前言
之前写了一篇关于用多线程爬小说的博客,但是发现爬取16M的小说需要十几分钟,所以今天更新了一篇用多进程外加使用单线程异步的协程同样爬取之前用多线程爬取的同一篇小说,并进行两者效率的对比
本篇测试爬取的小说为《大主宰》1551章 约16M大小
步骤
全局数据列表
urls = [] #储存各章节的URL
htmls = []#储存各章节页面HTML
titles = []#储存各章节名字
process_num = 0 #进程数,一般范围为CPU内核数到50
coroutine_num = 0 #协程数
①首先依旧用chromedriver模拟登录小说网站爬取对应小说目录的网页HTML,然后用beautifulsoup筛选出我们所需要的各个章节的部分url,再加上此小说网站的基础URL构成各个章节的完整URL
(以下的chromedriver参数定义就不做多解释,以前的博文有说了)
def get_urls_titles():
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
driver = webdriver.Chrome(executable_path=driver_path, chrome_options=chrome_options)
driver.get(r'http://www.biquge.tv/0_1/')
page_source = driver.page_source
pattern2 = re.compile(r'<dd><a href="(.*?)">(.*?)</a></dd>', re.S)
All_html = re.findall(pattern2, page_source)
for ones in All_html[9:]:
urls.append(base_url+ones[0])
titles.append(ones[1])
②第二步是运用asyncio和aiohttp异步请求各个章节的URL来获取相应的HTML,存入htmls列表里面
(关于asyncio和aiohttp需要pythony3.5以上,而具体的操作可自行百度,下面需要的操作已经有注释)
async def get_html(url,title):
with(await sem):#等待其中20个协程结束才进行下一步
# async with是异步上下文管理器
async with aiohttp.ClientSession() as session: # 获取session
async with session.request('GET', url) as resp: # 提出请求
html = await resp.read() # 直接获取到bytes
htmls.append(html)
print('异步获取%s+%s下的html.' % (title,url))
def main_get_html():
loop = asyncio.get_event_loop() # 获取事件循环
tasks = [get_html(url,title) for url,title in zip(urls,titles)] # 把所有任务放到一个列表中
loop.run_until_complete(asyncio.wait(tasks)) # 激活协程
loop.close() # 关闭事件循环
③第三步是运用multiprocessing库来进行多进程解析HTML,提取我们想要的数据(文章)并生成txt下载到指定的文件夹里面
def multi_parse_html(html,title):
soup = BeautifulSoup(html, 'lxml')
content = soup.find('div', id='content').get_text()
filename = txt_path + ''.join(title.split()[0]) + '.txt'
with open(filename, 'w', encoding='utf-8') as f:
f.write("\r" + title + "\r\n")
f.write(content)
print('%s——完成解析与下载' % (title))
def main_parse_html():
p = Pool(process_num)
for html,title in zip(htmls,titles):
p.apply_async(multi_parse_html,args=(html,title))
p.close()
p.join()
全部代码如下
from multiprocessing import Pool
import time
import multiprocessing
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import re
from bs4 import BeautifulSoup
import aiohttp
import asyncio
#driverchrome安装的路径
driver_path = r'E:\py\chromedriver\chromedriver.exe'
base_url = r'http://www.biquge.tv'#爬取的小说网站URL
txt_path = r'E://py//小说//'#存储小说的路径
urls = [] #储存各章节的URL
htmls = []#储存各章节页面HTML
titles = []#储存各章节名字
process_num = 0 #进程数,一般范围为CPU内核数到50
sem = asyncio.Semaphore(40) # 信号量,控制协程数,防止爬的过快
#——————————————————————————————————————————————————#
'''
起始初始化函数,作用:获取各章节的URL和章节名,分别存入urls列表和titles列表
'''
def get_urls_titles():
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
driver = webdriver.Chrome(executable_path=driver_path, chrome_options=chrome_options)
driver.get(r'http://www.biquge.tv/0_1/')
page_source = driver.page_source
pattern2 = re.compile(r'<dd><a href="(.*?)">(.*?)</a></dd>', re.S)
All_html = re.findall(pattern2, page_source)
for ones in All_html[9:]:
urls.append(base_url+ones[0])
titles.append(ones[1])
#——————————————————————————————————————————————————#
'''
提交请求获取网页html
'''
async def get_html(url,title):
with(await sem):#等待其中20个协程结束才进行下一步
# async with是异步上下文管理器
async with aiohttp.ClientSession() as session: # 获取session
async with session.request('GET', url) as resp: # 提出请求
html = await resp.read() # 直接获取到bytes
htmls.append(html)
print('异步获取%s+%s下的html.' % (title,url))
'''
协程调用方,作用:请求网页
'''
def main_get_html():
loop = asyncio.get_event_loop() # 获取事件循环
tasks = [get_html(url,title) for url,title in zip(urls,titles)] # 把所有任务放到一个列表中
loop.run_until_complete(asyncio.wait(tasks)) # 激活协程
loop.close() # 关闭事件循环
#——————————————————————————————————————————————————#
'''
使用多进程解析html
'''
def multi_parse_html(html,title):
soup = BeautifulSoup(html, 'lxml')
content = soup.find('div', id='content').get_text()
filename = txt_path + ''.join(title.split()[0]) + '.txt'
with open(filename, 'w', encoding='utf-8') as f:
f.write("\r" + title + "\r\n")
f.write(content)
print('%s——完成解析与下载' % (title))
'''
多进程调用总函数,作用:解析html
'''
def main_parse_html():
p = Pool(processes=process_num)
for html,title in zip(htmls,titles):
p.apply_async(multi_parse_html,args=(html,title))
p.close()
p.join()
#——————————————————————————————————————————————————#
'''
总进程函数,作用:依次调用所有函数
'''
def main():
get_urls_titles()
main_get_html()
main_parse_html()
#——————————————————————————————————————————————————#
if __name__ == '__main__':
print("当前电脑的CPU为%s核" % multiprocessing.cpu_count())
process_num = int(input('请输入所需要开启的进程数:'))
start = time.time()
main()
print('总耗时:%.5f秒' % float(time.time()-start))
#——————————————————————————————————————————————————#
本次实验开启40进程和40协程 跑了30多秒

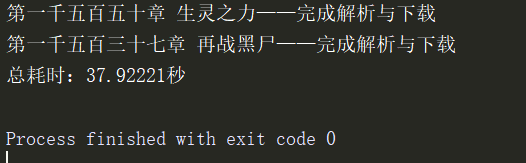
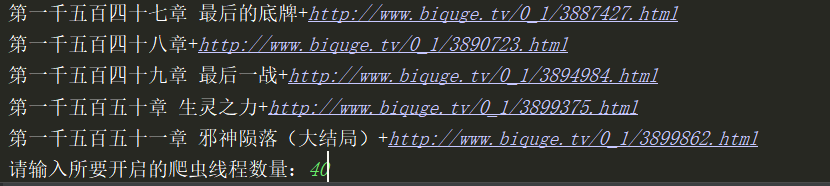
用上次的多线程爬同样小说,开启的是40线程 博文链接多线程爬虫

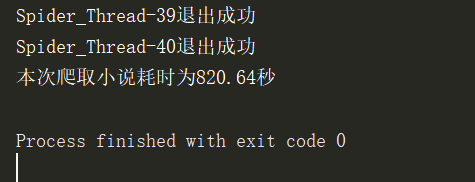
一个是30多秒 一个800多秒 效果可想而知
