爬虫流程
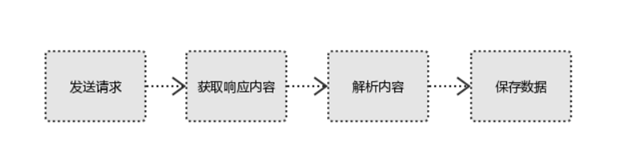
- 发起请求,通过使用HTTP库向目标站点发起请求,即发送一个Request,请求可以包含额外的headers等信息,并等待服务器响应。
- 获取响应内容如果服务器能正常响应,则会得到一个Response,Response的内容就是所要获取的页面内容,其中会包含:html,json,图片,视频等。
- 解析内容得到的内容可能是html数据,可以使用正则表达式、第三方解析库如Beautifulsoup,etree等,要解析json数据可以使用json模块,二进制数据,可以保存或者进一步的处理。
- 保存数据保存的方式比较多元,可以存入数据库也可以使用文件的方式进行保存。
xpath表达式
在 XPath 中,有七种类型的节点:元素、属性、文本、命名空间、处理指令、注释以及文档节点(或称为根节点)。
选取节点:
XPath 使用路径表达式在 XML 文档中选取节点。节点是通过沿着路径或者 step 来选的。路径表达式:
| 表达式 | 描述 |
| nodename | 选取此节点的所有子节点。 |
| / | 从根节点选取。 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 |
| . | 选取当前节点。 |
| .. | 选取当前节点的父节点。 |
| @ | 选取属性。 |
谓语(Predicates)
放在方括号[]中,相当于筛选条件,用来查找[]中指定的特定节点或者包含某个指定的值的节点。一些带有谓语的路径表达式和结果:
| 路径表达式 | 结果 |
| /bookstore/book[1] | 选取属于 bookstore 子元素的第一个 book 元素。 |
| /bookstore/book[last()] | 选取属于 bookstore 子元素的最后一个 book 元素。 |
| /bookstore/book[last()-1] | 选取属于 bookstore 子元素的倒数第二个 book 元素。 |
| /bookstore/book[position()<3] | 选取最前面的两个属于 bookstore 元素的子元素的 book 元素。 |
| //title[@lang] | 选取所有拥有名为 lang 的属性的 title 元素。 |
| //title[@lang='eng'] | 选取所有 title 元素,且这些元素拥有值为 eng 的 lang 属性。 |
| /bookstore/book[price>35.00] | 选取 bookstore 元素的所有 book 元素,且其中的 price 元素的值须大于 35.00。 |
| /bookstore/book[price>35.00]/title | 选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00。 |
选取未知节点
XPath 通配符可用来选取未知的 XML 元素。
| 通配符 | 描述 |
| * | 匹配任何元素节点。 |
| @* | 匹配任何属性节点。 |
| node() | 匹配任何类型的节点。 |
例子:
| 路径表达式 | 结果 |
| /bookstore/* | 选取 bookstore 元素的所有子元素。 |
| //* | 选取文档中的所有元素。 |
| //title[@*] | 选取所有带有属性的 title 元素 |
选取若干路径
在路径表达式中使用“|”运算符可以选取若干个路径。
| 路径表达式 | 结果 |
| //book/title | //book/price | 选取 book 元素的所有 title 和 price 元素。 |
| //title | //price | 选取文档中的所有 title 和 price 元素。 |
| /bookstore/book/title | //price | 选取属于 bookstore 元素的 book 元素的所有 title 元素,以及文档中所有的 price 元素。 |
其它例子
//*[@category='cooking']:属性为cooking的元素
//*[@category='web' and @cover='paperback'] :属性为web的有两个,可以用and加限定条件继续匹配
//*[@category='web' or @cover='paperback']
//*[not(@category='web')]

//book[@*]:所有有属性的book节点
//*[@*]:所有有属性的元素
/bookstore//price:绝对和相对的结合,找到所有的price
//@cover:相对查找属性cover
/bookstore/book[1]/*:第一个book下的全部内容
/bookstore/book[1]/title[@*]:第一个book的title属性
/bookstore//price[text()>30]或者/bookstore//price[.>30]:所有price大于30的元素亲属关系匹配
//book[1]/year[.=2005] 或者//book[1]/year[.=2005]/following-sibling::*:找到year节点的下一级price
//book[1]/year[.=2005]/following-sibling::*:找到year节点的上一级(有两个,可以限定一下)
//book[1]/year[.=2005]/preceding-sibling::title
//book[1]/year[.=2005]/parent::*:找到父级元素
基于最后一个book找到上一个book的year节点:
基于属性cover再找到下一book的最后一个author
//*[text()='Per Bothner']/parent::*:基于文本Per Bothner找到父元素
//author[contains(.,'Vaidy')]:文本中包含'Vaidy'的元素,前面的点代表的是文本,也可是写text()
实战:爬取链家二手房源信息
import requests
from lxml import etree
import pandas as pd
import datetime
t1=datetime.datetime.now()
#参数设置
headers={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36'}#请求头,模拟浏览器进行请求
page_num=2#爬取页数
url='https://bj.lianjia.com/ershoufang/'#要爬取的网址
#开始爬取
title,content,price,link=[],[],[],[]
for i in range(page_num):
print('第{}页爬取中......'.format(i+1))
response=requests.get(url,headers=headers)#向一级网页发送请求
if response.status_code==200:
response.encoding=response.apparent_encoding#字符编码设置为网页本来所属编码
html=response.text#获取网页代码
html_etree = etree.HTML(html)#将网页文本代码转为etree对象
#解析提取数据
title+=html_etree.xpath('//div[@class="title"]/a/text()')#提取标题
content+=html_etree.xpath('//div[@class="houseInfo"]/text()')#提取房源信息
price+=html_etree.xpath('//div[@class="totalPrice"]/span/text()') #提取价格
link+=html_etree.xpath('//div[@class="title"]/a/@href')#提取链接
else:
print('第{}页请求失败!'.format(i+1))
#数据存储
data=pd.DataFrame(zip(title,content,price,link),columns=['标题','房源信息','价格','链接'])
data.to_excel('链接二手房源信息爬取结果.xlsx')
t2=datetime.datetime.now()
print('finish,total spend ts:{}'.format(t2-t1))PS:有爬虫需求可加Q联系:947943645
