation
