文章标题:https://www.aclweb.org/anthology/P16-1154.pdf
文章题目:Incorporating Copying Mechanism in Sequence-to-Sequence Learning(将复制机制整合到序列到序列的学习中)ACL2016
写在前面:这篇文章基于Seq2Seq网络提出了“复制机制”,主要针对文本摘要任务,但是在实体-关系联合抽取任务中,对于实体重叠问题,可以采取此方法来对重叠的实体进行复制,此方法对于解决实体-关系联合抽取任务中的实体重叠问题提供了信思路。
Abstract
我们解决了一个重要的问题,在序列到序列(Seq2Seq)学习中被称为复制,其中输入序列中的某些片段被选择性地复制到输出序列中。在人类语言交际中也存在类似的现象。例如,人类倾向于在谈话中重复实体名称甚至是长短语。Seq2Seq中关于复制的挑战是需要新的机器来决定何时执行操作。在本文中,我们将复制引入基于神经网络的Seq2Seq学习中,提出了一种新的具有编码器和解码器结构的COPYNET模型。COPYNET可以很好地将解码器中常规的单词生成方式与新的复制机制集成在一起,这种复制机制可以选择输入序列中的子序列,并将它们放在输出序列中的适当位置。我们对合成数据集和真实世界数据集的实证研究证明了COPYNET的有效性。例如,在文本摘要任务上,COPYNET可以比基于RNN的常规模型有显著的优势。
一、Introduction
最近,基于神经网络的序列到序列学习(Seq2Seq)在各种自然语言处理(NLP)任务中取得了显著的成功,包括但不限于机器翻译(Cho等,2014;Bahdanau et al., 2014),句法分析(Vinyals et al., 2015),文本摘要(Rush et al., 2015)和对话系统(Vinyals and Le, 2015)。Seq2Seq本质上是一个编码器-解码器模型,在这个模型中,编码器首先将输入序列转换为特定的表示,然后再将该表示转换为输出序列。在Seq2Seq中加入注意力机制(Bahdanau et al., 2014),这是机器翻译中首次提出的自动对齐机制,它显著提高了各种任务的性能(Shang et al., 2015;Rush等人,2015)。与规范的encoder-decoder架构不同,基于注意力的Seq2Seq模型以其原始形式(单词表示的数组)对输入序列进行了修正,并动态地获取相关的信息片段,而这些信息大部分是基于输出序列生成的反馈。
在这篇论文中,我们探讨了另一种对人类语言交流很重要的机制,称为 “复制机制”。基本上,它指的是定位输入语句的某个片段并将该片段放入输出序列的机制。例如,在下面的两个对话中,我们观察到不同的模式,其中响应®中的一些子序列(蓝色)是从输入语句(I)中复制出来的:

规范的编码器-解码器及其具有注意机制的变体都严重依赖于“意义”的表示,如果系统需要引用输入的子序列(如实体名称或日期)时,那么这种表示可能不够准确。与此相反,复制机制更接近于人类语言处理中的死记硬背,因此在基于神经网络的模型中需要不同的建模策略。我们认为,拥有一个优雅的统一模型可以同时适应理解和死记硬背,这对许多Seq2Seq任务都有好处。为了实现这一目标,我们提出了COPYNET,它不仅能够正常生成单词,而且能够复制输入序列的适当片段。尽管复制的操作看起来很“困难”,但CopyNet可以以一种端到端的方式进行训练。我们对合成数据集和真实数据集的实证研究证明了COPYNET的有效性。
二、Background: Neural Models for Sequence-to-sequence Learning
Seq2Seq学习可以用概率的观点来表示,即最大化观察给定输入(源)序列的输出(目标)序列的可能性(或其他一些评价指标(Shen et al., 2015))。
2.1 RNN Encoder-Decoder
略
2.2 The Attention Mechanism
略
三、COPYNET
从认知的角度来看,复制机制与死记硬背有关,需要较少的理解,但保证了较高的文字保真度。从建模的角度来看,复制操作更加严格和符号化,这使得它比软注意机制更难集成到一个完全可微分的神经模型中。在本节中,我们提出了具有“复制机制”的可微Seq2Seq模型COPYNET,它可以通过梯度下降的方式进行端到端的训练。

图一:COPYNET的总体图表。为了简单起见,我们省略了一些用于预测的链接(更多细节请参见3.2节)。
3.1 Model Overview
如图1所示,COPYNET仍然是一个编码器-解码器(在稍微广义的意义上)。编码器将源序列转换为表示,然后解码器读取该表示法以生成目标序列。
(1)Encoder
与(Bahdanau et al., 2014)中的编码器相同,使用双向RNN将源序列转换成一系列长度相等的隐藏状态,每个隐藏状态ht对应于词xt。这个新的表示源,{h1,…,hTS}被认为是一种短期记忆(在本文其余部分称为M),以后将以多种方式访问它以生成目标序列(解码)。
(2)Decoder
一个读取M并预测目标序列的RNN。它与规范的RNN-解码器(Bahdanau et al., 2014)相似,但有以下重要区别:
- Prediction:COPYNET基于两种模式:即生成模式(generate-mode)和复制模式(copy-mode),后者从源序列中选择单词)的混合概率模型预测单词(见3.2节):
- State Update:t−1时预测的单词用于更新t时的状态,而COPYNET不仅使用其嵌入的单词,还使用其在M中对应的特定位置的隐藏状态(如果有的话)(更多信息参见第3.3节);
- Reading M:除了专注地读到M之外,COPYNET也有“选择性读”到M,这导致了基于内容的寻址和基于位置的寻址的强大混合(更多讨论请参见3.3和3.4节)。
3.2 Prediction with Copying and Generation(通过复制和生成进行预测)
我们假设一个词汇 V = {v1,…,Vn},对于任何非词汇表(OOV)单词使用UNK。此外,我们还有另一组单词X,对于源序列 X = {x1,…,xt} 中的所有独特的单词。由于X可能包含不在V中的单词,所以在X中复制子序列可以使COPYNET输出一些OOV单词。简而言之,源X的实例特定词汇表是V ∪ UNK ∪ X。
给定译码器在t时刻的RNN状态st和M,任何目标字yt的生成概率由概率的“混合”给出如下:
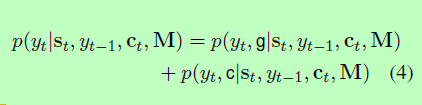
其中g表示生成模式,c表示复制模式。分别给出了两种模态的概率:

其中g(·)和c(·)分别为产生模式和复制模式的评分函数,Z为两种模式共有的归一化项。由于共享归一化术语,这两种模式基本上是通过一个softmax函数进行竞争(参见图1中的示例说明),使得公式4不同于混合模型的规范定义(McLachlan和Basford, 1988)。这在图2中也有图示。计算每个模式的分数:

图二:说明解码概率p(yt|·)是一个4类分类器。
(1)Generate-Mode
使用与一般RNN编解码器相同的评分功能(Bahdanau et al., 2014),即:
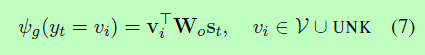
(2)Copy-Mode
“复制”单词xj的分数计算为:
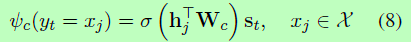
根据经验,我们也发现使用tanh非线性比线性变换更有效,我们在接下来的实验中使用它。在计算复制模式分数时,我们使用隐藏状态{h1,…,hTS}来“表示”源序列{x1,…,xTS},因为双向RNN不仅将内容编码,还将位置信息编码到M的隐藏状态。位置信息对于复制非常重要(相关讨论见3.4节)。注意,我们将等式(6)中所有xj=yt的概率相加,考虑到译码yt可能有多个源符号。当yt不出现在源序列时,令p(yt, c|·)= 0;当yt只出现在源序列时,令p(yt, g|·)= 0。
3.3 State Update(状态更新)
对于基于一般注意的Seq2Seq模型,COPYNET使用前面的状态st−1、前面的符号yt−1和公式2后面的上下文向量ct更新每个解码状态st。
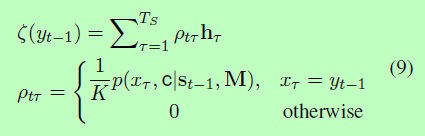
实际上,ptπ 通常集中在多个外观中的一个位置,这表明预测与单词的位置密切相关。
正如将在3.4节中讨论的那样,这种特殊的设计可能有助于复制模式覆盖连续的单词子序列。
3.4 Hybrid Addressing of M(对M的混合寻址)
我们假设COPYNET使用混合策略来获取M中的内容,它结合了基于内容和基于位置的寻址。这两种寻址策略由解码器RNN协调,以管理细心读和选择性读,以及决定何时进入/退出复制模式。
一个经过适当训练的编码器RNN将一个单词的语义和它在X中的位置编码成M中的隐藏状态。从我们的实验中可以看出,COPYNET的细心阅读更多的是受语义和语言模型的驱动,因此能够更自由地在M上移动,甚至可以跨越很长的距离。另一方面,一旦COPYNET进入copy-mode,M的选择性读取通常由位置信息引导。因此,选择性阅读往往采取僵硬的行动,往往涵盖连续的单词,包括UNKs。与神经图灵机器中混合寻址的显式设计不同(Graves等,2014;(Kurach et al., 2015), COPYNET更微妙:它提供了架构,可以促进一些特定的基于位置的寻址,并让模型从特定任务的训练数据中找出细节。
(1)Location-based Addressing(基于位置的处理)
(2)Handling Out-of-Vocabulary Words(处理词汇表之外的词汇)
四、Learning
虽然复制机制使用**“硬”操作**从源复制,并选择粘贴它们或从词汇表生成符号,但COPYNET是完全可区分的,可以使用反向传播以端到端的方式进行优化。给定源序列和目标序列{X}N和{Y}N的批次,目标是最小化负对数似然:
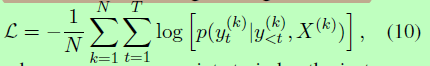
我们使用上标来索引实例。由于观察任何目标单词的概率模型是生成模式和复制模式的混合,因此不需要为模式添加任何额外的标签,网络可以从数据中学习协调两种模式。更具体地说,如果在源序列中找到一个特定的单词y(k)t,那么复制模式将有助于混合模型,而梯度将或多或少地鼓励复制模式;否则,由于共享归一化项z的竞争,不鼓励复制模式。在实践中,大多数情况下是一种模式占主导地位。
五、Experiments
我们报告了我们的实证研究的COPYNET在以下三个不同的特点的任务:
- 一个具有简单模式的合成数据集;
- 一个现实世界的文本摘要任务;
- 用于简单单轮对话的数据集;
六、Related Work
我们的工作部分受到Pointer Networks(Vinyals et al., 2015a)的启发,其中使用指针机制(与提议的复制机制非常相似)直接从输入预测输出序列。除了在应用上与我们的不同,(Vinyals et al., 2015a)不能预测输入序列集合之外,而COPYNET可以自然地将生成和复制结合起来。
COPYNET还与解决神经机器翻译中的OOV问题有关。Luong等人(2015)提出了一种使用源句注释对翻译后的句子进行后处理的启发式方法。相比之下,COPYNET通过端到端模型以更系统的方式解决了OOV问题。但是,由于COPYNET将确切的源单词复制为输出,因此它不能直接应用于机器翻译。然而,这种复制机制可以自然地扩展到除输入序列之外的任何类型的引用,这将有助于具有异构源和目标序列(如机器翻译)的应用程序。
(注:OOV问题指代Out of Vocabulary)
复制机制也可以看作是在没有任何非线性转换的情况下将信息传送到下一阶段。(Srivastava et al., 2015; He et al., 2015)的分类任务,其中的捷径是建立在层之间的直接携带信息。
最近,我们注意到一些类似于或与复制相关的建模机制的并行工作。Cheng和Lapata(2016)设计了一种能够从源中提取单词/句子的神经摘要模型。Gulcehre等人(2016)提出了一种指向方法来处理OOV单词进行总结和MT。相比之下,COPYNET更通用,不局限于特定的任务或OOV单词。此外,softmaxCOPYNET在处理两种模式混合的相关工作中比门控更灵活,因为它能够充分地对复制段的内容建模。
七、Conclusion and Future Work
我们建议使用COPYNET将复制合并到序列到序列的学习框架中。在以后的工作中,我们将把这一思想扩展到源和目标是异构类型的任务,例如,机器翻译。
