感觉期望最大化是个比较绕的东西,一直都知道, 它是NLP很基础的知识,但是貌似每次都理解不透,看了忘,忘了看。经常见到,却又不能表述的清清楚楚。这次决定下点功夫能把它说明白。
希望我这篇不是让你能了解整个森林的文章,而是让你了解森林概貌的文章,细节问题请自己去深究~~
本人才疏学浅,如果有错误,请不吝赐教~~
废话说完了,进入正文~~~
一、 EM思想
1.1 EM算法思想
EM算法是常用的在含有隐变量的情况下,估计模型参数的利器(训练完成后最终还可以求得隐变量的参数值)。其基本思想是:
1. 首先初始化模型参数θ;
2. 然后根据训练数据和当前的模型参数θ推断出最优隐变量Z的值(即求Z的期望,E步);
3. 基于训练数据和Z的最优期望值对参数θ做极大似然估计(M步);
4. 迭代的将2、3交替进行,直到收敛到局部最优解。
由于会收敛到局部最优解,EM算法对初值敏感,对于不同的初始值,可能会导致不同的结果,并且它对于“躁声”和孤立点数据也是敏感的,少量的该类数据能够对模型产生极大的影响。
实际上若隐变量的情况已知,那么我们可以直接根据最大似然估计和随机梯度下降,解出在每一种隐变量情况下的参数和最大似然估计值,然后选择似然估计最大情况下的模型和隐变量。(这两句看不懂可以先跳过)
感觉这个思想是说的最简洁和通俗易懂的,但是看起来仍然是有点绕。但是怎么说好呢, 我们不防拿个例子来说一下,就容易理解多了。
1.2 KMeans算法原理
想来大家对KMeans都比较了解吧, 应该也都能说的上来具体的原理。(如果刚好还没学到KMeans,不妨看看这篇 聚类算法(七)—— Kmeans(含标签聚类和文本聚类代码))
找到它的最优解需要考察样本集D所有可能的簇划分,这是一个NP难问题,因此k-means算法采用了贪心策略,通过迭代优化来近似求解,算法流程如下:
1. 从D中随机选择k个样本作为初始质心;(k为超参数)
2. 将所有样本点归类到距离质心最近的簇中;
3. 重新计算簇的质心作为新的质心;
4. 迭代的将2、3交替进行,直到收敛到局部最优解。
可以发现,k-means算法和EM算法原型惊人的相似,其实k-means就是EM算法的一种特殊实现。我们的模型参数是簇的质心,根据簇的质心将所有样本点归类到距离质心最近的簇中(E),重新计算簇的质心作为新的质心使损失函数式(9.24)最小化(M)。因此,k-means具有EM算法的所有缺点,并且仅适合发现类圆形状的簇。
这样套过来是不是就好理解很多了。
1.3 通俗理解EM思想
我们看看怎么套过来的, 猛一看还挺像,但是具体是怎么对应的呢?
这里,KMeans初始化的中心点(质心)就是EM算法中的参数θ,想一下,如果最优质心确定了,那KMeans聚类结果是不是就能定下来了,就是我们最后得到的聚类结果了? 所以KMeans的目的是得到最优的聚类结果,将其转化成求解最优质心的任务。对应EM算法中的参数θ。
下面就开始对应了
初始化参数θ->初始化质心
根据训练数据和θ推断最优隐变量Z(求Z期望)-> 通过质心得到初步聚类结果
通过Z和训练数据对参数θ做极大似然估计 -> 根据当前聚类结果更新质心
迭代直到收敛 -> 迭代直到收敛
是不是惊人的相似,那现在理解EM思想以及KMeans怎么用到EM思想了吗
二、最大似然
是不是还有疑问,虽然说KMeans理解了,但是EM中最大似然和Z指的是什么啊?好像跟KMeans不太一样呢。 那我们来解释一下最大似然估计。 Z其实我理解吧,就是你想要得到的最后的结果,等下讲完最大似然,估计你能对Z有一些想法。
2.1 贝叶斯公式
P(A|B)=P(B|A)P(A)P(B)
贝叶斯公式想必大家都见过,就不过多解释了,但是我这里不拿通俗的AB来解释,我们NLP通常用到最大似然,都是来估计模型的,这里我给换个公式:
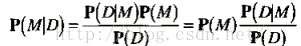
D代表数据,M代表模型,P(M|D) 是后验概率,表示我想要根据训练数据D,来训练得到我最想要的模型M.
详细说,算法我们已经选好了,M就应该是选的模型对应的最优参数,这就是我们通过数据训练得到的模型参数.
再详细点说,对于一个任务, 我们假设y= Fθ(x)是问题的解,其中θ是函数F的参数,x是输入的观测量,y是预测的结果。 那对于我们来说,我们想要根据我们的数据D,来求得能解决我们目前任务的函数对应的θ参数,注意这里F是你自己选的,就好像是你有了训练数据,去求一个问题的时候,你选择的算法一样,不管你用SVM,LR,RNN,那都是你自己选的,选完了这个F就定下来了,但是对应的参数是可变的,就是你通过不同的数据可能训练得到不同的参数,其实就是我们常说的模型,不知道我有没有说清楚。
一句话就是通过数据,想要得到模型对应的最优的参数θ。
这个就是后验概率P(M|D)啦。
再来看看其它的成分都是啥, P(M), 先验概率,表示模型各个参数的选择是独立的,比如θ的取值是[1,2,3,4],那选每个参数的概率都是0.25,所以这里先验概率在不同参数选择独立的前提下,可以当作一个固定不变的值。 P(D)是当前数据的概率,数据是不变的,那对应的概率对于不同的参数θ, P(D)是不变的。
那既然 P(M)和P(D)都是固定的,那求最大的P(M|D) 就等同于去求最大的 P(D|M),也就是求解最大似然。
那我们来看下 P(D|M),怎么理解, 已知一个模型,他能出现数据的概率,那就是我先给一个参数,看看这些参数对于y= Fθ(x),得到的样本D中 使得 (x,y)成立的概率,概率越大,表示越正确。
这块有疑问可以看下 机器学习 之 贝叶斯分类(上) 这篇
再啰嗦一句,上面EM思想中的隐藏变量Z,就好比这里的y值,也就是我们给数据预测的标签。
2.2 最大似然估计
问题定义完了,最后我们来看下,最大似然怎么求,取所有可能的θ值一个一个算下吗?
可以对P(D|M)求导,导数为0,即可得最大值,而通常为了方便计算,一般会先取对数,再求导,这样并不影响最后的结果,但是计算起来 却方便了很多。
具体怎么计算,我就不多说了,有兴趣可以找个 损失函数是最大似然的算法自己推一下看看。
还想啰嗦一句,其实KMeans和EM思想很像,但是KMeans却没有用到最大似然哦~~
三、 参考链接
详解最大似然估计(MLE)、最大后验概率估计(MAP),以及贝叶斯公式的理解
K-Means算法的收敛性和如何快速收敛超大的KMeans?
对你有用就点赞关注吧~~ (●'◡'●)