动态调整学习率Lr
0 引入
在训练深度学习模型时,不可避免的要调整超参,而学习率首当其冲是大家最先想要调整的一个超参。而且学习率对于模型训练效果来说也相当重要。
然鹅,学习率过低会导致学习速度太慢,学习率过高又容易导致难以收敛。
因此,很多炼丹师都会采用动态调整学习率的方法。刚开始训练时,学习率大一点,以加快学习速度;之后逐渐减小来寻找最优解。
那么在Pytorch中,如何**在训练过程里动态调整学习率呢?**本文将带你深入理解优化器和学习率调整策略。
1 代码例程
1.1 工作方式解释
自定义学习率调度器:torch.optim.lr_scheduler.LambdaLR
torch.optim.lr_scheduler.LambdaLR(optimizer,lr_lambda = lr_lambda)
- optimizer:优化器对象,表示需要调整学习率的优化器。
- Ir_lambda:一个函数,接受一个整数参数epoch,并返回一个浮点数值,表示当前epoch下的学习率变化系数。
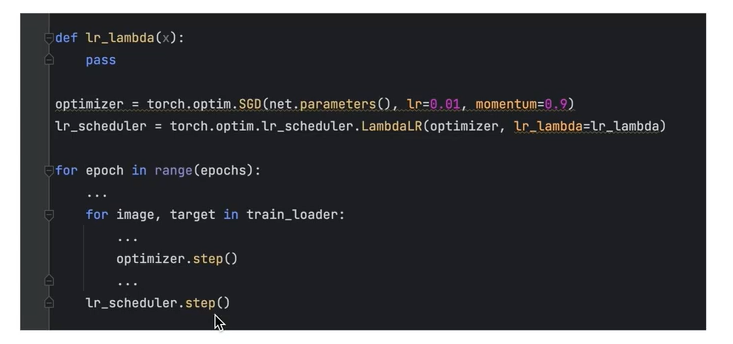
每个epoch 更新一次lr:
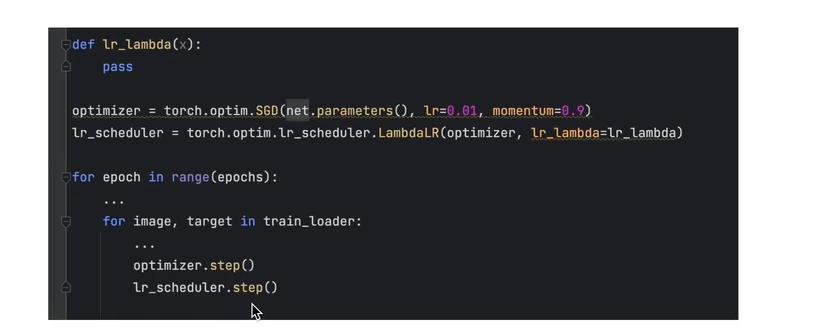
每个batch 更新一次学习率:
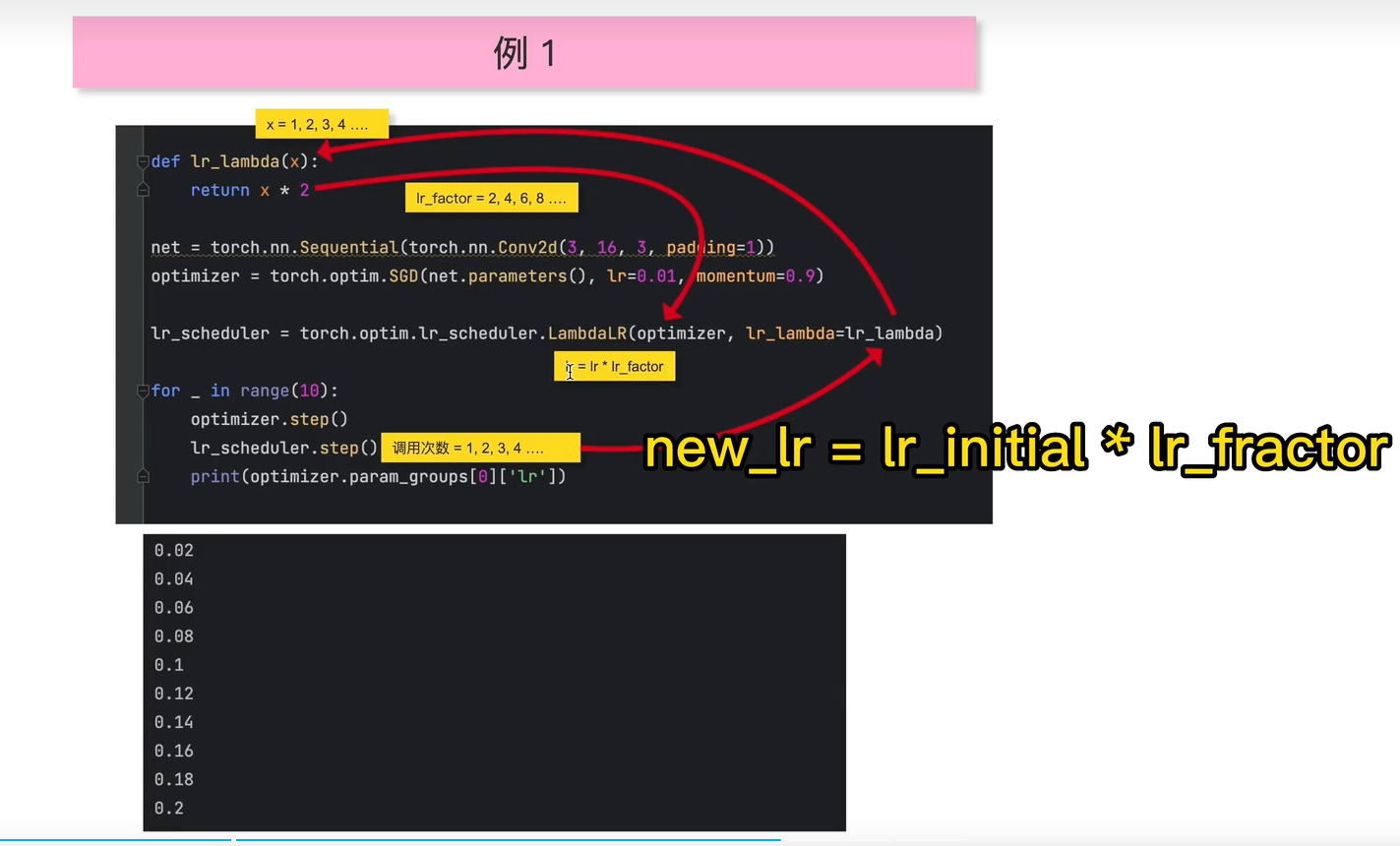
举例子: 新的学习率 = 原始学习率 * 学习率因子
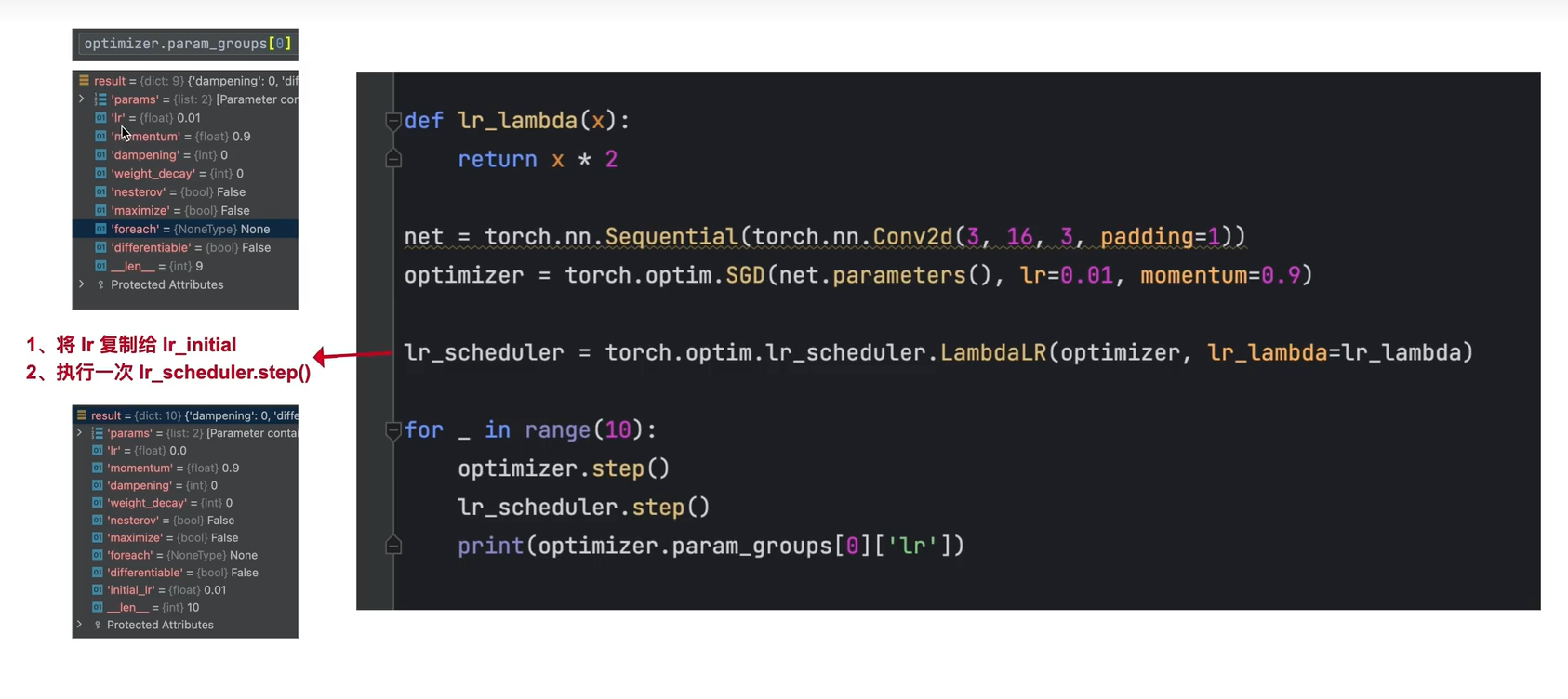
学习率调度器:
2 动态调整学习率的几种方法
一般地,模型训练和人刻意练习一项技能一样,需要反复地学习才能加固认知。模型也是一样,需要反复学习多次给定的数据集,即要训练多个epoch。在Pytorch中,给我们提供了很多种动态调整学习率的策略,这些调整策略多是基于epoch进行的。下面一一进行讲解。
2.1 lr_scheduler.LambdaLR
目的:将每个参数组的学习率设置为初始 lr 乘以给定的Lambda函数根据epoch计算出来的值。
CLASS torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda, last_epoch=- 1, verbose=False)
参数详情:
optimizer (Optimizer):关联的优化器
lr_lambda (function or list):给定当前epoch计算乘法因子的函数,如果是函数列表,则每一个函数对应一个参数组,这样就可以为不同的参数组设置不同的学习率。
last_epoch (int):最后一个epoch的索引,默认值为-1.
verbose(bool):如果为True,为每次更新打印输出,默认值False
举例子: 线性递减的lr
# 假设优化器有两个参数组.
lambda1 = lambda epoch: epoch // 30
lambda2 = lambda epoch: 0.95 ** epoch
scheduler = LambdaLR(optimizer, lr_lambda=[lambda1, lambda2])
for epoch in range(100):
train(...)
validate(...)
scheduler.step()
2.2 lr_scheduler.StepLR
目的:每step_size个epochs通过γ降低每个参数组的学习率。
CLASS torch.optim.lr_scheduler.StepLR(optimizer, step_size, gamma=0.1, last_epoch=- 1, verbose=False)
参数详情:
optimizer (Optimizer):关联的优化器
step_size (int):学习率更新的周期,每step_size个epochs更新一次
gamma (float):降低学习率的乘法因子,默认值0.1
last_epoch(int):最后一个epoch的索引,默认值-1
verbose(bool):如果为True,为每次更新打印输出,默认值False
举例子:
# 假设所有参数组的初始学习率为0.05,γ为0.1
# lr = 0.05 if epoch < 30
# lr = 0.005 if 30 <= epoch < 60
# lr = 0.0005 if 60 <= epoch < 90
# ...
scheduler = StepLR(optimizer, step_size=30, gamma=0.1)
for epoch in range(100):
train(...)
validate(...)
scheduler.step()
2.3 lr_scheduler.MultiStepLR
目的:当epoch到达设定的标志位时,通过γ降低每个参数组的学习率。请注意,这种衰减可能与此调度程序外部对学习率的其他更改同时发生。
CLASS torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones, gamma=0.1, last_epoch=- 1, verbose=False)
参数详情:
optimizer (Optimizer):关联的优化器
milestones (list):epoch索引的列表,必须是升序的,因为epoch是越来越大的
gamma (float):降低学习率的乘法因子,默认值0.1
last_epoch(int):最后一个epoch的索引,默认值-1
verbose(bool):如果为True,为每次更新打印输出,默认值False
例子:
# 假设所有参数组的初始学习率为0.05,γ为0.1
# lr = 0.05 if epoch < 30
# lr = 0.005 if 30 <= epoch < 80
# lr = 0.0005 if epoch >= 80
scheduler = MultiStepLR(optimizer, milestones=[30,80], gamma=0.1)
for epoch in range(100):
train(...)
validate(...)
scheduler.step()
2.4 lr_scheduler.ExponentialLR
目的:对于每个epoch,使用γ降低每个参数组的学习率。以 gama 为底,epoch为指数,

参数详情:
optimizer (Optimizer):关联的优化器
gamma (float):降低学习率的乘法因子,默认值0.1
last_epoch(int):最后一个epoch的索引,默认值-1
verbose(bool):如果为True,为每次更新打印输出,默认值False
2.2.5 lr_scheduler.CosineAnnealingLR
目的:使用余弦退火策略动态调整每个epoch的学习率。
CLASS torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max, eta_min=0, last_epoch=- 1, verbose=False)
参数详情:
optimizer (Optimizer):关联的优化器
T_max (int):最大的迭代次数
eta_min(float):最小的学习率,默认值0
last_epoch(int):最后一个epoch的索引,默认值-1
verbose(bool):如果为True,为每次更新打印输出,默认值False
计算公式如下:
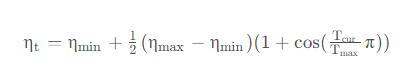
其中,\eta_{t}表示更新后的学习率,ηmin 表示最小的学习率,ηmax表示最大的学习率,Tcur表示当前epoch的索引,Tmax表示最大epoch的索引。
2.6 lr_scheduler.ReduceLROnPlateau
目的:当指标停止改进时便开始降低学习率。一旦学习停滞,将学习率降低 2-10 倍之后,模型通常会继续学习。 该调度程序读取一个指标数量,如果一定数量的 epoch 后仍没有改善,则学习率会降低。
CLASS torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.1, patience=10, threshold=0.0001, threshold_mode='rel', cooldown=0, min_lr=0, eps=1e-08, verbose=False)
参数详情:
optimizer (Optimizer):关联的优化器
mode(str):有min和max两种可选。在min模式下,当模型指标停止下降时开始调整学习率;在max模式下,当模型指标停止上升时开始调整学习率
factor (float):降低学习率的乘法因子.lr_new = lr ∗ factor
patience(int):耐心值,不是指标停止改变后立马就调整学习率,而是patience个epoch之后指标仍没有改变,便开始调整学习率,即该策略对指标的变化有一定的容忍度。默认值10
threshold(float):衡量新的最佳阈值,只关注重大变化。默认值:1e-4
cooldown(int):在 lr 减少后恢复正常操作之前要等待的 epoch 数
min_lr (float or list):每个参数组设定的最小学习率
eps (float):如果调整之后的学习率和调整之前的学习率差距小于eps,则忽略此次调整
verbose(bool):如果为True,为每次更新打印输出,默认值False
例子:
optimizer = torch.optim.SGD(model.parameters(), lr=0.1, momentum=0.9)
scheduler = ReduceLROnPlateau(optimizer, 'min')
for epoch in range(10):
train(...)
val_loss = validate(...)
# Note that step should be called after validate()
scheduler.step(val_loss)
2.7 lr_scheduler.CyclicLR
目的:根据周期性学习率策略调整每个参数组的学习率。该策略以恒定频率在两个边界之间循环调整学习率,详见论文 Cyclical Learning Rates for Training Neural Networks。 两个边界之间的距离可以在每次迭代或每个周期的基础上进行缩放。循环学习率策略在每个Batch之后改变学习率。 step()方法应该在一个Batch用于训练后调用。
该方法有三种循环策略:
triangular“:没有幅度缩放的基本三角循环
”triangular2“:一个基本的三角循环,每个循环将初始幅度缩放一半
”exp_range“:每个循环之后,将初始幅度按照 \gamma^{cycle-iterations}进行降低
例子:
optimizer = torch.optim.SGD(model.parameters(), lr=0.1, momentum=0.9)
scheduler = torch.optim.lr_scheduler.CyclicLR(optimizer, base_lr=0.01, max_lr=0.1)
data_loader = torch.utils.data.DataLoader(...)
for epoch in range(10):
for batch in data_loader:
train_batch(...)
scheduler.step()
参考
深度学习学习率调整方案如何选择? - Summer Clover的回答 - 知乎
https://www.zhihu.com/question/315772308/answer/1636730368
[]深度学习学习率调整方案如何选择?
https://www.zhihu.com/question/315772308
[pytorch 动态调整学习率,学习率自动下降,根据loss下降]
https://blog.csdn.net/qq_41554005/article/details/119879911
[深度学习之动态调整学习率LR]
https://blog.csdn.net/Just_do_myself/article/details/123751148
[pytorch优化器与学习率设置详解]
https://zhuanlan.zhihu.com/p/435669796