信息最大化GAN:InfoGAN总结
InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets
InfoGAN(通用对抗网络的信息论扩展):完全以无监督的方式学习复杂纠缠的表示。同时,InfoGAN还可以最大化一小部分潜在变量和观测值之间的互信息
具体而言,InfoGAN成功地将书写样式从MNIST数据集上的数字形状中解脱出来,从3D渲染图像的光照中构成姿势,从SVHN数据集上的中心数字中解脱出背景数字。它还在CelebA脸部数据集上发现了视觉概念,包括发型,是否有眼镜以及情绪。
源码
InfoGAN in TensorFlow: link.
论文
论文:InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets
论文地址:link
概述
在本文中,提出了对生成对抗网络目标的简单修改,以鼓励其学习可解释和有意义的表示形式。
我们通过最大化GAN噪声的固定小子集与观测值之间的互信息来做到这一点,而事实证明这是相对简单的。尽管简单,但我们发现我们的方法出奇地有效:它能够在许多图像数据集上发现高度语义化和有意义的隐藏表示形式:数字(MNIST),面孔(CelebA)和门牌号(SVHN)。我们无监督实现纠缠表示的质量与以前使用监督的标签信息的工作相匹配。这些结果表明,生成模型并增加相互信息成本可能是学习解开表示的有效方法。
InfoGAN可以分解离散和连续的潜在因素,扩展到复杂的数据集,并且通常不需要比常规GAN多的训练时间。
回顾 GAN

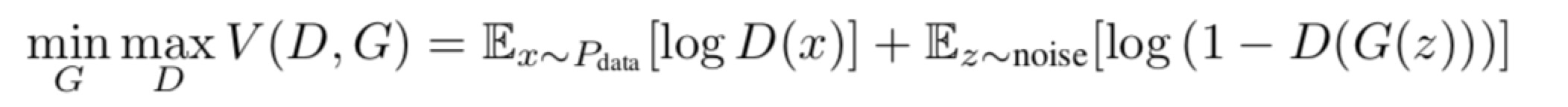
潜在代码的共同信息
GAN公式使用简单的因子连续输入噪声向量z,而不对生成器可能使用该噪声的方式施加限制。结果,生成器可能以高度纠缠的方式使用噪声,导致z的各个维度不对应于数据的语义特征。
然而,许多领域自然而然地分解成一组具有语义意义的变量因子。 例如,当从MNIST数据集生成图像时,如果模型自动选择分配一个离散随机变量来表示数字(0-9)的数字标识,选择两个数字代表具有的角度和数字笔画的厚度。在这种情况下,这些属性是独立的和显著的,如果我们可以通过简单地从独立的1到10变量和两个独立的连续性变量恢复MNIST数字,那么这些属性就是有用的。
在本文中,我们提出将输入噪声向量分成为两部分:
(i)z,被视为不可压缩噪声源;
(ii)c,我们将其称为潜在代码,其目的在于数据分布的显著结构化语义特征。
在数学上,我们用c1,c2,…,cL 来表示结构化隐藏变量集合。其最简单的方式,我们可以假设存在一个因素分布,可表示为

为了符号简化,我们将会隐藏代码c来表示所有的隐藏变量ci的级联。
我们现提出一种非监督方法来发现这些隐藏因素:我们向生成网络提供非压缩噪声z和隐藏代码c,因此生成网络的形式变为G(z, c)。然而,在标准GAN中,生成器是能够通过找到一种方法满足PG(x|c) = PG(x),以此来自由忽略附加隐藏代码c的。
为了解决琐碎代码的问题,我们提出一种信息-理论正则化:在隐藏代码c与生成器分布G(z, c).之间存在着很高的互信息。于是I(c;G(z, c))应该是高的。
在信息论中,X和Y之间的互信息I(X; Y ),用于测量从关于其他随机变量X的随机变量Y学习知识的“信息数量”。互信息可被表示为两个熵项的差异:

这个定义有个直观的解释:I(X; Y )是当Y被观测时,X的不确定性的下降。如果X和Y是独立的,于是I(X; Y ) = 0,因为知道一个变量对另一个并无意义;相比之下,如果X和Y与确定的,可逆的函数相关,最大的互信息便可以得到。
这种解释使得用公式表示损失变得容易:给定任意的x~PG(x),我们希望PG(c|x)有小的熵。换言之,隐藏代码c中的信息在生成过程中不应被丢失。相似的互信息促使目标在上下文聚集之前就被考虑。于是,我们打算解决如下信息-正则化最小最大游戏:
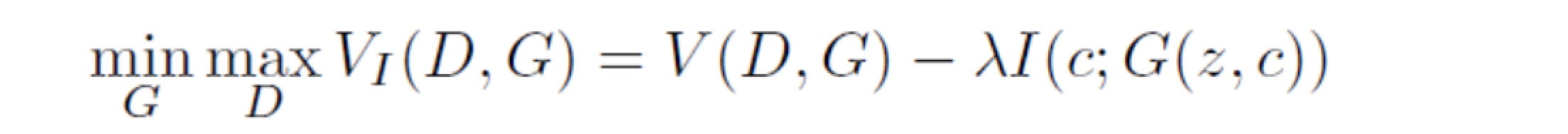
变异互信息最大化
实际上,互信息项I(c;G(z, c))是很难直接最大化的,因为其需要接近后验P(c|x)。幸运的是,通过定义一个辅助分布Q(c|x)以估计P(c|x),我们可以得到互信息项的一个下界:

下界互信息的技术被誉为变分信息最大化。我们另外注意到隐藏代码H( c)的熵也可以被优化,因为通常分布有一个简单的解析形式。然而,本文中我们通过固定隐藏代码分布以及将H( c)视为常量的方式进行简化。迄今为止,我们已经通过该下界绕过了显式计算后验P(c|x)的问题,但是我们仍然需要能够从内部期望的后验中取样。接下来我们陈述一个简单的引理,其消除了从后验取样的需要,它的证明推迟至附录。
引理5.1 对于任意变量X,Y以及函数f(x, y),在合适正则化的条件下:
通过使用引理A.1,我们可以定义一个变分下界,LI (G,Q),互信息,I(c;G(z, c)):
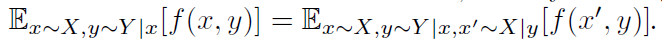
我们注意到LI (G,Q)很容易用蒙特卡罗模拟法近似。特别地,通过重新参数化的方法,LI可被最大化直接w.r.t.Q和w.r.t.G。因此,在不改变GAN的训练程序情况下,LI (G,Q)可被添加至GAN的目标,我们将所得算法称作信息最大化生成对抗网络(InfoGAN)。
等式(4)表示了当辅助分布Q接近真实后验分布:
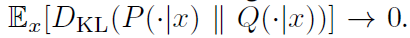
下变得紧凑。此外,我们知道当变分下界对于离散隐藏代码获得其最大值LI (G,Q) = H( c)时,边界变得紧凑,可得到最大化互信息。在附录,我们记录了InfoGAN如何连接至Wake-Sleep算法以提供另一种解释。
因此,InfoGAN被定义为如下带有变分互信息正则化和超参数λ的最小最大化游戏:
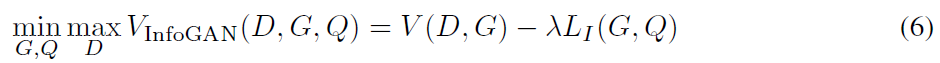
实际上,我们将辅助分布Q参数化为一个神经网络。在大多数实验室中,Q和D分享所有的卷积层,而且对于条件分布Q(c|x),还存在一个最后全连接层以输出参数,这意味着InfoGAN仅向GAN添加一个可忽略的计算成本。我们还发现LI (G,Q)收敛的速度比常规GAN要快,因此可以看成infoGAN是由GAN免费提供的。
对于分类潜在代码ci,我们使用非线性softmax的自然选择来表示Q(ci | x)。对于连续潜在代码cj,根据真正的后验概率P(cj | x),有更多的选项。在我们的实验中 ,我们发现简单地将Q(cj | x)作为高斯因子来处理就足够了。
即使InfoGAN引入了一个额外的超参数λ,对于离散的潜在代码,它很容易调整,简单地设置为1就足以。当隐藏代码包含连续变量时,较小的λ通常用于确保LI(G,Q)的微分熵与GAN目标的规模相同。
由于GAN以难以训练而著称,我们基于DC-GAN介绍的现有技术设计实验,这些技术足以稳定InfoGAN训练,而且我们不必引入新的技巧。详细的实验设置见附录。
实验
Mutual Information Maximization
为了评估潜在代码c和生成的图像G(z, c)之间的互信息是否可以通过提出的方法有效地最大化,我们在MNIST数据集上训练InfoGAN,对潜在代码c进行统一的分类分布c~Cat(K = 10,p = 0.1)。在图1中,下限LI (G,Q)快速最大化为H© ≈ 2.30,这意味着边界紧凑,最大化互信息已得到。

作为基准,当没有明确促使生成图像与潜在代码最大化互信息时,我们还训练具有辅助分布Q的常规GAN。由于我们使用表达神经网络对Q进行参数化,我们可以假设Q可以合理地近似真实的后验概率P(c|x),因此在常规GAN中潜隐代码和生成图像之间几乎没有互信息。我们注意到,使用不同的神经网络架构,即使我们在实验中没有观察到这种情况,潜在代码和生成的图像之间可能存在更高的互信息。这种比较是为了证明在常规GAN中,不能保证生成器将利用潜在的代码。
Disentangled Representation
MINIST
为了从MNIST上的样式分离数字形状,我们选择使用一个分类代码c1对潜在代码进行建模,c1 Cat(K = 10, p = 0.1),可以模拟数据中的不连续变化,以及可以捕获本质上连续变化的两个连续代码:c2, c3 Unif(−1, 1)。
在图2中,我们显示离散码c1捕获形状的剧烈变化。更改分类代码c1在大多数时间之间可以切换数字。事实上,即使我们刚刚训练没有任何标签的InfoGAN,c1也可以用作分类器,通过将c1中的每个类别与数字类型进行匹配来实现对MNIST数字进行分类的5%错误率。在图2a的第二行,我们可以观察到一个数字7被分类为9。
连续代码c2,c3捕获样式的连续变化:c2控制旋转数字和c3控制宽度。 令人惊奇的是,在这两种情况下,生成器不仅仅是拉伸或旋转数字,而是调整其他细节,如厚度或笔触样式,以确保所得到的图像是自然的。作为检查InfoGAN学习的潜在表示是否是可概括的测试,我们以夸张的方式操纵潜在代码:而不是将潜在代码从-1映射到1,我们把它从-2映射到2,覆盖了一个广泛的地区,网络从来没有接受过训练,我们仍然得到有意义的泛化。

图2:在MNIST上操纵潜在代码:在所有潜在代码操纵图中,我们将使用以下约定:每个潜在代码在左右方向上变化,而其他潜在代码和噪声是固定的。不同的行对应于固定潜码和噪声的不同随机样本。例如,在(a)中,一列包含c1中同一类别的五个样本,一行显示了c1中10个可能类别的生成图像,并固定了其他噪声。在(a)中,c1中的每个类别在很大程度上对应于一个数字类型;在(b)中,未经信息正规化训练的GAN的c1值变化会导致无法解释的变化;在(c)中,c2的较小值表示左倾斜数字,而高值表示右倾斜数字。在(d)中,c3平滑地控制宽度。我们将(a)重新排序以进行可视化,因为分类代码本质上是无序的。
面部和椅子
接下来,我们在3D图像的两个数据集上评估InfoGAN:面部和椅子,它们是DC-IGN显示学习高度可解释的图形代码的数据集。
在面部数据集上,DC-IGN通过使用监督学习将潜在因素表示为方位角(姿势),仰角和照明作为连续潜在变量。使用相同的数据集,我们展示了InfoGAN学习了一个解开的表示,可以恢复同一数据集上的方位角(姿态),高程和照明。在这个实验中,我们选择用五个连续代码对潜在代码进行建模,ci~Unif(-1,1),1 ≤ i ≤ 5。

图3:在3D面孔上操纵潜在代码:当输出值从-1到1变化时,我们显示了学习到的连续潜在因子对输出的影响。在(a)中,我们显示了一个连续潜在代码一致地捕获了 不同形状的脸部方位角; 在(b)中,连续代码捕获高程; 在(c)中,连续代码捕获照明的方向; 最后,在(d)中,连续代码学习在宽脸和窄脸之间进行插值,同时保留其他视觉特征。 对于每个因素,我们提供的表示与5个随机运行中的先前监管结果最相似[7],以提供直接比较。
由于DC-IGN需要监督,以前无法学习未标记的变体的潜在代码,因此无法从数据中自动发现显著的潜在变异因素。相比之下,InfoGAN能够自己发现这样的变化:例如,在图3d中,即使在以前的工作中既不明确地生成或标记了该变量,也会学习平滑地将面部从宽变为窄的潜在代码。
在椅子数据集上,DC-IGN可以学习代表旋转的连续代码。 InfoGAN再次能够学习与连续代码相同的概念(图4a),另外InfoGAN还可以使用单个连续代码连续插入不同宽度的类似椅子类型(图4b)。在本实验中,我们选择用四个分类代码c1,c2,c3,c4对潜在因子进行建模。c1, c2, c3, c4 Cat(K = 20, p = 0.05)和一个连续码c5~Unif(-1,1)。

图4:在3D椅子上操纵潜在代码:在(a)中,我们显示了连续代码在保持椅子形状的同时捕获了椅子的姿势,尽管学习的姿势映射在不同类型上有所不同。 在(b)中,我们表明连续代码可以替代地学习捕获不同椅子类型的宽度,并在它们之间平滑地插值。 对于每个因素,我们提供的表示与5个随机运行中的先前监管结果最相似[7],以提供直接比较。
SVHN
接下来,我们对Street View House Number(SVHN)数据集进行InfoGAN评估,因为它是嘈杂的,而且含有可变分辨率和分离的数字的图像,因此学习一个可解释的表示更具挑战性,并且它没有相同的多个变体。在本实验中,我们利用四个10维分类变量和两个均匀连续变量作为潜在代码。我们在图5中显示了两个学习的潜在因素。

图5:在SVHN上处理潜在代码:在(a)中,我们显示了一个连续代码捕获了照明的变化,即使在数据集中每个数字仅在一个照明条件下出现; 在(b)中,显示了一种分类代码来控制中心数字的上下文:例如,在第二列中,右侧部分地出现了数字9,而在第三列中,则出现了数字0, 表示InfoGAN已学会将中心数字与其上下文分开。
CelebA
最后,我们在图6中显示,InfoGAN能够在另一个具有挑战性的数据集上学习许多视觉概念:CelebA ,其中包含200,000名具有较大姿态变化和背景混乱的名人图像。在这个数据集中,我们将潜在变量建模为10个统一的分类变量,每个维度都是10。令人惊讶的是,即使在这个复杂的数据集中,InfoGAN也可以像3D图像那样恢复方位角,即使在这个数据集中,多个姿势位置没有单个面。此外,InfoGAN可以解决其他高度语义的变化,如存在或不存在眼镜,发型和情感,表明在没有任何监督的情况下获得一定程度的视觉理解。

图6:在CelebA上操纵潜在代码:(a)表明分类代码可以通过离散化连续性的这种变化来捕获人脸的方位; 在(b)中,分类代码的一个子集专用于发出眼镜的信号; (c)表现出发型变化,从少发到多发大致有序; (d)表现出情绪变化,从严厉到快乐大致有序。
结论
本文介绍了一种称为信息最大化生成对抗网络(InfoGAN)的表示学习算法。 与之前的需要监督的方法相比InfoGAN完全没有监督,可以在具有挑战性的数据集上学习可解释和分解的表示。 另外,InfoGAN在GAN之上只增加了微不足道的计算成本,并且易于训练。 利用互信息诱导表征的核心思想可以应用于其他方法,如VAE,这是未来工作的一个具有前景的领域。这项工作的其他可能的扩展包括:学习分层潜在的表示,用更好的代码改善半监督学习,并使用InfoGAN作为一个高维数据发现工具。
