引子
最近把所有系统的python3 版本都更新到了python3.7,然后更新了一下代码,发现这个版本改动还是很大的,之前更多还是在使用python2.7做ETL或者操作一些API,没想到python的变化如此之大,看来自己还是太落伍了。于是在知乎和官网上找资料学习了下,看到一篇讲协程的文章很受启发,以后应该会较多使用这个功能,之前使用的多进程多线程效果都不明显,而协程应该是一个python的效率利器。
前言
多进程和多线程除了创建的开销大之外还有一个难以根治的缺陷,就是处理进程之间或线程之间的协作问题,因为是依赖多进程和多线程的程序在不加锁的情况下通常是不可控的,而协程则可以完美地解决协作问题,由用户来决定协程之间的调度。
总所周知,Python因为有GIL(全局解释锁)这玩意,不可能有真正的多线程的存在,因此很多情况下都会用multiprocessing实现并发,而且在Python中应用多线程还要注意关键地方的同步,不太方便,用协程代替多线程和多进程是一个很好的选择,因为它吸引人的特性:主动调用/退出,状态保存,避免cpu上下文切换等…
协程
基本概念
协程,又称作Coroutine,通过 async/await 语法进行声明,是编写异步应用的推荐方式。
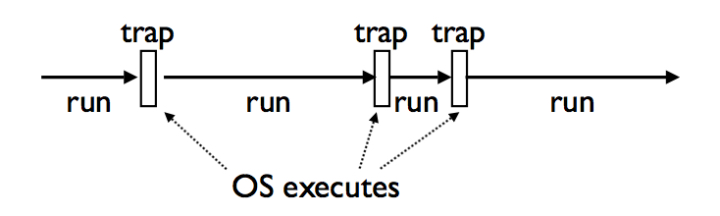
从字面上来理解,即协同运行的例程,它是比是线程(thread)更细量级的用户态线程,特点是允许用户的主动调用和主动退出,挂起当前的例程然后返回值或去执行其他任务,接着返回原来停下的点继续执行。等下,这是否有点奇怪?我们都知道一般函数都是线性执行的,不可能说执行到一半返回,等会儿又跑到原来的地方继续执行。但一些熟悉python(or其他动态语言)的童鞋都知道这可以做到,答案是用yield语句。其实这里我们要感谢操作系统(OS)为我们做的工作,因为它具有getcontext和swapcontext这些特性,通过系统调用,我们可以把上下文和状态保存起来,切换到其他的上下文,这些特性为coroutine的实现提供了底层的基础。操作系统的Interrupts和Traps机制则为这种实现提供了可能性,因此它看起来可能是下面这样的:
>>> import asyncio
>>> async def main():
... print('hello')
... await asyncio.sleep(1)
... print('world')
>>> asyncio.run(main())
hello
world
理解生成器(generator)
学过生成器和迭代器的同学应该都知道python有yield这个关键字,yield能把一个函数变成一个generator,与return不同,yield在函数中返回值时会保存函数的状态,使下一次调用函数时会从上一次的状态继续执行,即从yield的下一条语句开始执行,这样做有许多好处,比如我们想要生成一个数列,若该数列的存储空间太大,而我们仅仅需要访问前面几个元素,那么yield就派上用场了,它实现了这种一边循环一边计算的机制,节省了存储空间,提高了运行效率。
运行协程
-
asyncio.run()函数用来运行最高层级的入口点 “main()” 函数 -
等待一个协程。以下代码段会在等待 1 秒后打印 “hello”,然后 再次 等待 2 秒后打印 “world”:
import asyncio import time async def say_after(delay, what): await asyncio.sleep(delay) print(what) async def main(): print(f"started at {time.strftime('%X')}") await say_after(1, 'hello') await say_after(2, 'world') print(f"finished at {time.strftime('%X')}") asyncio.run(main()) -
asyncio.create_task()函数用来并发运行作为 asyncio任务的多个协程。async def main(): task1 = asyncio.create_task( say_after(1, 'hello')) task2 = asyncio.create_task( say_after(2, 'world')) print(f"started at {time.strftime('%X')}") # Wait until both tasks are completed (should take # around 2 seconds.) await task1 await task2 print(f"finished at {time.strftime('%X')}")
可等待对象
如果一个对象可以在 await 语句中使用,那么它就是 可等待 对象。许多 asyncio API 都被设计为接受可等待对象。
可等待 对象有三种主要类型: 协程, 任务 和 Future.
协程
Python 协程属于 可等待 对象,因此可以在其他协程中被等待:
import asyncio
async def nested():
return 42
async def main():
# Nothing happens if we just call "nested()".
# A coroutine object is created but not awaited,
# so it *won't run at all*.
nested()
# Let's do it differently now and await it:
print(await nested()) # will print "42".
asyncio.run(main())
重要
在本文档中 “协程” 可用来表示两个紧密关联的概念:
- 协程函数: 定义形式为
async def的函数; - 协程对象: 调用 协程函数 所返回的对象。
asyncio 也支持旧式的 基于生成器的 协程。
任务
任务 被用来设置日程以便 并发 执行协程。
当一个协程通过 asyncio.create_task() 等函数被打包为一个 任务,该协程将自动排入日程准备立即运行:
import asyncio
async def nested():
return 42
async def main():
# Schedule nested() to run soon concurrently
# with "main()".
task = asyncio.create_task(nested())
# "task" can now be used to cancel "nested()", or
# can simply be awaited to wait until it is complete:
await task
asyncio.run(main())
Future 对象
Future 是一种特殊的 低层级 可等待对象,表示一个异步操作的 最终结果。
当一个 Future 对象 被等待,这意味着协程将保持等待直到该 Future 对象在其他地方操作完毕。
在 asyncio 中需要 Future 对象以便允许通过 async/await 使用基于回调的代码。
通常情况下 没有必要 在应用层级的代码中创建 Future 对象。
Future 对象有时会由库和某些 asyncio API 暴露给用户,用作可等待对象:
async def main():
await function_that_returns_a_future_object()
# this is also valid:
await asyncio.gather(
function_that_returns_a_future_object(),
some_python_coroutine()
)
一个很好的返回对象的低层级函数的示例是 loop.run_in_executor()。
并发运行任务
awaitable asyncio.gather(*aws, loop=None, return_exceptions=False)
并发 运行 aws 序列中的 可等待对象。
如果 aws 中的某个可等待对象为协程,它将自动作为一个任务加入日程。
如果所有可等待对象都成功完成,结果将是一个由所有返回值聚合而成的列表。结果值的顺序与 aws 中可等待对象的顺序一致。
如果 return_exceptions 为 False (默认),所引发的首个异常会立即传播给等待 gather() 的任务。aws序列中的其他可等待对象 不会被取消 并将继续运行。
如果 return_exceptions 为 True,异常会和成功的结果一样处理,并聚合至结果列表。
如果 gather() 被取消,所有被提交 (尚未完成) 的可等待对象也会 被取消。
如果 aws 序列中的任一 Task 或 Future 对象 被取消,它将被当作引发了 CancelledError 一样处理 – 在此情况下 gather() 调用 不会 被取消。这是为了防止一个已提交的 Task/Future 被取消导致其他 Tasks/Future 也被取消。
import asyncio
async def factorial(name, number):
f = 1
for i in range(2, number + 1):
print(f"Task {name}: Compute factorial({i})...")
await asyncio.sleep(1)
f *= i
print(f"Task {name}: factorial({number}) = {f}")
async def main():
# Schedule three calls *concurrently*:
await asyncio.gather(
factorial("A", 2),
factorial("B", 3),
factorial("C", 4),
)
asyncio.run(main())
# Expected output:
#
# Task A: Compute factorial(2)...
# Task B: Compute factorial(2)...
# Task C: Compute factorial(2)...
# Task A: factorial(2) = 2
# Task B: Compute factorial(3)...
# Task C: Compute factorial(3)...
# Task B: factorial(3) = 6
# Task C: Compute factorial(4)...
# Task C: factorial(4) = 24
爬虫例子
使用爬虫爬取豆瓣top250
from lxml import etree
from time import time
import asyncio
import aiohttp
url = "https://movie.douban.com/top250"
header = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36",
"content-type": "text/plain;charset=UTF-8",
}
async def fetch_content(url):
# await asyncio.sleep(1) # 防止请求过快 等待1秒
async with aiohttp.ClientSession(
headers=header, connector=aiohttp.TCPConnector(ssl=False)
) as session:
async with session.get(url) as response:
return await response.text()
async def parse(url):
page = await fetch_content(url)
html = etree.HTML(page)
xpath_movie = '//*[@id="content"]/div/div[1]/ol/li'
xpath_title = './/span[@class="title"]'
xpath_pages = '//*[@id="content"]/div/div[1]/div[2]/a'
xpath_descs = './/span[@class="inq"]'
xpath_links = './/div[@class="info"]/div[@class="hd"]/a'
pages = html.xpath(xpath_pages) # 所有页面的链接都在底部获取
fetch_list = []
result = []
for element_movie in html.xpath(xpath_movie):
result.append(element_movie)
for p in pages:
fetch_list.append(url + p.get("href")) # 解析翻页按钮对应的链接 组成完整后边页面链接
tasks = [fetch_content(url) for url in fetch_list] # 并行处理所有翻页的页面
pages = await asyncio.gather(*tasks)
# 并发 运行 aws 序列中的 可等待对象。
# 如果 aws 中的某个可等待对象为协程,它将自动作为一个任务加入日程。
# 如果所有可等待对象都成功完成,结果将是一个由所有返回值聚合而成的列表。结果值的顺序与 aws 中可等待对象的顺序一致。
for page in pages:
html = etree.HTML(page)
for element_movie in html.xpath(xpath_movie):
result.append(element_movie)
for i, movie in enumerate(result, 1):
title = movie.find(xpath_title).text
desc = (
"<" + movie.find(xpath_descs).text + ">"
if movie.find(xpath_descs) is not None
else None
)
link = movie.find(xpath_links).get("href")
print(i, title, desc, link)
async def main():
start = time()
for i in range(5):
await parse(url)
end = time()
print("Cost {} seconds".format((end - start) / 5))
if __name__ == "__main__":
asyncio.run(main())
