《Incorporating Copying Mechanism in Sequence-to-Sequence Learning》
引言
最近看了一下CopyNet,感觉此网络也是比较玄学,它能够自动的,决定下一步的预测是生成模式还是复制模式。生成模式就是我们常说的注意力机制,复制模式就是这篇文章的一个创新点。
他的想法是来源于,人类在阅读文章的时候,或者去做一些摘要的时候,除了自己会生成一些概括语句之外,还会从文章当中去摘抄一些核心句子。也就是说,理解生成和死记硬背。
1、Motivation
- 注意力机制当中,都是根据语义表达生成词语,而且都是词汇表当中的词语。一个问题就是他没有办法去处理out of vocabulary。而在某些系统当中,需要的是输入的一些子串,比如说像一些实体名词等。如下图:

- 于是提出copy机制,他需要更少的理解,但是能够确保文字的保真度。对于摘要,对话系统等来说,能够提高文字的流畅度和准确率。并且也是端到端进行训练。
2、Model

Copy net is still an encoder and decoder framework,以单轮对话为例。输入是句子A以及位置信息,经过Encoder,由Decoder得到输出——句子B。
2.1 Encoder
源端的表达就是一个Encoder,被认为是一个short term memory,在论文后部分用M表示。
2.2 Decoder
和传统的解码器一样,根据M预测目标序列,主要有以下几个不同点:
- 预测:两个模式的混合概率模型,一个是生成模式,一个是复制模式(见2.2.1),即在源端选出一些子串。
- 状态更新:更新t时刻的状态会用到前一时刻预测的词。但是copy network,不仅仅使用它的词向量,而且还使用它对应的位置信息。(见2.2.2)
- Reading M:除了对M做一个attentive read,还会对他做一个selective read,混合了基于内容和基于位置的处理。
2.2.1 生成模式&复制模式
假定有一个词表
,使用UNK表示OOV。源端句子
,X中可能包含V中没有的词,这样用copy mode就能够复制词表中没有的词。给定解码端隐藏状态s,以及M,目标词的概率由以下混合概率模型定义: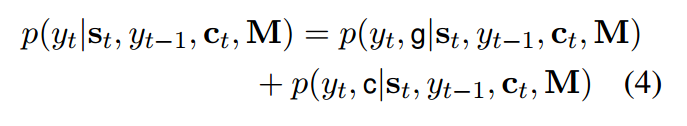
两种模式的概率是:

总共需要考虑4个情况,目标词yt如果属于词汇表或者源端,就分别计算上述两个概率;如果既不属于词汇表,也不属于源端,就是UNK;如果属于源端,但不属于词汇表,那么生成的概率为0;如果不属于源端,那么复制的概率为0。Z是两种模式共享的归一化项。下图可见:
这个地方我的理解,应该是在训练当中yt作为目标词,整个模型的目标是要让yt的混合概率最大。即-log似然概率最小。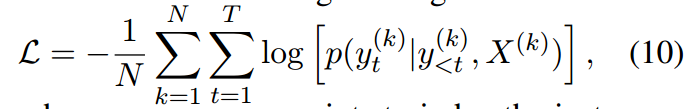
然后在预测的时候,因为没有目标词。按照作者给的模型框架图,应该是在最后一层前馈神经网,维度为词汇表的数量加源端句子的长度。然后把每一个词对应的概率加起来选择最大概率的词作为prediction。(这个词如果没有出现在源端,则复制模式概率为零。这个词如果出现在了源端,但是不在目标词里,生成模式概率为0。)(如有错误欢迎指正)
下图是两种模式分数的计算方法:

2.2.2 State Update
注意力机制中,状态的更新为下公式:
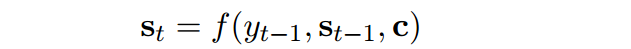
但是在copy net,
有一点小的变化,其被表达成以下形式:
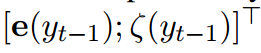
前者是一个embedding,后者是一个加权和的计算,对于源端中的词,如果其等于
,则以公式9进行计算,否则其概率为0。也就是说,我们挑选出等于
的词的隐层状态和词向量连接。
这里的操作称之为selective read,与attentive read相似。attentive read是用decoder的隐状态和encoder隐状态做attention,是soft操作;而selective read是用t-1时刻的输出与encoder的输入做selection,不相等则为0,是hard操作。
3、Experiment
第一个实验是自动文摘,因为文摘任务当中,可以发现摘要中的大部分,都是可以从原文当中直接复制过来的。在源端可能会出现很多的out of vocabulary,所以基于注意力的encoder decoder模型,生成的摘要效果很差。



第二个实验用在单轮对话系统,在单轮对话任务当中,虽然基于注意力的encoder decoder模型,能够去生成完整的有语义的句子,可是往往答非所问。


可见copy network,在这些任务上效果还是比较好的。
4、Discussion
优点:
- 加入copy机制,不仅仅考虑生成模式,还考虑复制模式,对文摘或者单轮对话任务起到比较好的效果。
缺点:
- Hard操作,将其他的全部置零是否稳妥?
- 多轮对话是否有用?
- 对于源端和目标端不同语言的任务,如何改进?
1.copy networks他复制的时候是直接把input复制过来(比如复旦 投毒案)两个词。就比如说他输出是复旦的时候,然后直接把输入中复旦后面那个词投毒案直接复制过来吗?
还是说他输出是复旦的时候,根据复旦这个词和复旦这个位置,然后经过计算解码端得到t时刻投毒案这个词啊?
(也就是说它的复制是直接从输入复制还是说也要经过计算的?如果是直接复制。那么复制到啥时候停止呢?不能一直把input复制到底吧?)
2.这个最后计算概率的时候,是把c和g的概率一起加起来做为最后的概率值,然后选择最大的一个词。那这里感觉对问题1的解释就应该是后者。
3.一开始我理解以为是copy算的概率大于generator的概率,就是进入复制模式,开始复制input。可是它最后的训练目标是混合概率最大化,那这样我3的理解就是错的,还是需要经过计算得到混合概率最大的作为输出?