影响力
社会影响力是指在社会网络中个人受到他人影响而产生的行为变化。其强度取决于多种情况,如网络中人与人之间关系的亲密程度,网络中人与人之间的距离,时间因素,网络及网络中个人的特点。
对于代表性影响力度量的理解与实现:
- 中心性(Centrality):对于具有更多连接关系的结点,度中心性度量方法认为它们具有更高的中心性。
- 特征向量中心度(Eigenvector centrality)[]:用邻居结点的重要性来概括本结点的重要性
- Katz中心度:特征向量中心性度量中,会有这么一个问题:某个点被大量的关注,但是关注该点的点的中心性很低(甚至为0),这样会导致网络中存在被大量关注但中心值却为0的点,需要在特征向量中心性度量的基础上加入一个偏差项(或者说是中心值下限),来解决这个问题。
- PageRank值:Katz在某些情况下存在一些与特征向量中心性相似的问题。在有向图中,一旦一个结点成为一个权威结点(高中心值结点),它将向它所有的外连接传递其中心性,导致其它结点中心性变的很高。但这是不可取的,因为不是每一个被名人所知的人都是有名的(比如科比的小学同学)因此我们在katz中心性的基础上,累加时让每一个邻居的中心性除以该邻居结点的出度,这种度量称为PageRank。、
影响力传播模
独立级联模型
独立级联模型(Independent Cascade ModelIC模型)[]是一种概率模型,当个节点v被激活时,它会以概率Pvw对它未激活的出边邻居节点w尝试激活,这种尝试仅仅进行一次,而且这些尝试之间是相互独立的,即V对w的激活不会受到其它节点的影响。独立级联模型的信息传播过程为:
(1) 给定初始的活跃节点集合s,当在时刻1节点v被激活后,它就获得了一次对它的邻居节点w产生影响的机会,成功的概率为Pomn是随机赋子的系统参数,其自身独立不受其它节点的影响,该值越大,节点w越有可能被影响。
(2)若w有多个邻居节点都是新近被激活的节点,那么这些节点将以任意顺序尝试激活节点w。如果节点v成功激活节点w,那么在1+1时刻,节点w转为活跃状态。
(3)在1+1时刻,节点w将对其它节点产生影响,重复上述过程。
需要注意的是,在上述传播过程中,在1时刻无论节点v是否能成功激活它的邻居节点,在以后的时刻中,v本身虽然仍保持活跃状态,但它已经不再具备影响力,即在1时刻被激活的节点,已经尝试激活它自身的邻居节点后,在1+1时刻仍然处于活跃状态,但它本身已经不能去激活其它任何节点,这一类节点成为无影响力的活跃节点。当网络中不存在有影响力的活跃节点时,传播过程结束。

线性阈值模型
线性阈值模型(Linear Threshold Model LT模型)是一种价值积累模型,它对每个节点v都有一个激活阈值θ∈[0.1]。线性阈值模型的信息传播过程如下:
(1)给定集合中的任意节点v随机分配阙值θ∈[0.1],该阈值表示这个节点受影响的难易程度,θ越小,表示节点v越容易被影响,θ越大,表示该节点v越难被影响。只有当节点v的新处于激活状态的邻居节点对它的影响力大于该阈值时,节点v才能被激活;
(2)用权值bwv表示节点v被它的邻居节点w的影响,集和bw≤1表示节点v的处于活跃状态的邻居节点对它的影响力之和。这里in(v)是v的入边邻居节点集合。
(3)给定初始的活跃节点集合A (网络中其余所有节点均处于非活跃状态),给网络中每个节点任意分配-一个阈值,在1时刻,所有在1-1时刻处于活跃状态的节点仍保持活跃,并且当这一时刻节点 v的邻居节点的影响力之和大于节点v的阈值时,节点v被激活,即节点v被激活的条件是v已激活的入边邻居对v的积累影响大于v的激活阈值。
(4)节点v被激活后,下一时刻将对它的邻居节点产生影响,重复上述过程。
在IT传播模型中,当网络中已存在的所有活跃节点中任意活跃节点的影响力之和都不能激活他们的处于非活跃状态的邻居节点时,传播过程结束。

俩种模型的区别
LT模型描述的是信息是以概率形式进行传播,IC模型主要描述的是信息传播后,如何进行收敛。
LT的激活过程是确定的,而IC是不确定的。
LT模型的激活工程是一种合作激活的过程,每次激活尝试都会被积累下来。而IC不是。
贪心算法
Kempe等作者(9首次提出了使用贪心算法求解影响力最大化问题,求解K个初始的激活节点使最终影响力达到最大的公式如下:
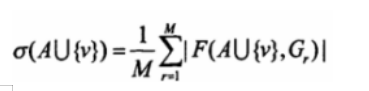
算法的基本思想是:其中M是给定的模拟传播次数,通过M次的模拟传播得到M张模拟传播图,初始时刻给定的激活节点集合A为空集。初始时刻对于给定的任何一定节点v,在每张传播结果图G,上计算其可达的节点集合F(v,G,),然后累加|F(v,G,)|再除以传播次数M得到每个节点的平均影响力,将平均影响力最大的节点加入到A中得到第一个初始的激活节点。然后继续下一个初始的激活节点查找。此时尝试将每个节点加入到A中,并计算AU{v}的后继集F(AU{v},G,) ,累加|F(AU{v},G,)|后求平均值,从平均值中得到第二个平均影响力最大的节点,将其加入初始的节点集A中。重复以上的步骤,直到|A|=k 为止。算法终止,这样就可以得到初始的k个平均影响力最大的激活节点。
对贪心算法流程进行详细的描述:
输入:社会网络G和初始的激活节点个数K
输出:影响力最大的K个初始节点集合和被影响的节点总数
(1): readFile(File *file);//读取网络
(2): buildModels(int model)//根据参数model决定构建IC和LT模型
(3: simulateModels(int model,int num);//模拟传播模型
(4: A←空;
(5: infuence[n]← 0,n=|V|;//一张传播图上各节点所产生的影响力
(6: sum[n]← 0,n =|V|;//M张传播图上各节点所产生的影响力总和得到初始节点集合并计算影响力 (7: for(i=1 to k) do
(8: sum[n]←0;
(9: for(r=1 to M)do // M张传播结果模拟图
(10: T←A;
(11: influence[n]←0
(12: for(j=1 to N)do //v[j]属于V
(13: T←TU{v[j]} /尝试将v[j]加入A中后计算A的后继集
(14: F(j)←F(T,G[r])
(15: infuence[j]←|F[j]|;
(16: sum[j]←sum[i] + influence[j];
(17: end for
(18: end for
(19: v←find max(sum);//找出sum值最大的节点v
(20: A←AU{v}
(21: end for
//返回: A 为初始的k个激活节点,max(sum)为最终 被影响的节点个数
(22: return A and max(sum/M);
其中求传播图Gr中集合T可达的节点集合F(T,Gr),针对每个节点的可达性分析可以o(m)内完成,其中m为边数。此外算法还有三层for循环,时间复杂度为0(kMn)因此整个算法的时间复杂度为O(kMnm),其中k为给定的初始激活节点个数,m为网络边的数量,n为网络的节点个数,M给定的模拟传播次数。
贪心算法求解影响力最大化结构简单,易于理解,kempe等作者指出贪心算法最大的优点是能得到稳定的解,算法的结果至少能保证得到最优解的63%。 但是它也有严重的缺点,时间复杂度非常高,对于一般上百个节点的网络,都需要较长的时间来完成搜索初始节点的工作,更别说上千上万以上的大型网络,因此贪心算法只适合于小型网络。
贪心算法的改进见我的论文^~^