一、为什么要调整学习率
学习率(learning rate): 控制更新的步伐
梯度下降:

学习率是用来控制更新的步伐,学习率一般前期大后期小,到后期需要调整学习率,让loss逐渐下降到收敛,就如同打高尔夫球,前期大力挥杆,使球到洞口附近,后期接近洞口的时候就需要调整小力度
二、pytorch的六种学习率调整策略
2.1 LRScheduler
class LRScheduler(object):
def __init__(self, optimizer, last_epoch=-1):
def get_lr(self):
raise NotImplementedError
功能:pytorch的六种学习率调整策略方法的基类
主要属性:
- optimizer: 关联的优化器
- last_epoch: 记录epoch数
- base_lrs: 记录初始学习率
主要方法:
- step(): 更新下一个epoch的学习率,在epoch的for循环处使用
- getIr(): 虚函数,计算下一个epoch的学习率
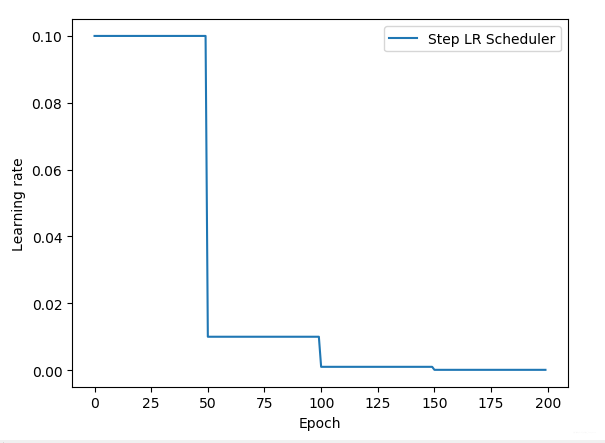
2.2 StepLR
lr_scheduler.StepLR(optimizer, step_size, gamma=0.1, last_epoch=-1)
功能: 等间隔调整学习率
主要参数:
- step_size:调整间隔数
- gamma: 调整系数
调整方式: Ir =Ir * gamma
# -*- coding:utf-8 -*-
import torch
import torch.optim as optim
import numpy as np
import matplotlib.pyplot as plt
torch.manual_seed(1)
LR = 0.1
iteration = 10
max_epoch = 200
# ------------------------------ fake data and optimizer ------------------------------
weights = torch.randn((1), requires_grad=True)
target = torch.zeros((1))
optimizer = optim.SGD([weights], lr=LR, momentum=0.9)
# ------------------------------ 1 Step LR ------------------------------
# flag = 0
flag = 1
if flag:
scheduler_lr = optim.lr_scheduler.StepLR(optimizer, step_size=50, gamma=0.1) # 设置学习率下降策略
lr_list, epoch_list = list(), list()
for epoch in range(max_epoch):
lr_list.append(scheduler_lr.get_lr())
epoch_list.append(epoch)
for i in range(iteration):
loss = torch.pow((weights - target), 2)
loss.backward()
optimizer.step()
optimizer.zero_grad()
scheduler_lr.step()
plt.plot(epoch_list, lr_list, label="Step LR Scheduler")
plt.xlabel("Epoch")
plt.ylabel("Learning rate")
plt.legend()
plt.show()
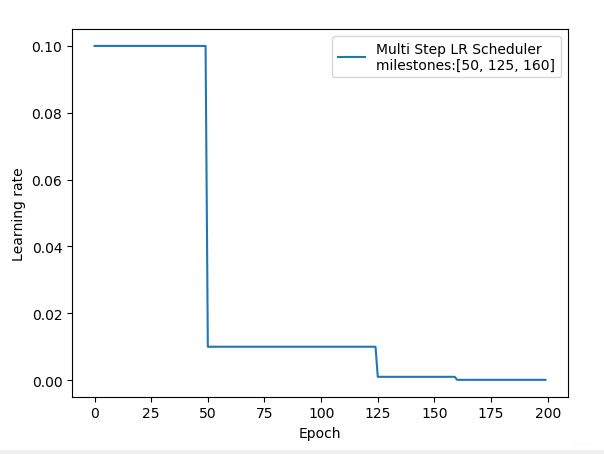
2.3 MultiStepLR
lr_scheduler.MultiStepLR(optimizer, milestones, gamma=0.1, last_epoch=-1)
功能: 按给定间隔调整学习率
主要参数:
- milestones:设定调整时刻数
- gamma:调整系数
调整方式: Ir =Ir * gamma
# -*- coding:utf-8 -*-
import torch
import torch.optim as optim
import numpy as np
import matplotlib.pyplot as plt
torch.manual_seed(1)
LR = 0.1
iteration = 10
max_epoch = 200
# ------------------------------ fake data and optimizer ------------------------------
weights = torch.randn((1), requires_grad=True)
target = torch.zeros((1))
optimizer = optim.SGD([weights], lr=LR, momentum=0.9)
# ------------------------------ 2 Multi Step LR ------------------------------
# flag = 0
flag = 1
if flag:
milestones = [50, 125, 160]
scheduler_lr = optim.lr_scheduler.MultiStepLR(optimizer, milestones=milestones, gamma=0.1)
lr_list, epoch_list = list(), list()
for epoch in range(max_epoch):
lr_list.append(scheduler_lr.get_lr())
epoch_list.append(epoch)
for i in range(iteration):
loss = torch.pow((weights - target), 2)
loss.backward()
optimizer.step()
optimizer.zero_grad()
scheduler_lr.step()
plt.plot(epoch_list, lr_list, label="Multi Step LR Scheduler\nmilestones:{}".format(milestones))
plt.xlabel("Epoch")
plt.ylabel("Learning rate")
plt.legend()
plt.show()
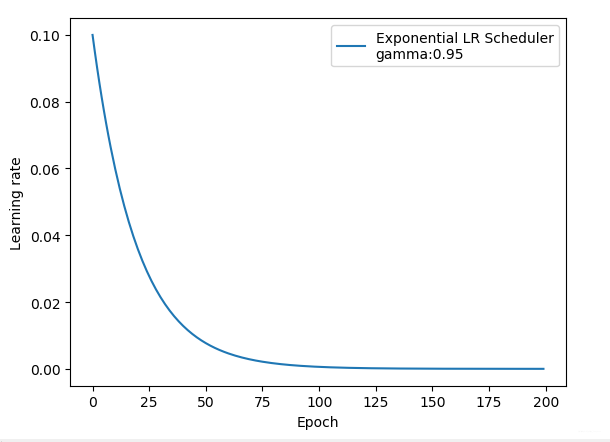
2.4 ExponentialLR
lr_scheduler.ExponentialLR(optimizer, gamma, last_epoch=-1)
功能: 按指数衰减调整学习率
主要参数:
- gamma: 指数的底
调整方式: Ir = Ir * gamma ** epoch
# -*- coding:utf-8 -*-
import torch
import torch.optim as optim
import numpy as np
import matplotlib.pyplot as plt
torch.manual_seed(1)
LR = 0.1
iteration = 10
max_epoch = 200
# ------------------------------ fake data and optimizer ------------------------------
weights = torch.randn((1), requires_grad=True)
target = torch.zeros((1))
optimizer = optim.SGD([weights], lr=LR, momentum=0.9)
# ------------------------------ 3 Exponential LR ------------------------------
# flag = 0
flag = 1
if flag:
gamma = 0.95
scheduler_lr = optim.lr_scheduler.ExponentialLR(optimizer, gamma=gamma)
lr_list, epoch_list = list(), list()
for epoch in range(max_epoch):
lr_list.append(scheduler_lr.get_lr())
epoch_list.append(epoch)
for i in range(iteration):
loss = torch.pow((weights - target), 2)
loss.backward()
optimizer.step()
optimizer.zero_grad()
scheduler_lr.step()
plt.plot(epoch_list, lr_list, label="Exponential LR Scheduler\ngamma:{}".format(gamma))
plt.xlabel("Epoch")
plt.ylabel("Learning rate")
plt.legend()
plt.show()
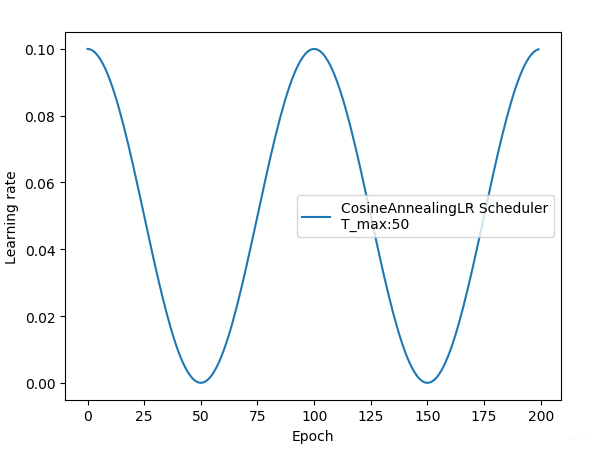
2.5 CosineAnnealingLR
lr_scheduler.CosineAnnealingLR(optimizer, T_max, eta_min=0, last_epoch=-1)
功能: 余弦周期调整学习率
主要参数:
- T-max:下降周期
- eta_min:学习率下限
调整方式:
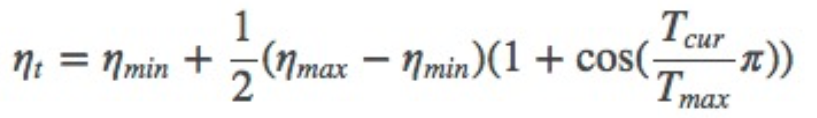
# -*- coding:utf-8 -*-
import torch
import torch.optim as optim
import numpy as np
import matplotlib.pyplot as plt
torch.manual_seed(1)
LR = 0.1
iteration = 10
max_epoch = 200
# ------------------------------ fake data and optimizer ------------------------------
weights = torch.randn((1), requires_grad=True)
target = torch.zeros((1))
optimizer = optim.SGD([weights], lr=LR, momentum=0.9)
# ------------------------------ 4 Cosine Annealing LR ------------------------------
# flag = 0
flag = 1
if flag:
t_max = 50
scheduler_lr = optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=t_max, eta_min=0.)
lr_list, epoch_list = list(), list()
for epoch in range(max_epoch):
lr_list.append(scheduler_lr.get_lr())
epoch_list.append(epoch)
for i in range(iteration):
loss = torch.pow((weights - target), 2)
loss.backward()
optimizer.step()
optimizer.zero_grad()
scheduler_lr.step()
plt.plot(epoch_list, lr_list, label="CosineAnnealingLR Scheduler\nT_max:{}".format(t_max))
plt.xlabel("Epoch")
plt.ylabel("Learning rate")
plt.legend()
plt.show()
2.6 ReduceLROnPlateau
lr_scheduler.ReduceLROnPlateau(optimizer,
mode='min',
factor=0.1,
patience=10,
verbose=False,
threshold=0.0001,
threshold_mode='rel',
cooldown=0,
min_lr=0,
eps=1e-08)
功能: 监控指标,当指标不再变化则调整
主要参数:
- mode: min/max两种模式
- min:观察指标下降,用于loss
- max:观察指标上升,用于accuracy
- factor: 调整系数
- patience: “耐心”,接受几次不变化
- cooldown: "冷却时间”,停止监控一段时间
- verbose: 是否打印日志
- minIr: 学习率下限
- eps: 学习率衰减最小值
# -*- coding:utf-8 -*-
import torch
import torch.optim as optim
import numpy as np
import matplotlib.pyplot as plt
torch.manual_seed(1)
LR = 0.1
iteration = 10
max_epoch = 200
# ------------------------------ fake data and optimizer ------------------------------
weights = torch.randn((1), requires_grad=True)
target = torch.zeros((1))
optimizer = optim.SGD([weights], lr=LR, momentum=0.9)
# ------------------------------ 5 Reduce LR On Plateau ------------------------------
# flag = 0
flag = 1
if flag:
loss_value = 0.5
accuray = 0.9
factor = 0.1
mode = "min"
patience = 10
cooldown = 10
min_lr = 1e-4
verbose = True
scheduler_lr = optim.lr_scheduler.ReduceLROnPlateau(optimizer, factor=factor, mode=mode, patience=patience,
cooldown=cooldown, min_lr=min_lr, verbose=verbose)
for epoch in range(max_epoch):
for i in range(iteration):
# train(...)
optimizer.step()
optimizer.zero_grad()
if epoch == 5:
loss_value = 0.4
scheduler_lr.step(loss_value)

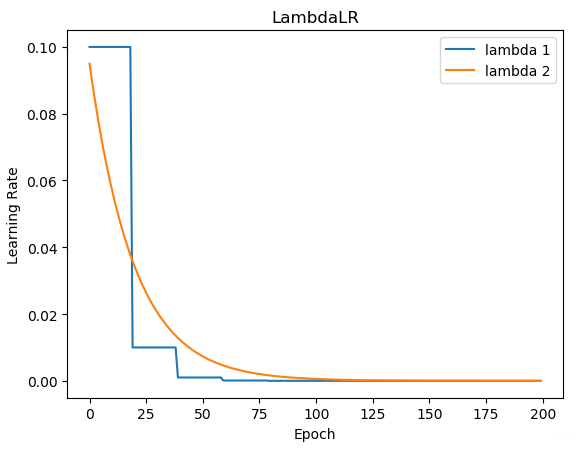
2.7 LambdaLR
Ir_scheduler.LambdaLR(optimizer, lr_lambda, last_epoch=-1)
功能: 自定义调整策略,适用于多个参数组,不同参数组设置不同调整策略时
主要参数:
- Ir_lambda: function or list
# -*- coding:utf-8 -*-
import torch
import torch.optim as optim
import numpy as np
import matplotlib.pyplot as plt
torch.manual_seed(1)
LR = 0.1
iteration = 10
max_epoch = 200
# ------------------------------ fake data and optimizer ------------------------------
weights = torch.randn((1), requires_grad=True)
target = torch.zeros((1))
optimizer = optim.SGD([weights], lr=LR, momentum=0.9)
# ------------------------------ 6 lambda ------------------------------
# flag = 0
flag = 1
if flag:
lr_init = 0.1
weights_1 = torch.randn((6, 3, 5, 5))
weights_2 = torch.ones((5, 5))
optimizer = optim.SGD([
{'params': [weights_1]},
{'params': [weights_2]}], lr=lr_init)
lambda1 = lambda epoch: 0.1 ** (epoch // 20)
lambda2 = lambda epoch: 0.95 ** epoch
scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda=[lambda1, lambda2])
lr_list, epoch_list = list(), list()
for epoch in range(max_epoch):
for i in range(iteration):
# train(...)
optimizer.step()
optimizer.zero_grad()
scheduler.step()
lr_list.append(scheduler.get_lr())
epoch_list.append(epoch)
print('epoch:{:5d}, lr:{}'.format(epoch, scheduler.get_lr()))
plt.plot(epoch_list, [i[0] for i in lr_list], label="lambda 1")
plt.plot(epoch_list, [i[1] for i in lr_list], label="lambda 2")
plt.xlabel("Epoch")
plt.ylabel("Learning Rate")
plt.title("LambdaLR")
plt.legend()
plt.show()
三、学习率调整小结
3.1 学习率调整策略总结
-
有序调整: Step.MultiStep、Exponential和CosineAnnealing
-
自适应调整: ReduceLROnPleateau
-
自定义调整: Lambda
3.2 学习率初始化
- 设置较小数: 0.01. 0.001,0.0001
- 搜索最大学习率: 参考论文《Cyclical Learning Rates for Training Neural Networks)
