Day Day Up
广义表
引入
广义表是线性表的推广,将线性的表推广到平面。
定义
广义表:是(n≥0)的元素组成的 有限 的序列,当 n=0 时,称为空表。
空表的表示: (#)
元素组成
GL = {a1,a2,a3,a4,a5,a6};
原子:当a1是一个元素时,称为原子,深度为0
子表:当a1是一个广义表时,称为子表,深度为1
重要的特性
- 广义表的数据元素既可以
原子也可以是子表 - 广义表的元素是有序的,数据
元素是有限的(深度可以是无限的) - 广义表的
长度:最外一层所包含的元素个数 - 广义表的
深度:括号的重数(数一下左括号个数) - 广义表是可以共享的
- 广义表可以是递归的,自己可以是自己的子表,
此时深度是无限的,长度是有限的 - 广义表的拆分:可以分为表头,和表尾,其中表尾是用
( )括起来的,所以表尾一定是一个广义表
表名
名为A的空表:A(#)
无名的空表:· (#) 注意前面的点,表示匿名
广义表字符串表示转图形表示
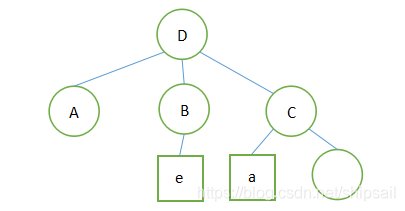
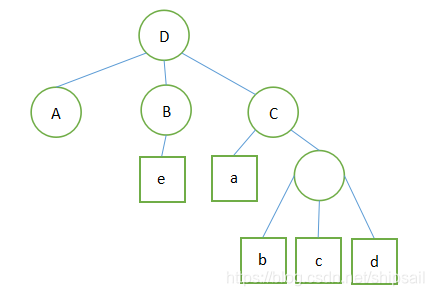
例:D( A(#) , B(e) , C(a,(b,c,d) ))
- D是一个广义表,
元素为表A,表B,表C
- 表A为空表,表B的元素为e,表C的元素为a,匿名表
- 该匿名表中元素为 b c d
储存结构

- tag:标记结点的类型
- union联合域:根据tag做不同的处理
- link:指向兄弟结点,或者置NULL
空表的结构

空表 不是 ghead == NULL,而是 ghead->sublist == NULL
两种方法理解递归性
解决1:对
广义表的操作是一致的,子表也是一个独立的广义表
void func1(Node * g){
// param g : 广义表的头结点
Node * g1 = g->sublist; //指向该表的第一个元素
while(g1 != NULL){ //判断是否遍历完了这个广义表
if(g1->tag == 1) func(g1); //处理子表元素,传入的g1为子表的表头
else {
//处理原子操作
}
g1 = g1->link; // 指向兄弟结点
}
}
解决2:对
广义表的结点操作是一致的
void func2(Node * g){
//param g : 广义表结点
if(g == NULL) // 递归结束条件
return;
if(g->tag == 1)//该结点为子表
func2(g->sublist); //处理子表的第一个元素结点
else
func2(g->link); //处理兄弟结点
}
广义表运算
求表长度
思路:不用深入,横向扫到NULL
int getLength(){
int ans = 0;
Node * g1 = ghead->sublist; //获取第一个元素的地址,ghead为广义表的表头结点
while(g1!=NULL){
ans++;
g1 = g1 -> link; //跳转到兄弟结点
}
return ans;
}
求表深度(我感觉这个挺难懂的)
注意点:
- 空表的深度是 1
- 原子的深度是 0
- 子表是深度是 1
int getDepth(){
return getDepth(ghead); //传入的是表头结点
}
// 用于递归调用
int getDepth1(Node * g){
int max = 0,dep;
if(g->tag == 0) return 0; //判断头结点为原子
Node g1 = g->sublist; //已经确定是子表,则指向首元素
if(g1->link ==NULL) return 1;//子表为空表
while(g1 != NULL){ // 遍历该非空子表
if(g1->tag == 1){
dep = getDepth1(g1); //递归调用子表元素
if(dep > max) max = dep;//更新最大值
}
g1 = g1 -> link; //指向兄弟结点
}
return max + 1; // 返回表的深度 + 自身的深度1
}
广义表字符串转链式储存(重点)
从左到右扫字符串
- 遇到 #:说明前面的广义表是空表
- 遇到 (:说明是一个广义表
- 遇到) :最近的一个广义表结束了
- 遇到,:添加一个兄弟结点
Node* create1(char* &s){
Node * g;
char chr = * s++; //获取后自增 s++,是指针的自增
if(chr != '\0'){
g = new Node;
if (ch == '('){
//左括号说明遇到了一个子表
g -> tag =1;
g -> sublist = create1(s);
}
else if(ch == '#' ) delete g ; g = NULL; //空表
else{
// 是一个原子
g->tag = 0;
g->data = ch;
}
}else delete g ; g = NULL;//结束遍历
//以下为处理兄弟的部分
ch = * s++;//取下一个字符
if(g!=NULL){
if(ch == ','){
g->link = create1(s);
}else{
g->link = NULL;
}
}
return g;
}
