前面的课程学习了优化器的概念,优化器中有很多超参数如学习率lr,momentum动量、weight_decay系数,这些超参数中最重要的就是学习率。学习率可以直接控制模型参数更新的步伐,此外,在整个模型训练过程中学习率也不是一成不变的,而是可以调整变化的。本节内容就可以分为以下3方面展开,分别是:(1)为什么要调整学习率?(2)Pytorch的六种学习率调整策略;(3)学习率调整总结。
为什么要调整学习率?
①仅考虑学习率的梯度下降:
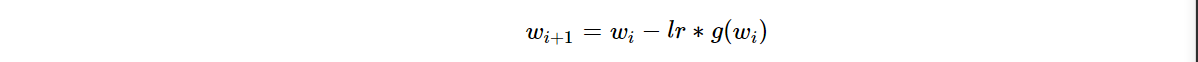
②加入momentum系数后随机梯度下降更新公式:
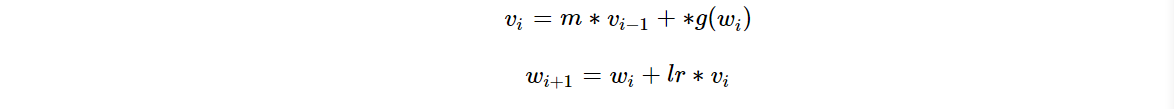
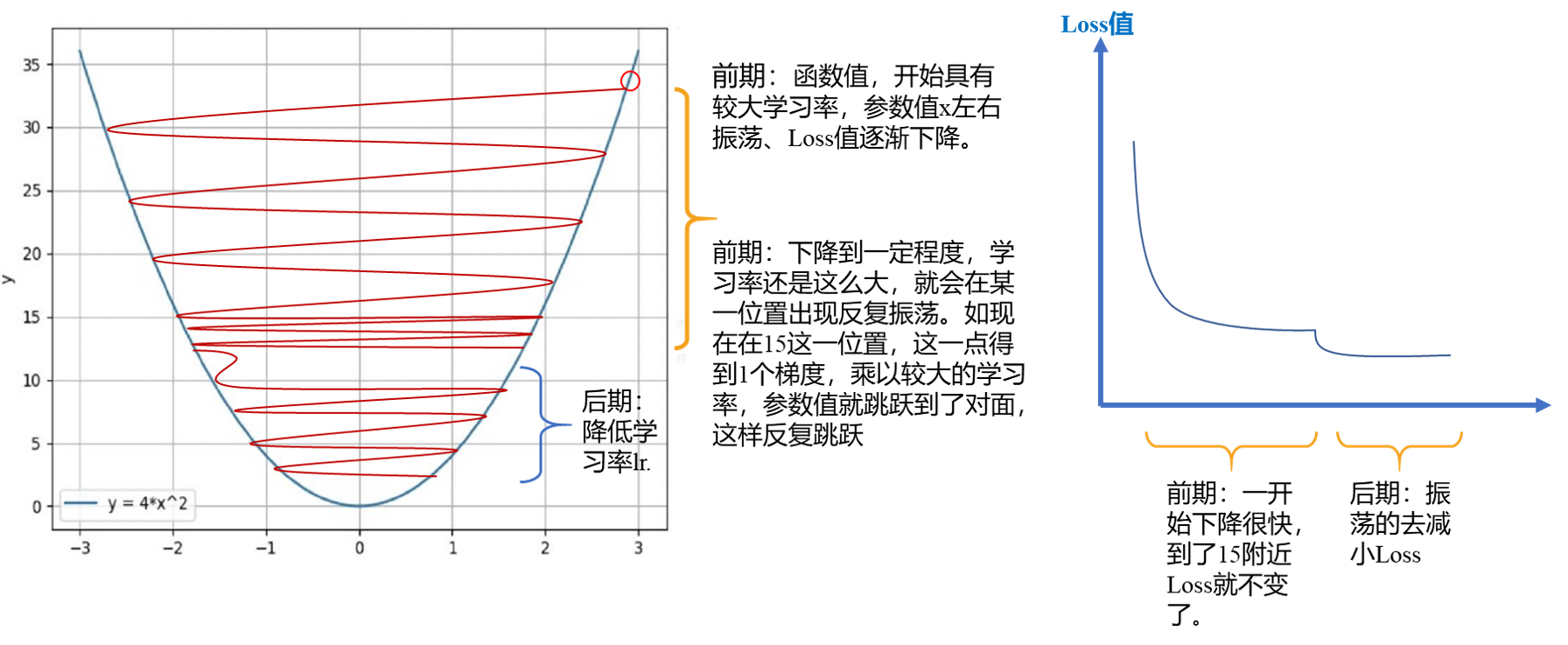
从梯度下降法公式可知,参数更新这一项中会有学习率乘以梯度或更新量(lr∗g(wi) or lr∗vi),学习率lr直接控制了模型参数更新的步伐。通常,在模型训练过程中,学习率给的比较大,这样可以让模型参数在初期更新比较快;到了后期,学习率有所下降,让参数更新的步伐减慢。可是,为什么会在模型训练时对学习率采用 “前期大、后期小” 的赋值特点呢?

由图1可知,一开始球距离洞口很远,将球打进洞口这一过程形如模型训练中让Loss逐渐下降至0这一过程。
(1)球距离洞口很远,利用较大的力度去打球,让球快速的飞跃到洞口附近,这就是一开始采用大学习率训练模型的原因;
(2)球来到洞口附近,调整力度,轻轻击打球,让球可控、缓慢的朝洞口接近。这就是学习率到了后期,让参数更新的步伐小一点,使得Loss逐渐下降。
这就学习率前期大、后期小的1个形象比喻。下面以函数的优化过程理解学习率“前期大、后期小”的原因。
Pytorch的六种学习率调整策略
Pytorch提供的六种学习率调整策略都是继承于LRScheduler基类,因此首先学习LRScheduler基本属性和基本方法。
class_LRScheduler
class_LRScheduler(object)
主要属性:
optimizer:关联的优化器
last_epoch:记录epoch数
base_lrs:记录初始学习率
主要属性
(1)optimizer:学习率所关联的优化器。已知优化器如torch.optim.SGD才是存放学习率lr的,LRScheduler会去修改优化器中的学习率。所以LRScheduler必须要关联1个优化器才能改动优化器里面的学习率。
optim.SGD(params,lr=<object object>,
momentum=0,dampening=0,
weight_decay=0,nesterov=False)
(2)last_epoch:记录epoch数。整个学习率调整是以epoch为周期,不要以iteration。
(3)base_lrs:记录初始学习率。
LRScheduler的_init_函数
class_LRScheduler(object)
def_init_(self,optimizer.last_epoch=-1):
只接受2个参数,分别是optimizer和last_epoch=-1。
主要方法
step()——更新下一个epoch的学习率 一定要放在epoch中而不是iteration。
get_lr()——虚函数,计算下一个epoch的学习率
Pytorch提供的六种学习率调整策略
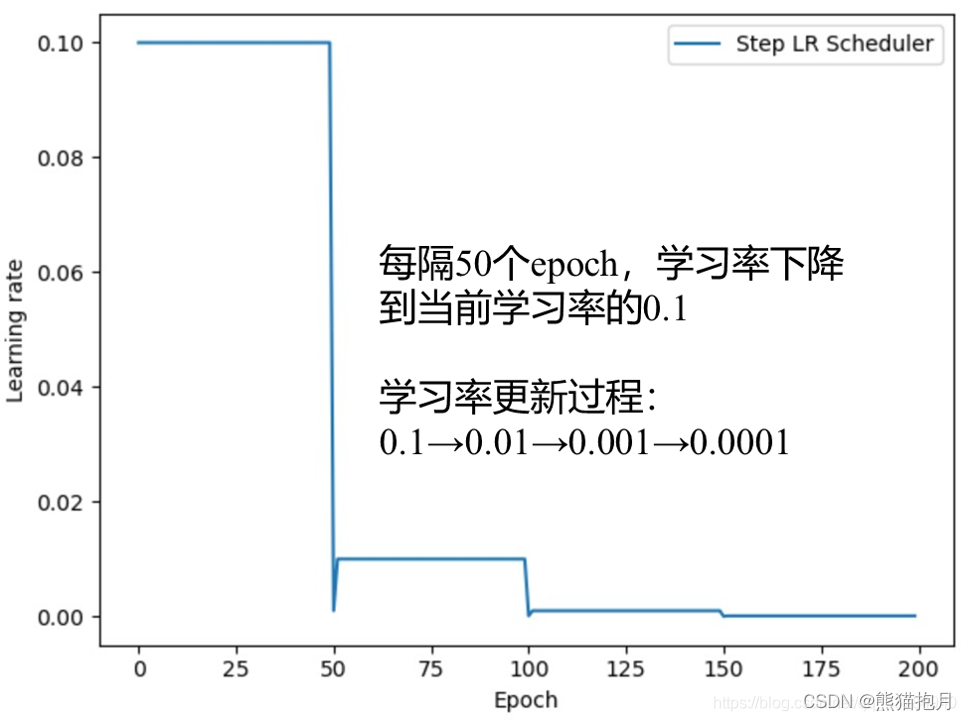
1、StepLR
功能:等间隔调整学习率
lr_scheduler.StepLR(optimizer,step_size,gamma,last_epoch=-1)
主要参数:step_size调整间隔数 gamma调整系数
设置step_size=50,每隔50个epoch时调整学习率,具体是用当前学习率乘以gamma即lr=lr∗gamma ;
调整方式:lr=lr∗gamma (gamma通常取0.1缩小10倍、0.5缩小一半)
实验
LR = 0.1 //设置初始学习率
iteration = 10
max_epoch = 200
# --------- fake data and optimizer ---------
weights = torch.randn((1), requires_grad=True)
target = torch.zeros((1))
//构建虚拟优化器,为了 lr_scheduler关联优化器
optimizer = optim.SGD([weights], lr=LR, momentum=0.9)
# ---------------- 1 Step LR --------
# flag = 0
flag = 1
if flag:
//设置optimizer、step_size等间隔数量:多少个epoch之后就更新学习率lr、gamma
scheduler_lr = optim.lr_scheduler.StepLR(optimizer, step_size=50, gamma=0.1) # 设置学习率下降策略
lr_list, epoch_list = list(), list()
for epoch in range(max_epoch):
lr_list.append(scheduler_lr.get_lr())
epoch_list.append(epoch)
for i in range(iteration):
loss = torch.pow((weights - target), 2)
loss.backward()
//优化器参数更新
optimizer.step()
optimizer.zero_grad()
//学习率更新
scheduler_lr.step()
plt.plot(epoch_list, lr_list, label="Step LR Scheduler")
plt.xlabel("Epoch")
plt.ylabel("Learning rate")
plt.legend()
plt.show()
结果
2、MultiStepLR
功能:按给定间隔调整学习率
lr_scheduler.MultiStepLR(optimizer,milestones,gamma,last_epoch=-1)
主要参数:milestones设定调整时刻数 gamma调整系数
如构建个list设置milestones=[50,125,180],在第50次、125次、180次时分别调整学习率,具体是用当前学习率乘以gamma即lr=lr∗gamma ;
调整方式:lr=lr∗gamma (gamma通常取0.1缩小10倍、0.5缩小一半)
# ------------------------------ 2 Multi Step LR ------------------------------
# flag = 0
flag = 1
if flag:
milestones = [50, 125, 160]
scheduler_lr = optim.lr_scheduler.MultiStepLR(optimizer, milestones=milestones, gamma=0.1)
lr_list, epoch_list = list(), list()
for epoch in range(max_epoch):
lr_list.append(scheduler_lr.get_lr())
epoch_list.append(epoch)
for i in range(iteration):
loss = torch.pow((weights - target), 2)
loss.backward()
optimizer.step()
optimizer.zero_grad()
scheduler_lr.step()
plt.plot(epoch_list, lr_list, label="Multi Step LR Scheduler\nmilestones:{}".format(milestones))
plt.xlabel("Epoch")
plt.ylabel("Learning rate")
plt.legend()
plt.show()
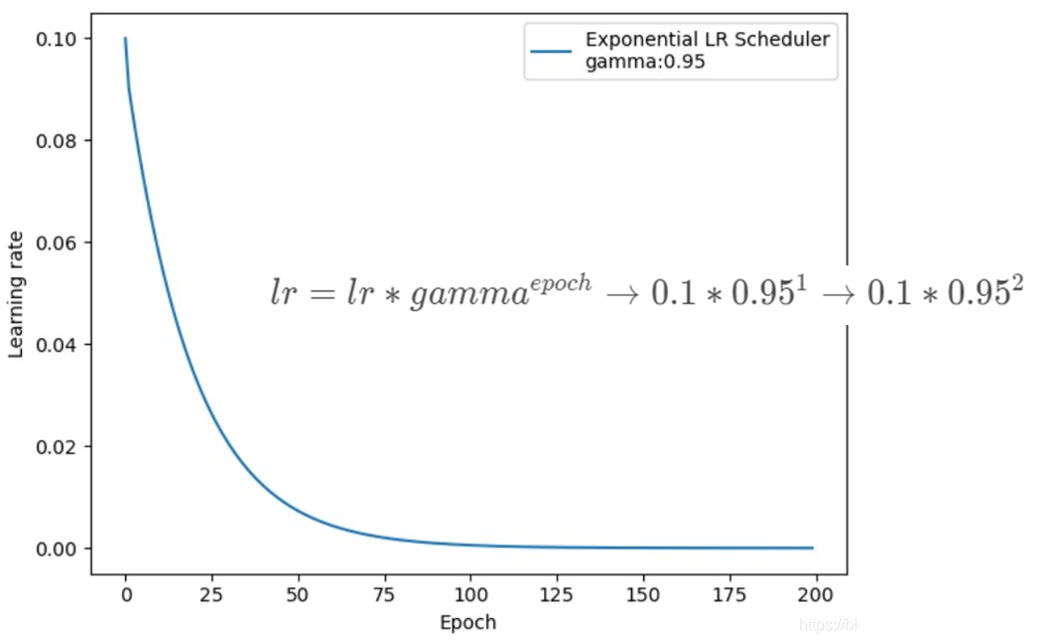
3、ExponentialLR
功能:按指数衰减调整学习率
lr_scheduler.ExponentialLR(optimizer,milestones,gamma,last_epoch=-1)
主要参数: gamma指数的底
如构建个list设置milestones=[50,125,180],在第50次、125次、180次时调整学习率,具体是用当前学习率乘以gamma即lr=lr∗gamma ;
调整方式:lr=lr∗gamma∗∗epoch (gamma通常会设置为接近于1的数值,如0.95;lr=lr∗gammaepoch→0.1∗0.95^ 1→0.1∗0.95^ 2)
# ------------- 3 Exponential LR -----------
# flag = 0
flag = 1
if flag:
gamma = 0.95
scheduler_lr = optim.lr_scheduler.ExponentialLR(optimizer, gamma=gamma)
...
结果
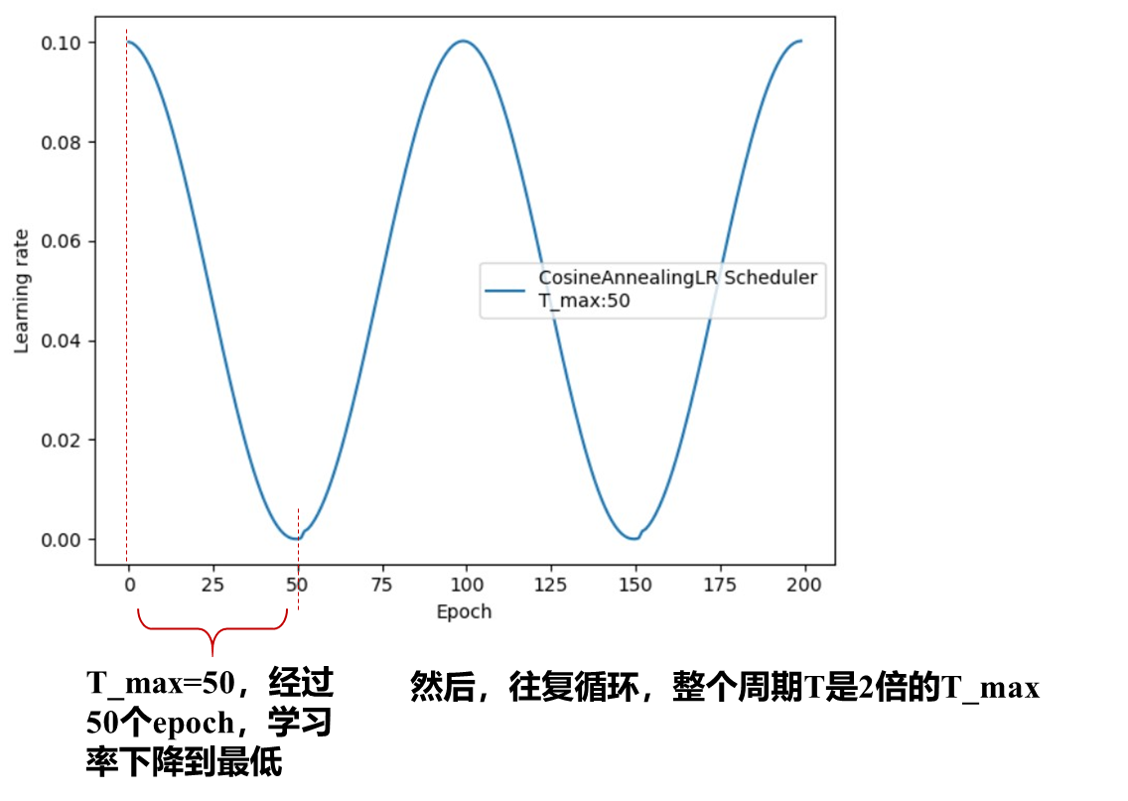
4、CosineAnnealingLR
功能:余弦周期调整学习率
lr_scheduler.ExponentialLR(optimizer,T_max,eta_min=0,last_epoch=-1)
主要参数: T_max下降周期,eta_min学习率下限
调整方式:
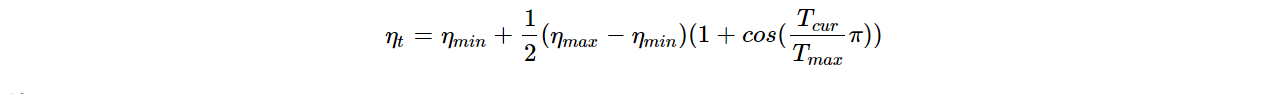
结果
5、ReduceLRonPlateau
功能:监控指标,当指标不再变化则调整(很实用)
比如监控Loss不再下降、或者分类准确率acc不再上升就进行学习率的调整。
lr_scheduler.ExponentialLR(optimizer,mode='min',
factor=0.1,patience=10,verbose=False,threshold=0.0001,
threshold_mode='rel',cooldown=0,min_lr=0,eps=1e-08)
主要参数:
mode:min/max两种模式;
在min模式下,观察监控指标是否下降,用于监控Loss;在max模式下观察监控指标是否上升,用于监控分类准确率acc。
fator调整系数——相当于上面几种调整策略中的gamma值;
patience:“耐心”,接收几次不变化;一定要连续多少次不发生变化(patience=10,某指标连续10次epoch没有变化就进行lr调整)
cooldown:“冷却时间”,停止监控一段时间;(cooldown=10,某指标连续10次epoch没有变化就进行lr调整)
verbose:是否打印日志;布尔变量;
min_lr:学习率下限;
eps:学习率衰减最小值。
# ------------------- 5 Reduce LR On Plateau -----
# flag = 0
flag = 1
if flag:
loss_value = 0.5
accuray = 0.9
factor = 0.1
mode = "min"
patience = 10
cooldown = 10
min_lr = 1e-4
verbose = True
scheduler_lr = optim.lr_scheduler.ReduceLROnPlateau(optimizer, factor=factor, mode=mode, patience=patience,
cooldown=cooldown, min_lr=min_lr, verbose=verbose)
for epoch in range(max_epoch):
for i in range(iteration):
# train(...)
optimizer.step()
optimizer.zero_grad()
# if epoch == 5:
# loss_value = 0.4
scheduler_lr.step(loss_value)
6、LambdaLR
功能:自定义调整策略
lr_scheduler.ExponentialLR(optimizer,lr_lambda,last_epoch=-1)
主要参数:
lr_lambda:function or list
如果是1个list,每1个元素也必须是1个function。
该方法适用于对不同的参数组设置不同的学习率调整策略。
# ------------------------------ 6 lambda ------------------------------
# flag = 0
flag = 1
if flag:
lr_init = 0.1
weights_1 = torch.randn((6, 3, 5, 5))
weights_2 = torch.ones((5, 5))
optimizer = optim.SGD([
{
'params': [weights_1]},
{
'params': [weights_2]}], lr=lr_init)
lambda1 = lambda epoch: 0.1 ** (epoch // 20)
lambda2 = lambda epoch: 0.95 ** epoch
scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda=[lambda1, lambda2])
lr_list, epoch_list = list(), list()
for epoch in range(max_epoch):
for i in range(iteration):
# train(...)
optimizer.step()
optimizer.zero_grad()
scheduler.step()
lr_list.append(scheduler.get_lr())
epoch_list.append(epoch)
print('epoch:{:5d}, lr:{}'.format(epoch, scheduler.get_lr()))
plt.plot(epoch_list, [i[0] for i in lr_list], label="lambda 1")
plt.plot(epoch_list, [i[1] for i in lr_list], label="lambda 2")
plt.xlabel("Epoch")
plt.ylabel("Learning Rate")
plt.title("LambdaLR")
plt.legend()
plt.show()
学习率调整策略总结
1、有序调整:Step、MultiStep、Exponential 和CosineAnnealing
学习率更新之前,就知道学习率在什么时候会调整、调整为多少;
2、自适应调整:ReduceLROnPleateau
监控某一个参数,当该参数不再上升或下降就进行学习率调整。
3、自定义调整:lambda
存在多个参数组,且需要对多个参数组设置不同的学习率调整策略可采用。
要调整学习率,至少应当具有初始学习率,那么该如何设置初始学习率?
(1)设置较小数:10e-2(0.01)、10e-3(0.001)、10e-4(0.0001);
(2)搜索最大学习率 《Cyclical learning Rates for Training Nerual Networks》