多进程:
multiprocessing是python的多进程管理模块,和threading.Thread类似。我们可以利用multiprocessing.Process对象来创建一个进程。
该进程可以允许放在Python程序内部编写的函数中。该Process对象与Thread对象的用法相同,拥有is_alive()、join([timeout])、run()、start()、terminate()等方法。此外multiprocessing包中也有Lock/Event/Semaphore/Condition类,用来同步进程,其用法也与threading包中的同名类一样。
创建多进程:
如:
import multiprocessing as mp
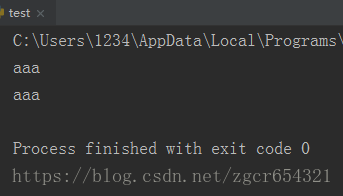
def job():
print('aaa')
if __name__=='__main__':
p1 = mp.Process(target=job, )
p2 = mp.Process(target=job, )
p1.start()
p2.start()
p1.join()
p2.join()运行截图如下:
Queue在多进程中的运用:
Queue是多进程的安全队列,可以使用Queue实现多进程之间的数据传递。
Queue的一些常用方法:
Queue.qsize():返回当前队列包含的消息数量;
Queue.empty():如果队列为空,返回True,反之False ;
Queue.full():如果队列满了,返回True,反之False;
Queue.get():获取队列中的一条消息,然后将其从列队中移除,可传参超时时长。

Queue.get_nowait():相当Queue.get(False),取不到值时触发异常:Empty;
Queue.put():将一个值添加进数列,可传参超时时长。
Queue.put_nowait():相当于Queue.get(False),当队列满了时报错:Full。
如:
import multiprocessing as mp
def job(q):
res = 0
for i in range(1000):
res += i + i ** 2
q.put(res)
# 计算出的res值放到q中
if __name__ == '__main__':
q = mp.Queue()
# 定义一个队列
p1 = mp.Process(target=job, args=(q,))
p2 = mp.Process(target=job, args=(q,))
# args内部如果只有一个参数q,q后面一定要加逗号,表示是可以迭代的
p1.start()
p2.start()
p1.join()
p2.join()
res1 = q.get()
res2 = q.get()
print(res1, res2)运行截图如下:

multithreading和multiprocessing的效率对比:
如:
import multiprocessing as mp
import threading as td
import time
from queue import Queue
def job(q):
res = 0
for i in range(1000):
res += i + i ** 2
q.put(res)
# 定义一个函数,每次加i和i的平方
# 计算出的res值放到q队列中
def multicore():
q1 = mp.Queue()
# 定义一个队列
p1 = mp.Process(target=job, args=(q1,))
p2 = mp.Process(target=job, args=(q1,))
# args内部如果只有一个参数q,q后面一定要加逗号,表示是可以迭代的
p1.start()
p2.start()
p1.join()
p2.join()
res1 = q1.get()
res2 = q1.get()
print('multicore:', res1 + res2)
def normal():
res = 0
for _ in range(2):
for i in range(1000):
res += i + i ** 2
print('normal:', res)
def multithread():
q = Queue()
# 定义一个队列
t1 = td.Thread(target=job, args=(q,))
t2 = td.Thread(target=job, args=(q,))
# args内部如果只有一个参数q,q后面一定要加逗号,表示是可以迭代的
t1.start()
t2.start()
t1.join()
t2.join()
res1 = q.get()
res2 = q.get()
print('multiThread:', res1 + res2)
if __name__ == '__main__':
st = time.time()
normal()
st1 = time.time()
print('normal time:', st1 - st)
multithread()
st2 = time.time()
print('multithread time:', st2 - st1)
multicore()
print('multicore time:', time.time() - st2)
# 计算三种不同方式所消耗的时间运行截图如下:

翻车了,按理说应该multicore时间更短的,但是这里不知道为什么时间最长,以后再研究一下。
Pool进程池:
Pool类描述了一个工作进程池。进程池内部维护一个进程序列,当使用时,则去进程池中获取一个进程,如果进程池序列中没有可供使用的进程,那么程序就会等待,直到进程池中有可用进程为止。我们可以用Pool类创建一个进程池, 展开提交的任务给进程池。
如:
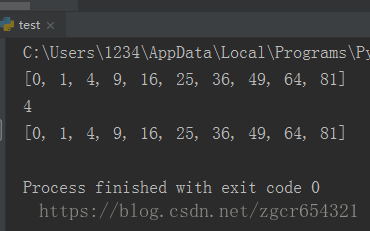
import multiprocessing as mp
def job(x):
return x * x
def multicore():
pool = mp.Pool(processes=4)
# processes参数是用几个核,默认是用全部核
res = pool.map(job, range(10))
print(res)
res = pool.apply_async(job, (2,))
print(res.get())
multi_res = [pool.apply_async(job, (i,)) for i in range(10)]
print([res.get() for res in multi_res])
if __name__ == '__main__':
multicore()运行截图如下:
共享内存shared memory:
共享内存是一种最为高效的进程间通信方式,进程可以直接读写内存,而不需要任何数据的拷贝。为了在多个进程间交换信息,内核专门留出了一块内存区,可以由需要访问的进程将其映射到自己的私有地址空间。进程就可以直接读写这一块内存而不需要进行数据的拷贝,从而大大提高效率。(文件映射)由于多个进程共享一段内存,因此也需要依靠某种同步机制。
共享内存的优缺点:
优点:快速在进程间传递数据。
缺点: 数据安全上存在风险,内存中的内容会被其他进程覆盖或者篡改。
共享内存经常和同步互斥配合使用。
基本用法:
from multiprocessing import Value , Array
Value:将一个值存放在内存中,
Array:将多个数据存放在内存中,但要求数据类型一致
设置Value或Array时要先设置其数据类型。

如:
import multiprocessing as mp
value = mp.Value('d', 1)
# https://docs.python.org/3.6/library/array.html?highlight=array#module-array
# 设置value的类型为‘d',即double类型,在python中为float
array = mp.Array('i', [1, 2, 3])
# 注意共享内存中的array不可能是多维的lock进程锁:
进程申请lock锁后,会阻塞其他进程获取lock对象,不能操作数据,只有锁释放后,其他进程可以重新获取锁对象。
我们先看看不加锁的情况。
如:
import multiprocessing as mp
import time
def job(v, num):
for _ in range(10):
time.sleep(0.1)
# 加一个sleep效果比较明显
v.value += num
print(v.value)
def multicore():
v = mp.Value('i', 0)
# 设置一个共享内存值
p1 = mp.Process(target=job, args=(v, 1))
p2 = mp.Process(target=job, args=(v, 3))
p1.start()
p2.start()
p1.join()
p2.join()
if __name__ == '__main__':
multicore()运行结果如下:
3
3
6
7
8
11
12
12
15
15
16
19
22
22
25
25
28
26
27
27可以看到结果是杂乱无章的。
我们加上lock锁以后再试一下。
如:
import multiprocessing as mp
import time
def job(v, num, l):
l.acquire()
for _ in range(10):
time.sleep(0.1)
# 加一个sleep效果比较明显
v.value += num
print(v.value)
l.release()
def multicore():
l = mp.Lock()
v = mp.Value('i', 0)
# 设置一个共享内存值
p1 = mp.Process(target=job, args=(v, 1, l))
p2 = mp.Process(target=job, args=(v, 3, l))
p1.start()
p2.start()
p1.join()
p2.join()
if __name__ == '__main__':
multicore()
运行结果如下:
3
6
9
12
15
18
21
24
27
30
31
32
33
34
35
36
37
38
39
40可以看到此时p1和p2的运行是有序的。
多线程:
cpython在使用多线程的时候,调用的是c语言的原生线程。
Python多线程的工作过程如下:
拿到公共数据;
申请gil;
python解释器调用os原生线程;
os操作cpu执行运算;
当该线程执行时间到后,无论运算是否已经执行完,gil都被要求释放;
进而由其他进程重复上面的过程;
等其他进程执行完后,又会切换到之前的线程(从他记录的上下文继续执行);
整个过程是每个线程执行自己的运算,当执行时间到就进行切换(context switch)。
多线程的一些基本操作:
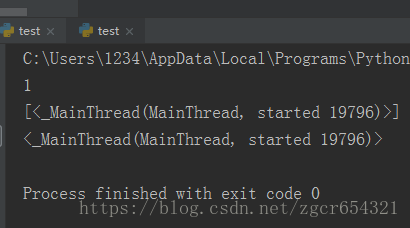
import threading
# 导入threading模块
print(threading.active_count())
# 获得已激活线程数
print(threading.enumerate())
# 查看所有线程信息
print(threading.current_thread())
# 查看现在正在运行的线程运行截图如下:
添加线程操作:
import threading
# 导入threading模块
def thread_job():
print('this is a thread of %s' % threading.current_thread())
def main():
for x in range(4):
thread = threading.Thread(target=thread_job, )
thread.start()
# 添加线程并启动线程
if __name__ == '__main__':
main()运行截图如下:

join()方法:
Python多线程与多进程中join()方法的效果是相同的。
在不同的情况下,join()方法有不同的作用:
阻塞主进程,专注于执行多线程中的程序;
多线程多join的情况下,依次执行各线程的join方法,前头一个结束了才能执行后面一个;
无参数,则等待join()过的线程结束,才开始执行下一个线程的join()。参数timeout为线程的阻塞时间,如 timeout=2 就是罩着这个线程2s 以后,就不管他了,继续执行下面的代码。
如:
import threading
import time
def T1_job():
print('T1 start\n')
for i in range(10):
time.sleep(0.1)
print('T1 finish\n')
def T2_job():
print('T2 start\n')
print('T2 finish\n')
thread_1 = threading.Thread(target=T1_job, name='T1')
thread_2 = threading.Thread(target=T2_job, name='T2')
thread_1.start()
thread_2.start()
print('all done\n')
一种可能的输出结果:

由于没有加入join()方法,程序的执行结束顺序完全取决于两个线程的执行速度, 完全有可能T2 finish出现在all done之后。
我们在thread_2.start()后加上1和2的join()方法后:
import threading
import time
def T1_job():
print('T1 start\n')
for i in range(10):
time.sleep(0.1)
print('T1 finish\n')
def T2_job():
print('T2 start\n')
print('T2 finish\n')
thread_1 = threading.Thread(target=T1_job, name='T1')
thread_2 = threading.Thread(target=T2_job, name='T2')
thread_1.start()
thread_2.start()
thread_1.join()
thread_2.join()
print('all done\n')运行截图如下:

此时就是上面列举的四种情况之一:join()阻塞了主进程,专注于执行多线程中的程序,多线程均执行完后,才继续执行主进程。
如果我们在T1启动后就放上thread_1.join()呢?
import threading
import time
def T1_job():
print('T1 start\n')
for i in range(10):
time.sleep(0.1)
print('T1 finish\n')
def T2_job():
print('T2 start\n')
print('T2 finish\n')
thread_1 = threading.Thread(target=T1_job, name='T1')
thread_2 = threading.Thread(target=T2_job, name='T2')
thread_1.start()
thread_1.join()
thread_2.start()
thread_2.join()
print('all done\n')运行截图如下:

可以看到此时T2在T1之后启动,因为T1的join()方法在T2启动之前。即多线程多join的情况下,依次执行各线程的join方法,前头一个结束了才能执行后面一个。
用Queue储存进程结果:
举一个例子:
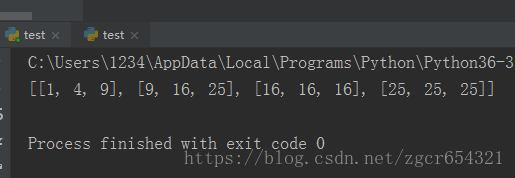
import threading
from queue import Queue
def job(l, q):
# 定义一个功能函数
for i in range(len(l)):
l[i] = l[i] ** 2
# **2表示平方
q.put(l)
# 多线程调用的函数不能用return返回值
def multithreading():
# 多线程函数中定义个Queue队列,用于保存返回值,代替return
q = Queue()
threads = []
data = [[1, 2, 3], [3, 4, 5], [4, 4, 4], [5, 5, 5]]
for i in range(4):
t = threading.Thread(target=job, args=(data[i], q))
t.start()
threads.append(t)
# 把每个线程添加到线程列表中
for thread in threads:
thread.join()
# 四个线程join到主线程
results = []
# 定义一个空的列表results,将四个线运行后保存在队列中的结果返回给空列表results
for _ in range(4):
results.append(q.get())
# 按顺序从队列中取出值
print(results)
if __name__ == '__main__':
multithreading()运行截图如下:
线程锁Lock:
在不使用Lock的情况:
不使用lock时,如果不同的线程都要访问并修改同一个全局变量,由于各个线程执行的次序可能不同,最后结果可能会很混乱。
import threading
def job1():
global A
for i in range(10):
A+=1
print('job1',A)
def job2():
global A
for i in range(10):
A+=10
print('job2',A)
if __name__== '__main__':
lock=threading.Lock()
A=0
t1=threading.Thread(target=job1)
t2=threading.Thread(target=job2)
t1.start()
t2.start()
t1.join()
t2.join()
在cmd中运行该.py文件,结果如下:
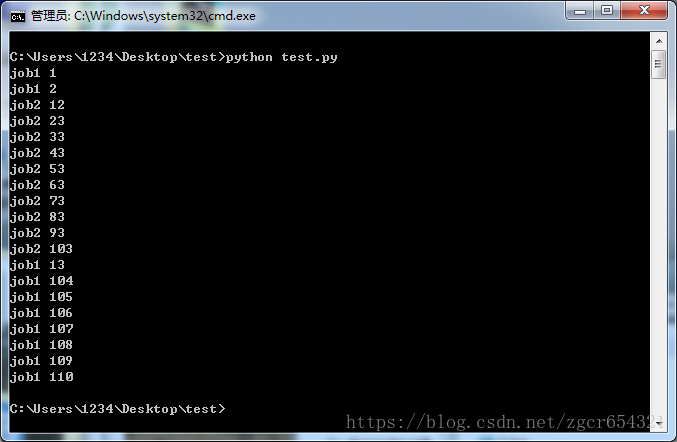
使用lock的情况:
lock在不同线程使用同一共享内存时,能够确保线程之间互不影响。
使用lock的方法是, 在每个线程执行运算修改共享内存之前,执行lock.acquire()将共享内存上锁, 确保当前线程执行时,内存不会被其他线程访问,执行运算完毕后,使用lock.release()将锁打开, 保证其他的线程可以使用该共享内存。
如:
import threading
def job1():
global A, lock
lock.acquire()
for i in range(10):
A += 1
print('job1', A)
lock.release()
# 全局变量每次加1 循环10次
def job2():
global A, lock
lock.acquire()
for i in range(10):
A += 10
print('job2', A)
lock.release()
# 全局变量每次加1 循环10次
if __name__ == '__main__':
lock = threading.Lock()
A = 0
t1 = threading.Thread(target=job1)
t2 = threading.Thread(target=job2)
# 创建两个线程,一个运行job1,一个运行job2
t1.start()
t2.start()
t2.join()
t1.join()
运行结果如下:
job1 1
job1 2
job1 3
job1 4
job1 5
job1 6
job1 7
job1 8
job1 9
job1 10
job2 20
job2 30
job2 40
job2 50
job2 60
job2 70
job2 80
job2 90
job2 100
job2 110
GIL导致Python多线程不一定有效率:
python的多线程threading有时候并不是特别理想,最主要的原因是就是Python 的设计上, 有一个必要的环节, 就是 Global Interpreter Lock (GIL)。这个机制让Python同一时间只能执行一个线程。
我们可以把GIL看作是“通行证”,并且在一个python进程中,GIL只有一个。拿不到通行证的线程,就不允许进入CPU执行。GIL只在cpython中才有,因为cpython调用的是c语言的原生线程,所以他不能直接操作cpu,只能利用GIL保证同一时间只能有一个线程拿到数据。而在pypy和jpython中是没有GIL的。
有一点要强调的是GIL只会影响到那些严重依赖CPU的程序(比如一个使用了多个线程的计算密集型程序)。如果你的程序大部分只会涉及到I/O,比如网络交互,那么使用多线程就很合适, 因为它们大部分时间都在等待。
在python2.x里,GIL的释放逻辑是当前线程遇见IO操作或者ticks计数达到100时进行释放。(ticks可以看作是python自身的一个计数器,专门做用于GIL,每次释放后归零,这个计数可以通过sys.setcheckinterval 来调整)。每次释放GIL锁,线程进行锁竞争、切换线程,会消耗资源。并且由于GIL锁存在,python里一个进程永远只能同时执行一个线程(拿到GIL的线程才能执行),这就是为什么在多核CPU上,python的多线程效率并不高。
在python3.x中,GIL不使用ticks计数,改为使用计时器(执行时间达到阈值后,当前线程释放GIL),这样对CPU密集型程序更加友好,但依然没有解决GIL导致的同一时间只能执行一个线程的问题,所以效率依然不尽如人意。
建议:
python下想要充分利用多核CPU,就用多进程。因为每个进程有各自独立的GIL,互不干扰,这样就可以真正意义上的并行执行,在python中,多进程的执行效率优于多线程(仅仅针对多核CPU而言)。
下面举一个测试GIL的例子:
import threading
from queue import Queue
import copy
import time
# 创建一个job, 分别用 threading 和一般的方式执行这段程序。
# 并且创建一个 list 来存放我们要处理的数据。在一般方式下,我们这个list扩展4倍, 在 threading的时候, 我们建立4个线程。
def job(l, q):
# 创建一个用多线程做连续加法的函数
res = sum(l)
q.put(res)
def multithreading(l):
q = Queue()
# 创建一个队列保存结果
threads = []
# 创建一个保存线程的列表
for i in range(4):
t = threading.Thread(target=job, args=(copy.copy(l), q), name='T%i' % i)
t.start()
threads.append(t)
# 创建四个线程,并保存到线程列表
[t.join() for t in threads]
# 四个线程join到主线程
total = 0
for _ in range(4):
total += q.get()
# 计算四个线程的结果的和
print(total)
def normal(l):
total = sum(l)
print(total)
if __name__ == '__main__':
l = list(range(1000000))
s_t = time.time()
# 记录计算开始时间
normal(l * 4)
# l内所有数相加并且乘4
print('normal:', time.time() - s_t)
# 打印计算用时
s_t = time.time()
multithreading(l)
print('multithreading:', time.time() - s_t)
if __name__ == '__main__':
l = list(range(1000000))
s_t = time.time()
normal(l*4)
print('normal: ',time.time()-s_t)
s_t = time.time()
multithreading(l)
print('multithreading: ', time.time()-s_t)运行截图如下:

可以看到多线程运算的时间反而更长一点。这就是GIL设计的原因,因为函数基本是纯CPU计算型,而多线程还要耗费时间切换线程。
异步:
无论是线程还是进程,使用的都是同步IO机制,并且每次阻塞、切换都需要陷入系统调用(system call),先让CPU跑操作系统的调度程序,然后再由调度程序决定该跑哪一个进程(线程)。多个线程之间在一些访问互斥的代码时还需要加上锁。
考虑到CPU和IO之间巨大的速度差异,一个任务在执行的过程中大部分时间都在等待IO操作,单进程单线程模型会导致别的任务无法并行执行,因此,我们才需要多进程模型或者多线程模型来支持多任务并发执行。
现代操作系统对IO操作已经做了巨大的改进,最大的特点就是支持异步IO。如果充分利用操作系统提供的异步IO支持,就可以用单进程单线程模型来执行多任务,这种全新的模型称为事件驱动模型,Nginx就是支持异步IO的Web服务器,它在单核CPU上采用单进程模型就可以高效地支持多任务。
用异步IO编程模型来实现多任务是一个主要的趋势。对应到Python语言,单进程的异步编程模型称为协程,有了协程的支持,就可以基于事件驱动编写高效的多任务程序。
当一个异步过程调用发出后,调用者不会立刻得到结果。实际处理这个调用的部件是在调用发出后,通过状态、通知来通知调用者,或通过回调函数处理这个调用。
阻塞和非阻塞的区别:
阻塞/非阻塞, 是程序在等待消息(无所谓同步或者异步)时的状态。
阻塞:
阻塞调用是指调用结果返回之前,当前线程会被挂起。函数只有在得到结果之后才会返回。
非阻塞:
非阻塞和阻塞的概念相对应,指在不能立刻得到结果之前,该函数不会阻塞当前线程,而会立刻返回。一般异步是配合非阻塞使用的,这样才能发挥异步的效用。
下面是一个同步阻塞、同步非阻塞、异步阻塞、异步非阻塞的比喻:
老张爱喝茶,喝茶要煮开水。有两把水壶,一把是普通的水壶,一把是水开了会响提示老张的水壶。
1、老张把普通水壶放到火上,在水壶前等水开。这就是同步阻塞。
2、老张把普通水壶放到火上,去客厅看电视,时不时去水壶那里看看水开了没有。这就是同步非阻塞。
3 、老张把响水壶放到火上,在水壶前等水开。这就是异步阻塞。
4、老张把响水壶放到火上,去客厅看电视,水壶响之前不再去看它了,听到响了再去拿壶。这就是异步非阻塞。
上面的例子中普通水壶是同步,响水壶是异步。同步只能让调用者去轮询自己(情况1、2)。所谓阻塞非阻塞,仅仅对于老张而言。在水壶前等的老张是阻塞,看电视的老张是非阻塞。情况1和情况3中老张就是阻塞的。
虽然情况3中响水壶是异步的,可对于在水壶等的老张没有太大的意义。所以一般异步是配合非阻塞使用的,这样才能发挥异步的效用。
协程:
协程又叫做微线程,协程是一种用户态的轻量级的线程,操作系统根本就不知道协程的存在,完全由用户来控制,协程拥有自己的的寄存器的上下文和栈,协程调度切换时,将寄存器上下文和栈保存到其他地方,在切换回来后,恢复之前保存的寄存器的上下文关系,因此协程能保留上一次调用的状态,每次过程重入的时候,就相当于进入上一次调用的状态。
协程只使用一个线程,分解一个线程成为多个“微线程”。协程的切换是在线程中切换,和单个线程在cpu之间不停的切换是一样的 但是线程切换是cpu控制的,而协程的切换是用户控制的。
Python中的协程是通过“生成器(generator)”的概念实现的。
关于生成器的概念:
当我们调用一个普通的python函数,一般是从函数的第一行代码开始执行,结束于return语句、异常或者函数执行(也可以认为是隐式地返回了None)。return隐含的意思是函数正将执行代码的控制权返回给函数被调用的地方。一旦函数将控制权交还给调用者,就意味着全部结束。
我们也可以创建能产生一个序列的函数,来“保存自己的工作”,这就是生成器(使用了yield关键字的函数)。能够“产生一个序列”是因为函数并没有像通常意义那样return返回,而是使用yield返回。"yield"的隐含意思是控制权的转移是临时和自愿的,我们的函数将来还会收回控制权。
一般使用第三方模块gevent和greenlet。优先使用gevent,因为gevent是对greenlet的高级封装。
先看一个使用gevent的例子:
from gevent import monkey;
monkey.patch_all()
import gevent
import requests
def f(url):
print('GET: %s' % url)
resp = requests.get(url)
data = resp.text
print('%d bytes received from %s.' % (len(data), url))
gevent.joinall([
gevent.spawn(f, 'https://www.zhihu.com/'),
gevent.spawn(f, 'https://www.baidu.com/'),
gevent.spawn(f, 'https://www.csdn.net/'),
])运行截图如下:

通过joinall将任务f和它的参数进行统一调度,实现单线程中的协程。
再看一个使用greenlet的例子:
from greenlet import greenlet
def test1():
print(12)
gr2.switch()
print(34)
gr2.switch()
def test2():
print(56)
gr1.switch()
print(78)
gr1 = greenlet(test1)
gr2 = greenlet(test2)
gr1.switch()运行截图如下:
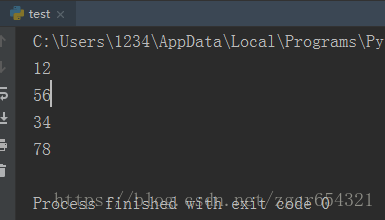
greenlet就是通过switch方法在不同的任务之间进行切换。
python针对不同类型的代码执行效率不同:
CPU密集型代码(各种循环处理、计算等等),由于计算工作多,ticks计数很快就会达到阈值,然后触发GIL的释放与再竞争(多个线程来回切换当然是需要消耗资源的),所以python下的多线程对CPU密集型代码并不友好。
IO密集型代码(文件处理、网络爬虫等涉及文件读写的操作),多线程能够有效提升效率(单线程下有IO操作会进行IO等待,造成不必要的时间浪费,而开启多线程能在线程A等待时,自动切换到线程B,可以不浪费CPU的资源,从而能提升程序执行效率)。所以python的多线程对IO密集型代码比较友好。