python3爬虫系列18之多进程爬取2009-2019十年高考分数线
1. 前言
上一篇文章是
python3爬虫系列17之爬虫增速多进程,进程池的用法(白话解释),在里面我们知道了用来爬虫加速的多进程和进程池的创建使用方式。
而之前的多线程爬虫例子python3爬虫系列16之多线程爬取汽车之家批量下载图片,看到python中使用多线程好像并不是很快。
最后得出的结论是 在 Python 里面推荐使【用多进程】而【不用多线程】。

2. 多进程爬取2009-2019十年高考分数线
网页分析,在之前写过一个 python3爬虫系列13之find_all爬虫高考分数线并绘制分析图(普通版),那么今天就写一个这个的加强版。
多进程爬虫—采用多进程库multiprocessing中进程池Pool类实现的多进程,是同步的。
【直接取全国 31 个省份的高考录取分数线,分别是文理科的一本和二本。】
目标地址:
url = 'http://www.gaokao.com/guangdong/fsx/'
在前面的篇中,我们采用的是手动输入地区名字,然后汉字转拼音来拼接url。
再进行指定地区的分数线爬虫。
现在改为 自动获取各个省份的url,然后存入url管理器里面去。
再挨个拿出来。
新建一个url管理器:get_provice(url) 函数:
# 获取省份及链接
pro_link = []
def get_provice(url):
web_data = requests.get(url, headers=header)
soup = BeautifulSoup(web_data.content, 'lxml')
provice_link = soup.select('.area_box > a')
for link in provice_link:
href = link['href']
provice = link.select('span')[0].text
data = {
'href': href,
'provice': provice
}
# 可以入库了
print('各个省份链接:',data)
pro_link.append(href)
print('各省url查找OK')
拿到各个省份的URL以后,我们在获取分数线,对应代码的解释在里面。
# 获取分数线
def get_score(url):
web_data = requests.get(url, headers=header)
soup = BeautifulSoup(web_data.content, 'lxml')
global score_data
# 获取省份信息
provice = soup.select('.col-nav span')[0].text[0:-5]
print('========',provice,'============')
# 获取文理科
categories = soup.select('h3.ft14')
category_list = []
for item in categories:
category_list.append(item.text.strip().replace(' ', '')) # 移除字符串头尾指定的字符(空格)
# 获取分数
tables = soup.select('h3 ~ table')
for index, table in enumerate(tables): # 枚举-同时列出数据和数据下标
print('进入')
tr = table.find_all('tr', attrs={'class': re.compile('^c_\S*')})
for j in tr:
td = j.select('td')
score_list = []
score_line = []
for k in td:
# 获取每年的分数
if 'class' not in k.attrs:
score = k.text.strip()
score_list.append(score)
# 获取分数线类别
elif 'class' in k.attrs:
score_line = k.text.strip()
# print(type(score_line))
print("当前省份数据已保存。")
最后整理为字典,然后入库或者是本地备份。
score_data = {
'provice': provice.strip(), # 省份
'category': category_list[index], # 文理科分类
'score_line': score_line, # 分数线类别
'score_list': score_list # 分数列表
}
print('字典:',score_data)
# 可入库,可备份
files = open('gaokaofsx.json', 'w', encoding='utf-8')
# 转为json对象-写入文件
files.write(json.dumps(score_data, ensure_ascii=False) + '\n')
files.close()
最后开启多进程来加速:
# 使用多线程
pool = Pool()
pool.map(get_score, [i for i in pro_link]) # 调用分数查询,采用不同的url
print("用时: {}".format(time.time() - start))
完整代码如下:
#!/usr/bin/python3
"""
多进程爬虫-高考
采用多进程库multiprocessing中进程池Pool类,
用multiprocessing库实现多进程,是同步。
"""
import json
from multiprocessing.pool import Pool # 用进程池的方式批量创建子进程
import requests
from bs4 import BeautifulSoup
import re
import time
from fake_useragent import UserAgent
ua = UserAgent()
headers = {
'User-Agent': ua.random, # 伪装headers
'Connection': 'keep - alive'
}
# 获取省份及链接
pro_link = []
def get_provice(url):
web_data = requests.get(url, headers=headers)
soup = BeautifulSoup(web_data.content, 'lxml')
provice_link = soup.select('.area_box > a')
for link in provice_link:
href = link['href']
provice = link.select('span')[0].text
data = {
'href': href,
'provice': provice
}
# 可以入库了
print('各个省份链接:',data)
pro_link.append(href)
print('各省url查找OK')
# 获取分数线
def get_score(url):
web_data = requests.get(url, headers=header)
soup = BeautifulSoup(web_data.content, 'lxml')
global score_data
# 获取省份信息
provice = soup.select('.col-nav span')[0].text[0:-5]
print('========',provice,'============')
# 获取文理科
categories = soup.select('h3.ft14')
category_list = []
for item in categories:
category_list.append(item.text.strip().replace(' ', '')) # 移除字符串头尾指定的字符(空格)
# 获取分数
tables = soup.select('h3 ~ table')
for index, table in enumerate(tables): # 枚举-同时列出数据和数据下标
print('进入')
tr = table.find_all('tr', attrs={'class': re.compile('^c_\S*')})
for j in tr:
td = j.select('td')
score_list = []
score_line = []
for k in td:
# 获取每年的分数
if 'class' not in k.attrs:
score = k.text.strip()
score_list.append(score)
# 获取分数线类别
elif 'class' in k.attrs:
score_line = k.text.strip()
# print(type(score_line))
score_data = {
'provice': provice.strip(), # 省份
'category': category_list[index], # 文理科分类
'score_line': score_line, # 分数线类别
'score_list': score_list # 分数列表
}
print('字典:',score_data)
# 可入库,可备份
files = open('gaokaofsx.json', 'w', encoding='utf-8')
# 转为json对象-写入文件
files.write(json.dumps(score_data, ensure_ascii=False) + '\n')
files.close()
print("当前省份数据已保存。")
if __name__ == '__main__':
start = time.time()
url = 'http://www.gaokao.com/guangdong/fsx/'
get_provice(url) # 调用获取省份url
# 使用多线程
pool = Pool()
pool.map(get_score, [i for i in pro_link]) # 调用分数查询,采用不同的url
print("用时: {}".format(time.time() - start))
最后的可视化可以参考爬虫系列13的文章就是一个封装的方法调用。
# 历年高考录取分数线绘图
def keshihua(diquname,like,wenke,nianfen):
print(like)
# 为了好看,只要一二本数据。
wenkeYb = wenke[:12]
wenkeEb = wenke[12:24]
likeYb = like[:12]
likeEb = like[12:24]
# 绘图
c = Bar(init_opts=opts.InitOpts(theme=ThemeType.SHINE))
c.add_xaxis([list(z) for z in zip(nianfen)]) # 年份-记住怎么读取出来的!
c.add_yaxis('文科一本',[wenkeYb[i] for i in range(1,len(wenkeYb))]) # 去掉'一本'
c.add_yaxis('理科一本', [likeYb[i] for i in range(1,len(likeYb))])
c.add_yaxis('文科二本', [wenkeEb[i] for i in range(1,len(wenkeEb))])
c.add_yaxis('理科二本',[likeEb[i] for i in range(1,len(likeEb))])
c.set_global_opts(title_opts=opts.TitleOpts(title=diquname +'历年高考录取分数线图',subtitle='2009-2019年'))
c.render(diquname +'历年高考录取分数线图.html')
print(diquname + '历年高考录取分数线图绘制完成。')
运行效果:
各省份URL

各省份文理科分数

多进程加速:

从这里可以看到,对比于之前的普通爬虫,我们用了 12.445056438446045秒的时间来爬完数据的。

采用多进程的爬虫方式更有利于我们的数据采集。
可视化:
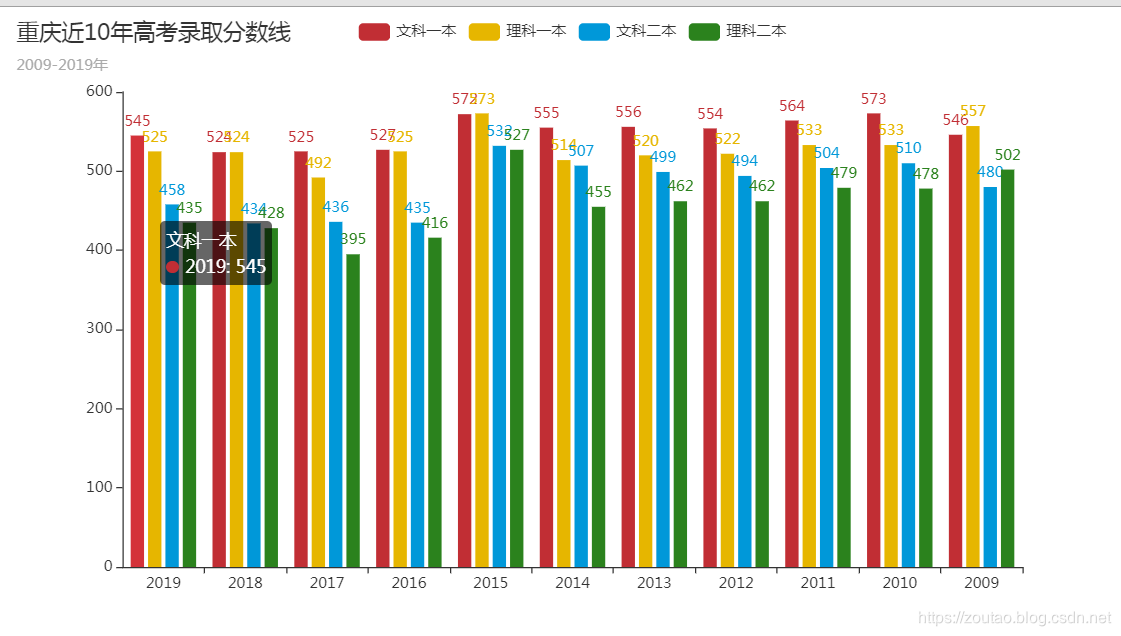
关于多线程,多进程这个篇幅的已经差不多了,分别进行了解释和相关代码,主要是要学习使用的方式,举一反三,这样才能得到应用,如果只是单纯的copy代码去跑一下,那是不行的。
.
有什么问题,请留言吧。下一篇见。
( ^ _ ^ )/~~拜拜
