本文参考自http://cs229.stanford.edu/notes/cs229-notes3.pdf,但采用《统计学习方法》中的符号系统
数据集
D={(x(1),y(1)),(x(2),y(2)),⋯,(x(m),y(m))}
,
x(i)∈Rn
,
y(i)∈{−1,1}
超平面
wTx+b=0
,
w∈Rn
,
b∈R
假设数据集
D
线性可分,则存在超平面
wTx+b=0
,当
y(i)=1
时,
wTx(i)+b>0
,当
y(i)=−1
时,
wTx(i)+b<0
【立体几何知识】
点
(x0,y0,z0)
到平面
Ax+By+Cz+D=0
的距离为
d=|Ax0+By0+Cz0+D|A2+B2+C2−−−−−−−−−−−√
【几何间隔】
类似的,样本点
(x(i),y(i))
到超平面
wTx+b=0
的距离
γ(i)=∣∣wTx(i)+b∣∣∥w∥
,称为几何间隔
利用标签
y(i)
可去掉分子的绝对值符号,得到
γ(i)=y(i) (wTx(i)+b)∥w∥
对于数据集
D
,所有样本的几何间隔中的最小值,
γD=min{γ(1),γ(2),...,γ(m)}
,称为超平面
wTx+b=0
关于数据集
D
的几何间隔
【CS229上关于几何间隔的证明】
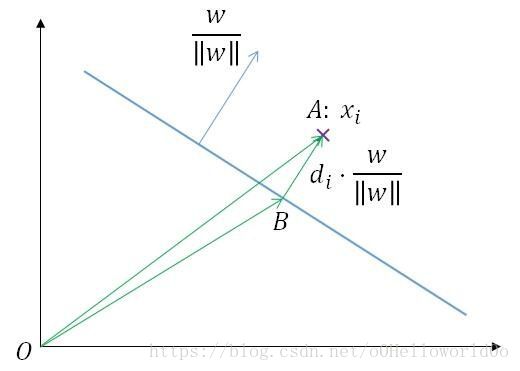

如图所示,
w∥w∥
为分类超平面
wx+b=0
的单位法向量,向量
OA−→−
的坐标(也是点
A
的坐标)为
xi
,样本
xi
离超平面的距离为
di
,则向量
BA−→−
的坐标为
di⋅w∥w∥
于是
OB−→−=OA−→−−BA−→−
,即向量
OB−→−
的坐标(也是点
B
的坐标)为
xi−di⋅w∥w∥
由于点
B
在超平面上,代入超平面方程,得
w(xi−di⋅w∥w∥)+b=0
解得
di=wxi+b∥w∥
【函数间隔】
超平面
wx+b=0
关于样本点
(xi,yi)
的函数间隔定义为几何间隔的
∥w∥
倍,即
γ=yi(wxi+b)
对于数据集
D
,所有样本的函数间隔中的最小值,
γD=min{γ1,γ2,...,γn}
,称为超平面
wx+b=0
关于数据集
D
的函数间隔
函数间隔与几何间隔的关系为
di=γi∥w∥
【间隔最大化】
SVM的目标是寻找一个几何间隔最大的超平面,最优化问题表达如下:
maxw,b dDs.t. yi(wxi+b)∥w∥⩾dD
代入
dD=γD∥w∥
,将几何间隔替换为函数间隔
maxw,b γD∥w∥s.t. yi(wxi+b)∥w∥⩾γD∥w∥
化简
s.t.
部分,得
maxw,b γD∥w∥s.t. yi(wxi+b)⩾γD
现在分析一下
γD
对最优解的影响
当
γD=1
时,得到一组最优解
w∗1
,
b∗1
,当
γD=2
时,得到一组最优解
w∗2
,
b∗2
这两组最优解的关系为:
w∗2=2w∗1
,
b∗2=2b∗1
,是成比例的,所以将
γD
取一个特殊值即可,此处取
γD=1
,于是得到
maxw,b 1∥w∥s.t. yi(wxi+b)⩾1
因为
maxw,b 1∥w∥⇔minw,b ∥w∥⇔minw,b ∥w∥2⇔minw,b 12∥w∥2
所以得到最终的线性可分SVM的最优化问题为:
minw,b 12∥w∥2s.t. yi(wxi+b)⩾1
我们已经得到了SVM的原始问题
minw,b 12∥w∥2
s.t. 1−yi(wxi+b)⩽0
这个问题属于凸二次规划问题,已经可以使用相关的算法包来求解了,但是《机器学习》(周志华)中说“我们可以有更高效的解法”,这个更高效的解法就是转而去解原始问题对应的对偶问题
对于SVM,原始问题和对偶问题是等价的(
d∗=p∗
),所以求得了对偶问题的最优解
d∗
,就相当于得到了原始问题的最优解
p∗
【SVM的对偶问题】
对偶问题都是从定义拉格朗日函数开始的
L(w,b,α)=12∥w∥2+∑i=1nαi[1−yi(wxi+b)]=12∥w∥2−∑i=1nαiyi(wxi+b)+∑i=1nαi=12∥w∥2−∑i=1nαiyixiw−∑i=1nαiyib+∑i=1nαi=12∥w∥2−w∑i=1nαiyixi−b∑i=1nαiyi+∑i=1nαi
求解对偶问题实际上是求解拉格朗日函数的极大极小问题:
maxα:αi⩾0minw,bL(w,b,α)
(记住对偶问题是先挑“矮个儿”再挑“高个儿”,先处理原变量,再处理对偶变量)
第一步,求
minw,bL(w,b,α)
,其中
w,b
为变量,
α
为常量同时消去变量
w,b
令
∇wL(w,b,α)=w−∑i=1nαiyixi=0
∇bL(w,b,α)=−∑i=1nαiyi=0
得
w=∑i=1nαiyixi
∑i=1nαiyi=0
上述2个式子的意义略有区别,式1中可将变量
w
用变量
α
代替,而式2却不包含变量
b
,是一个实实在在的约束条件,需要将该约束条件带到第二步中
但不管怎样,将上述2个式子代入
L(w,b,α)
中,总可以消去变量
w
,
b
(注意:在第2项中,当代入
w=∑i=1nαiyixi
时,因为
L(w,b,α)
中使用过了下标
i
,因此需要把下标
i
换为
j
)
minw,bL(w,b,α)=12∥w∥2−w∑i=1nαiyixi−b∑i=1nαiyi+∑i=1nαi=12∑i=1n∑j=1nαiαjyiyjxixj−(∑j=1nαjyjxj)(∑i=1nαiyixi)−b⋅0+∑i=1nαi=12∑i=1n∑j=1nαiαjyiyjxixj−∑i=1n∑j=1nαiαjyiyjxixj+∑i=1nαi=−12∑i=1n∑j=1nαiαjyiyjxixj+∑i=1nαi
即
minw,bL(w,b,α)=−12∑i=1n∑j=1nαiαjyiyjxixj+∑i=1nαi
(仅包含变量
α
)
第二步,求
maxα:αi⩾0minw,bL(w,b,α)
,即得到如下的对偶问题
maxα −12∑i=1n∑j=1nαiαjyiyjxixj+∑i=1nαi
s.t. ∑i=1nαiyi=0
(在第一步中得到的约束条件,照抄过来)
αi⩾0
因为对于原始问题,
12∥w∥2
和
1−yi(wxi+b)
均为凸函数,没有等式约束,并且存在
(w,b)
使得所有不等式约束
1−yi(wxi+b)⩽0
成立(因为规定了数据集线性可分)
所以存在一组
(w∗,b∗,α∗)
,满足
p∗=d∗=L(w∗,b∗,α∗)
故求解对偶问题等价于求解原始问题,即求解对偶问题得到的最优解其实就是原始问题的最优解
【KKT条件】
原问题的约束
①
1−yi(wxi+b)⩽0i=1,2,⋯,n
梯度等于0
②
∇wL(w,b,α)=0⇒w=∑i=1nαiyixi
③
∇bL(w,b,α)=0⇒∑i=1nαiyi=0
不等式约束的拉格朗日乘子大于等于0
④
αi⩾0i=1,2,⋯,n
对偶互补条件
⑤
αi[1−yi(wxi+b)]=0i=1,2,⋯,n
【求解对偶问题】
maxα −12∑i=1n∑j=1nαiαjyiyjxixj+∑i=1nαi
s.t. ∑i=1nαiyi=0
αi⩾0
该对偶问题是凸二次规划问题,仍然可以使用现成的算法包求解,但仍然不够高效(该问题的规模正比于训练样本数——《机器学习》周志华),因此根据该问题定制了一个更高效的算法,即SMO算法
求解对偶问题(使用SMO算法),得到最优解
α∗
,此时任务还没有完成,还需要利用
α∗
,求出
w∗
,
b∗
对于
w∗
,利用KKT条件②计算:
w∗=∑i=1nα∗iyixi
对于
b∗
,有KKT条件⑤成立:中的对偶互补条件
α∗i[1−yi(w∗xi+b∗)]=0
成立
对于
α∗
中的一个满足
α∗j>0
的分量
α∗j
,有
α∗j[1−yj(w∗xj+b∗)]=0⇒1−yj(w∗xj+b∗)=0
yj(w∗xj+b∗)−1yj(w∗xj+b∗)−y2jw∗xj+b∗−yjb∗b∗b∗=0=0(使用y2j替换1)=0=yj−xjw∗=yj−xj∑i=1nα∗iyixi(代入w∗=∑i=1nα∗iyixi)=yj−∑i=1nα∗iyixixj
综上所述,使用
α∗
计算
w∗
,
b∗
的公式为
w∗=∑i=1nα∗iyixi
b∗=yj−∑i=1nα∗iyixixj
(样本
(xj,yj)
对应的
αj>0
)
理论上有多少个支持向量,就能算出多少个参数
b∗
,这时,对所有
b∗
求平均值即可
计算出
w∗
,
b∗
之后,对于一个未知的样本
xtest
,我们需要计算
wTxtest+b
我们仍然将
w
展开,看看会得到什么
wTxtest+b=(∑i=1nαiyixi)Txtest+b=∑i=1nαiyi⟨xi,xtest⟩+b
我们发现,除了支持向量以外的
αi
都是等于
0
的,
xtest
只需要与支持向量做内积即可