前言:
使用多进程爬虫方法爬取转转网二手市场商品信息,并将爬取的数据存储于MongoDB数据库中
本文为整理代码,梳理思路,验证代码有效性——2020.1.18
环境:
Python3(Anaconda3)
PyCharm
Chrome浏览器
主要模块: 后跟括号内的为在cmd窗口安装的指令
requests(pip install requests)
lxml(pip install lxml)
pymongo(pip install pymongo )
multiprocessing
步骤
转转网即58同城二手市场
1
首先爬取各类别的URL
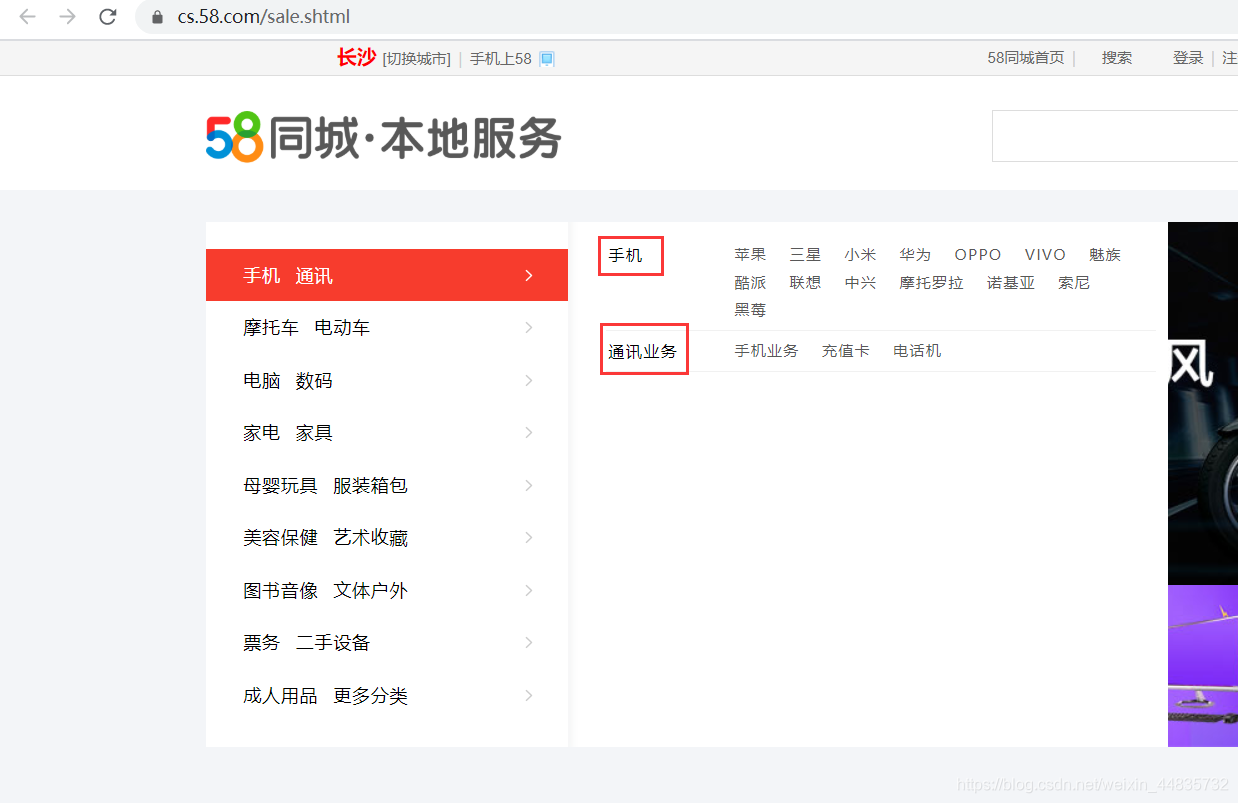
那么打开开发者工具F12,对网页结构进行分析

由截图即可判断,它们均有一个共同的外标签,这里用Xpath表达式为'//div[@class="lbsear"]/div/ul/li',我们在此基础上再进一步对网页进行解析,解析用Xpath表达式为'ul/li/b/a/@href',并将结果打印在控制台上作为channel_list,该步骤最终代码详见完整代码中的channel_extract.py。
2
通过上步得到的url进一步获取详情页的url
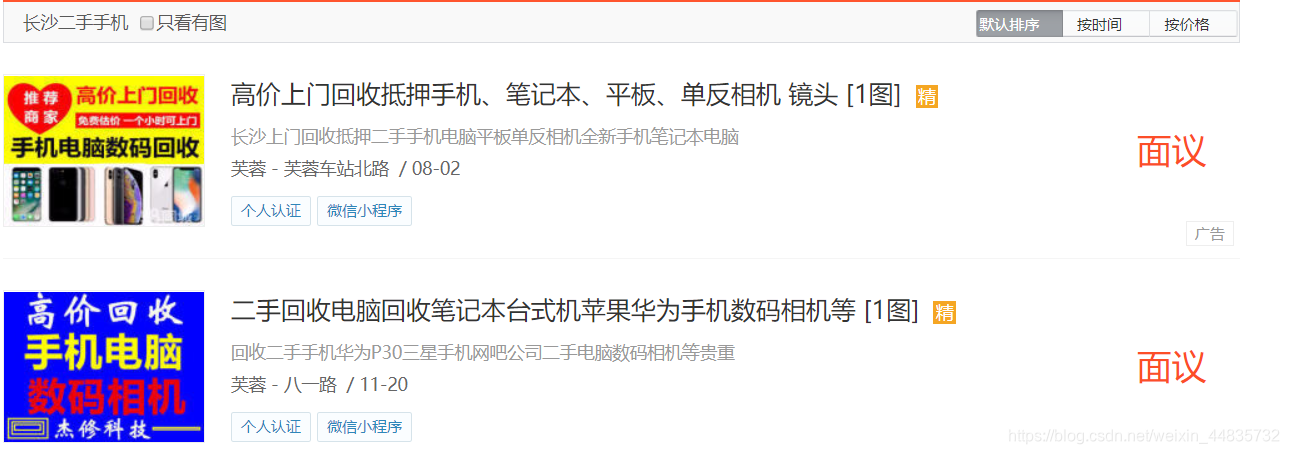
# 定义获取商品URL的函数
def get_links(channel, pages):
list_view = '{}pn{}/'.format(channel, str(pages))
try:
html = requests.get(list_view, headers=headers)
time.sleep(2)
selector = etree.HTML(html.text)
if selector.xpath('//tr'):
infos = selector.xpath('//tr')
for info in infos:
if info.xpath('td[2]/a/@href'):
url = info.xpath('td[2]/a/@href')[0]
print("url:", url)
tongcheng_url.insert_one({'url': url}) # 插入数据库
else:
pass
else:
pass
except requests.exceptions.ConnectionError:
pass # pass掉请求连接错误
3
点击跳转至详情页,并分析网页结构获取具体的信息(标题,价格,区域,浏览量)
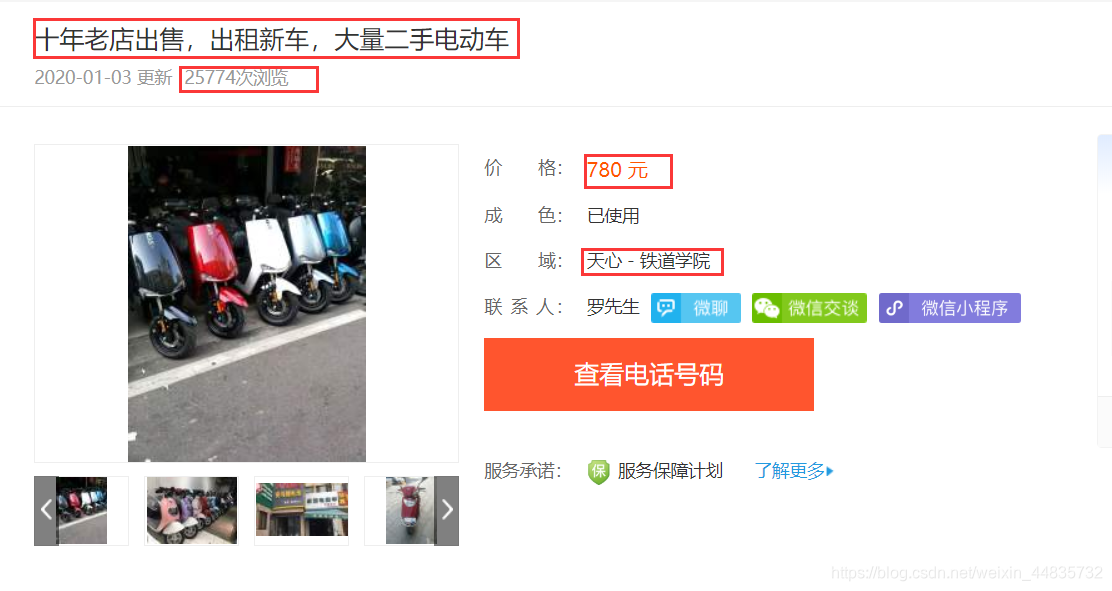
4
分第一部分和第二部分代码分别运行main.py文件,通过多线程方法将数据爬取下来并保存到MongoDB数据库中。
5
注意:
在后期运行过程中出现了一些问题,具体原因及处理方法如下:
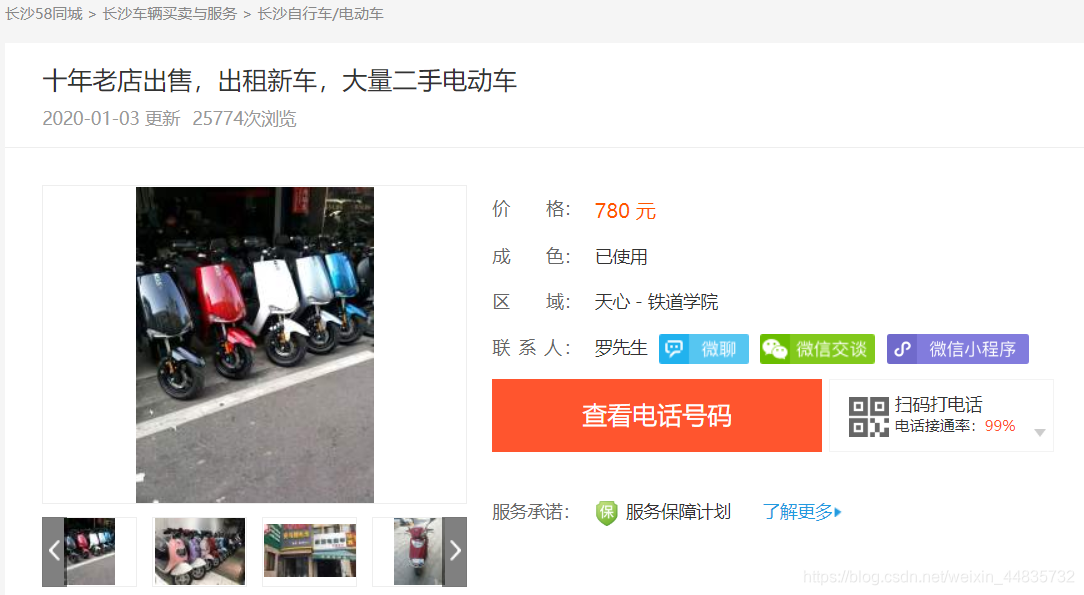
图一为其他正常详情页,图二为手机的详情页,而图二中没有对应的我们所需求的信息,所以在第一步获得的channel_list手动剔除手机相关的url,另做处理。
完整代码
1.channel_extract.py
# 导入库文件
import requests
from lxml import etree
start_url = 'http://cs.58.com/sale.shtml' # 请求URL
url_host = 'http://cs.58.com' # 拼接的部分URL
# 获取商品类目URL
def get_channel_urls(url):
html = requests.get(url)
selector = etree.HTML(html.text)
infos = selector.xpath('//div[@class="lbsear"]/div/ul/li')
for info in infos:
class_urls = info.xpath('ul/li/b/a/@href')
for class_url in class_urls:
# 打印类目urls
print(url_host + class_url)
# get_channel_urls(start_url)
# 运行上行代码 得到 channel_list
channel_list = '''
http://cs.58.com/shouji/
http://cs.58.com/tongxunyw/
http://cs.58.com/danche/
http://cs.58.com/diandongche/
http://cs.58.com/fzixingche/
http://cs.58.com/sanlunche/
http://cs.58.com/peijianzhuangbei/
http://cs.58.com/diannao/
http://cs.58.com/bijiben/
http://cs.58.com/pbdn/
http://cs.58.com/diannaopeijian/
http://cs.58.com/zhoubianshebei/
http://cs.58.com/shuma/
http://cs.58.com/shumaxiangji/
http://cs.58.com/mpsanmpsi/
http://cs.58.com/youxiji/
http://cs.58.com/ershoukongtiao/
http://cs.58.com/dianshiji/
http://cs.58.com/xiyiji/
http://cs.58.com/bingxiang/
http://cs.58.com/jiadian/
http://cs.58.com/binggui/
http://cs.58.com/chuang/
http://cs.58.com/ershoujiaju/
http://cs.58.com/yingyou/
http://cs.58.com/yingeryongpin/
http://cs.58.com/muyingweiyang/
http://cs.58.com/muyingtongchuang/
http://cs.58.com/yunfuyongpin/
http://cs.58.com/fushi/
http://cs.58.com/nanzhuang/
http://cs.58.com/fsxiemao/
http://cs.58.com/xiangbao/
http://cs.58.com/meirong/
http://cs.58.com/yishu/
http://cs.58.com/shufahuihua/
http://cs.58.com/zhubaoshipin/
http://cs.58.com/yuqi/
http://cs.58.com/tushu/
http://cs.58.com/tushubook/
http://cs.58.com/wenti/
http://cs.58.com/yundongfushi/
http://cs.58.com/jianshenqixie/
http://cs.58.com/huju/
http://cs.58.com/qiulei/
http://cs.58.com/yueqi/
http://cs.58.com/kaquan/
http://cs.58.com/bangongshebei/
http://cs.58.com/diannaohaocai/
http://cs.58.com/bangongjiaju/
http://cs.58.com/ershoushebei/
http://cs.58.com/chengren/
http://cs.58.com/nvyongpin/
http://cs.58.com/qinglvqingqu/
http://cs.58.com/qingquneiyi/
http://cs.58.com/chengren/
http://cs.58.com/xiaoyuan/
http://cs.58.com/ershouqiugou/
http://cs.58.com/tiaozao/
http://cs.58.com/tiaozao/
http://cs.58.com/tiaozao/
'''
2.page_spider.py
# 导入库
import requests
from lxml import etree
import time
import pymongo
# 连接数据库
client = pymongo.MongoClient('localhost', 27017)
# 创建数据库和数据集合
mydb = client['mydb']
tongcheng_url = mydb['tongcheng_url']
tongcheng_info = mydb['tongcheng_info']
# 加入请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36(KHTML, '
'like Gecko) Chrome/55.0.2883.87 Safari/537.36',
'Connection': 'keep-alive'
}
# 定义获取商品URL的函数
def get_links(channel, pages):
list_view = '{}pn{}/'.format(channel, str(pages))
try:
html = requests.get(list_view, headers=headers)
time.sleep(2)
selector = etree.HTML(html.text)
if selector.xpath('//tr'):
infos = selector.xpath('//tr')
for info in infos:
if info.xpath('td[2]/a/@href'):
url = info.xpath('td[2]/a/@href')[0]
print("url:", url)
tongcheng_url.insert_one({'url': url}) # 插入数据库
else:
pass
else:
pass
except requests.exceptions.ConnectionError:
pass # pass掉请求连接错误
# 定义商品详细信息的函数
def get_info(url):
html = requests.get(url, headers=headers)
selector = etree.HTML(html.text)
print(url, html.status_code)
try:
# 标题
title = selector.xpath('//*[@id="basicinfo"]/div[1]/h1/text()')[0]
# 价格
if selector.xpath('//*[@id="basicinfo"]/div[3]/div[1]/div[2]/span/text()'):
price = selector.xpath('//*[@id="basicinfo"]/div[3]/div[1]/div[2]/span/text()')[0]
else:
price = "无"
# 区域
if selector.xpath('//*[@id="basicinfo"]/div[3]/div[3]/div[2]/a[1]/text()'):
area = selector.xpath('//*[@id="basicinfo"]/div[3]/div[3]/div[2]/a[1]/text()')[0]
else:
area = "无"
# 浏览量
view = selector.xpath('//*[@id="totalcount"]/text()')[0]
info = {
'tittle': title,
'price': price,
'area': area,
'view': view,
'url': url
}
print(info)
tongcheng_info.insert_one(info) # 插入数据库
except IndexError:
pass # pass掉IndexError:错误
3.main.py
# 第一部分,爬取url地址
# import sys
# sys.path.append("..")
#
# from multiprocessing import Pool
# from channel_extract import channel_list
# from page_spider import get_links # 导入库文件和同一文件下的程序
#
#
# def get_all_links_from(channel):
# for num in range(1,101):
# get_links(channel, num) # 构造urls
#
#
# if __name__ == '__main__': # 程序主入口
# pool = Pool(processes=4) # 创建进程池
# pool.map(get_all_links_from, channel_list.split()) # 调用进程池爬虫
# 第二部分,爬取信息
import sys
sys.path.append("..")
from multiprocessing import Pool
from page_spider import get_info
from page_spider import tongcheng_url
from page_spider import tongcheng_info
db_urls = [item['url'] for item in tongcheng_url.find()]
db_infos = [item['url'] for item in tongcheng_info.find()]
x = set(db_urls)
y = set(db_infos)
rest_urls = x - y
if __name__ == '__main__':
pool = Pool(processes=4)
pool.map(get_info, rest_urls)
