一切来不的猝不及防
一个半月前,武汉还是那个纵横江湖、肆意人间的武汉。165条江河日夜奔流,100多种不重样的过早热气蒸腾,两江四岸13千米长的沿江灯光秀将889个楼宇依次点亮,灯影重重、觥筹交错。武汉从来不缺人间烟火,而今天,毫无疑问,武汉人——以及更多的人正在陪伴武汉度过它的关键时刻 !
项目功能设计:
- 定时爬取疫情数据存入Mysql
- 进行数据分析制作疫情报告
- 使用itchat给亲人朋友发送分析报告
- 基于Django做数据屏幕
- 使用Tableau做数据分析
来看看最终的效果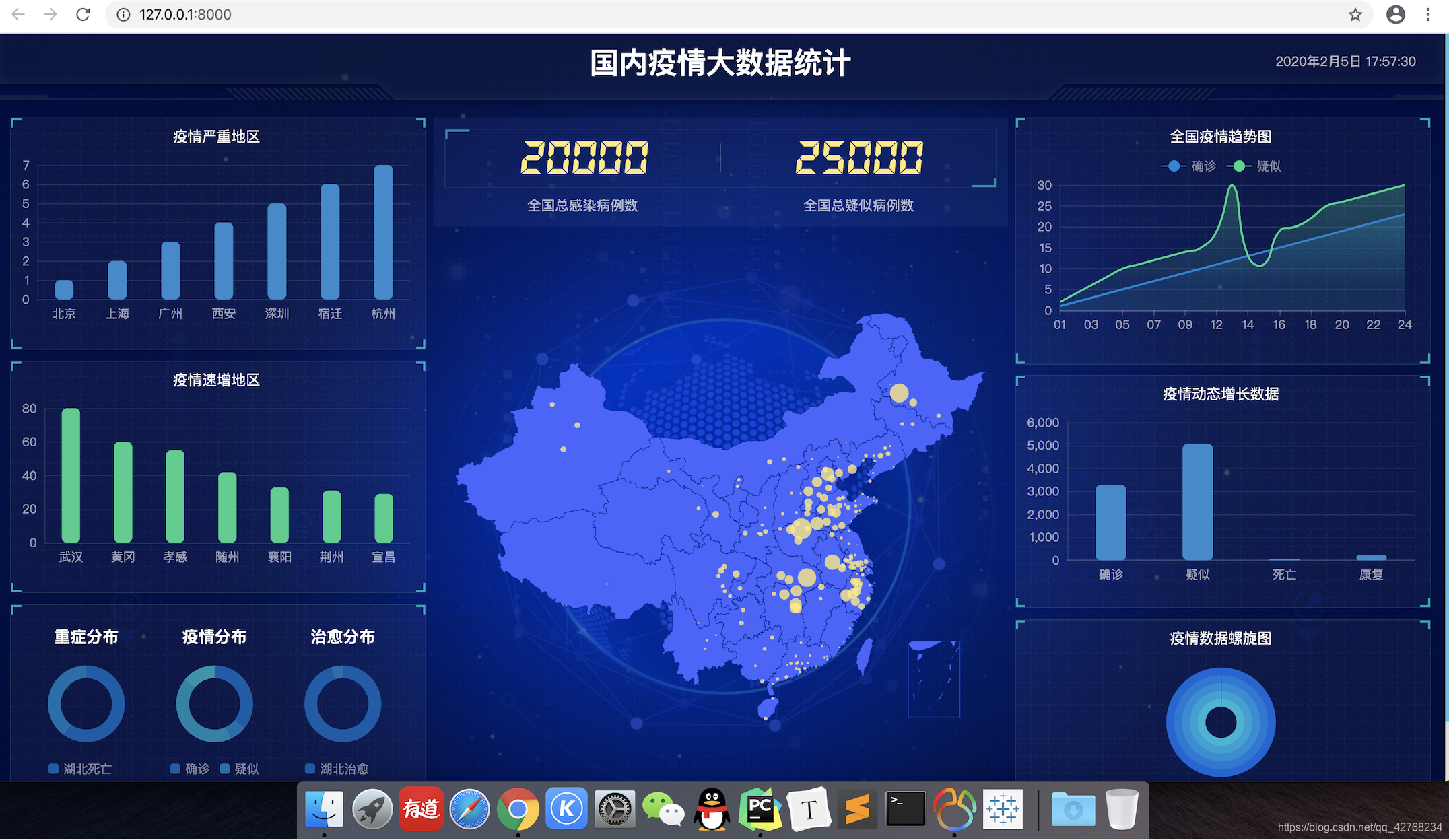
目前已经完成80% 完成后第一时间分享给大家
接下来我们来介绍爬取疫情数据
import re
import time
import json
import datetime
import requests
import pymysql
import pandas as pd
class VirusSupervise(object):
def __init__(self):
self.url = 'https://3g.dxy.cn/newh5/view/pneumonia?scene=2&clicktime=1579582238&enterid=1579582238&from=timeline&isappinstalled=0'
self.all_data = list()
self.host_ip = "127.0.0.1" # 你的mysql服务器地址
self.host_user = "root"
self.password = 123456 # 你的mysql密码
def request_page(self):
"""
请求页面数据
"""
res = requests.get(self.url)
res.encoding = 'utf - 8'
pat0 = re.compile('window.getAreaStat = ([\s\S]*?)</script>')
data_list = pat0.findall(res.text)
data = data_list[0].replace('}catch(e){}', '')
data = eval(data)
return data
def deep_spider(self, data, province_name):
"""
深度提取出标签里详细的数据
:param data:
:param province_name:
:return:
"""
for temp_data in data:
self.all_data.append([temp_data["cityName"], temp_data["confirmedCount"], temp_data["curedCount"],
temp_data["deadCount"], province_name, datetime.date.today(),
datetime.datetime.now().strftime('%H:%M:%S')])
def filtration_data(self):
"""
过滤数据
"""
temp_data = self.request_page()
province_short_names, confirmed_counts, cured_counts, dead_counts = list(), list(), list(), list()
for i in temp_data:
province_short_names.append(i['provinceShortName']) # 省份
confirmed_counts.append(i['confirmedCount']) # 确诊
cured_counts.append(i['curedCount']) # 治愈
dead_counts.append(i['deadCount']) # 死亡
self.deep_spider(i['cities'], i["provinceShortName"]) # 深度解析数据添加到实例属性中
data_all = pd.DataFrame(self.all_data, columns=["城市", "确诊", "治愈", "死亡", "省份", "日期", "时间"])
# print(data_all[data_all["省份"] == "陕西"])
df = pd.DataFrame()
df['省份'] = province_short_names
df['确诊'] = confirmed_counts
df['治愈'] = cured_counts
df['死亡'] = dead_counts
print(df)
# data_all.to_csv("疫情数据_1.csv", encoding="utf_8_sig")
return data_all
def insert_wis_sql(self):
data = self.filtration_data()
coon = pymysql.connect(host=self.host_ip, user=self.host_user, password=self.password, database="epidemic_data",
charset="utf8")
number = int(pd.read_sql("select cycle from all_data order by id DESC limit 1", coon)["cycle"].to_list()[0]) + 1
print("正在向阿里云服务器插入数据: ", number)
cursor = coon.cursor() # 创建事务
sql = "insert into all_data(cityName, confirmedCount, curedCount, deadCount, province_name, " \
"date_info, detail_time, cycle) values(%s, %s, %s, %s, %s, %s, %s, %s)"
print("正在插入数据...")
for cityName, confirmedCount, curedCount, deadCount, province_name, date_info, detail_time in zip(data["城市"],
data["确诊"], data["治愈"], data["死亡"], data["省份"], data["日期"], data["时间"]):
cursor.execute(sql, (cityName, confirmedCount, curedCount, deadCount, province_name, date_info, detail_time, number))
coon.commit()
print("数据插入完成...")
cursor.close()
coon.close()
if __name__ == '__main__':
sup = VirusSupervise()
sup.insert_wis_sql()
如果没有mysql服务器直接运行 sup.filtration_data() 然后使用pandas直接to_csv即可完成数据收集, 如果想定时爬去,给程序加上循环睡眠
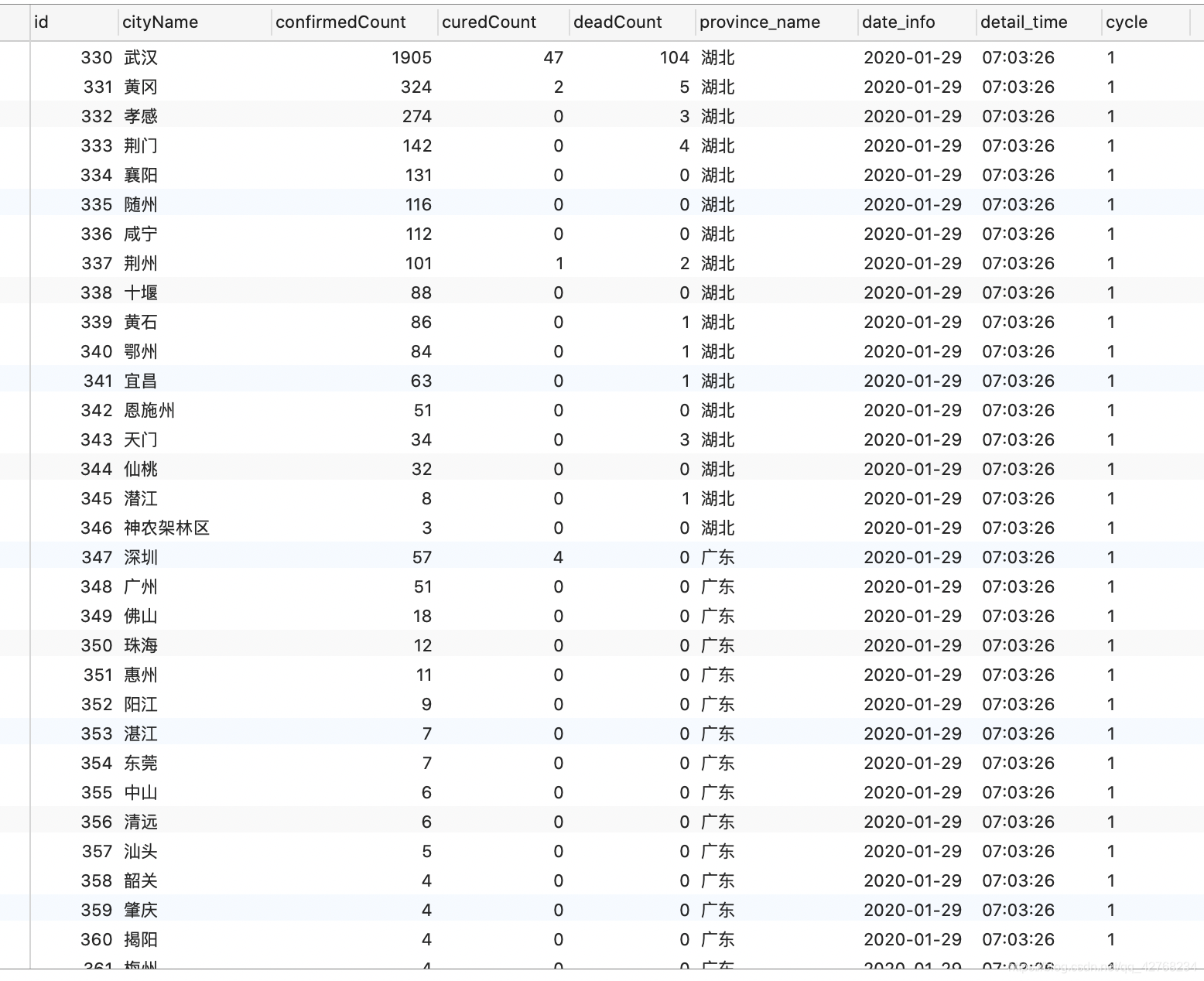
效果展示: