大话数据结构系列之快速排序算法
实现思路
1、属于冒泡排序的升级版,都是通过不断的比较和移动交换来实现排序,它的实现,增大了记录的比较和移动的距离,将关键字较大的记录从前面直接移动到后面,关键字较小的记录从后面直接移动到前面,从而减少了总的比较次数和移动交换次数。
2、通过一趟排序将待记录分割成独立的两部分,其中一部分记录的关键字均比另一部分记录的关键字小,则可分别对这两部分记录继续进行排序,以达到整个序列有序的目的。
重点知识
枢轴:
枢轴左边的值都比它小,右边的值都比它大
Partition 函数(用来寻找枢轴,进行表划分):
其实就是将选取的 pivotkey 不断交换,将比它小的换到它的左边,比它大的换到它的右边,它也在交换中不断更改自己的位置,直到完全满足这个要求为止。
如果每次 pivotkey 选择的值都最优,那么递归的深度就越浅,那么时间性能就越好
复杂度分析:
空间复杂度为O[nlogn]——O[n]
时间复杂度为 O[nlogn] —— O[n2]
快速排序法的时间复杂度推导过程:


使用数学归纳法进行推导:https://blog.csdn.net/weixin_39966065/article/details/104157850
代码实现
package com.example.sort;
import java.util.Arrays;
public class QuickSortTest {
public static void main(String[] args){
//基础数据
int[] sortList2 = {0,1,4,3,10,9,6,7,8,5,2,20,18,16,11,13,15,14,17,19,12};
System.out.println(Arrays.toString(sortList2));
quickSort(sortList2);
System.out.println(Arrays.toString(sortList2));
}
public static void quickSort(int[] list){
qSort(list,0,list.length-1);
}
public static void qSort(int[] list, int low, int high){
int pivot;
if(low < high){
pivot = partition(list,low,high);
//分别对高低子表进行排序
qSort(list,low,pivot-1);
qSort(list,pivot+1,high);
}
}
//采用尾递归:将递归转换为迭代问题
public static void qSort2(int[] list, int low, int high){
int pivot;
while(low < high){
pivot = partition(list,low,high);
//分别对高低子表进行排序
qSort2(list,low,pivot-1);
low = pivot + 1;
}
}
public static int partition(int[] list, int low, int high){
int pivotkey;
pivotkey = list[low];
while(low < high){
while( low < high && list[high] >= pivotkey)
high--;
swap(list,low,high);
while( low < high && list[low] <= pivotkey)
low++;
swap(list,low,high);
}
return low;
}
public static int partition1(int[] list, int low, int high){
int pivotkey;
//优化获取枢轴 //1
//三数取中法:至多增加了3次比较和3次交换指令,而实现了枢轴选取的合理性
int m = low + (high - low)/2;
if(list[low] > list[high])
swap(list,low,high);
if(list[m] > list[high])
swap(list,high,m);
if(list[m] > list[low])
swap(list,m,low);
pivotkey = list[low];
//优化不必要的交换操作 //2
//将枢轴值备份到 0 的位置
list[0] = pivotkey;
while(low < high){
while( low < high && list[high] >= pivotkey)
high--;
list[low] = list[high];
//swap(list,low,high);
while( low < high && list[low] <= pivotkey)
low++;
list[high] = list[low];
//swap(list,low,high);
}
list[low] = list[0];
return low;
}
public static void swap(int[] list, int i, int j){
int temp = list[i];
list[i] = list[j];
list[j] = temp;
}
}
优化策略
1、优化选取枢轴
// 默认代码中: pivotkey = list[low]; 并不适用于所有的情景(当所有值都倒序或者正序时,获取的值没有太大意义)
随机选择枢抽的方式更适用于大多数情况,使得获取的枢轴更合理
三数取中法(median-of-three)
取三个关键字先进行排序,将中间数作为枢轴,一般是取左端、右端和中间三个数。
2、优化不必要的交换
3、优化小数组时的排序方案
当 high - low 不大于某个常数时,就可以直接用插入排序(在小数组排序中,性能最好),这样就能保证最大化地利用两种排序的优势来完成工作。
4、使用尾递归方式减少递归层数
算法比较
1、从最好情况看:
如果你的待排序序列总是基本有序,冒泡排序和直接插入排序更胜一筹。时间复杂度都接近 O[n]
2、从最坏情况看:
堆排序和归并排序强过快速排序以及其它简单排序。
3、从平均情况,最好情况,最坏情况,空间复杂度,稳定性来比较
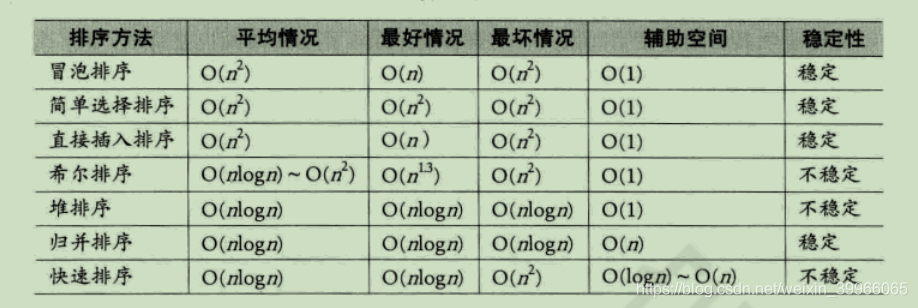
4、从移动次数来比较三种简单排序
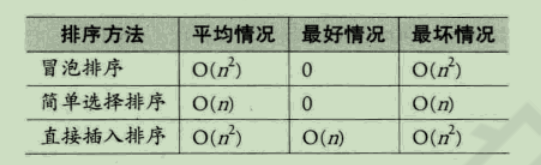
结论 :如果记录的关键字本身信息量比较大(例如:关键字都是数十位的数字),此时表明其占用存储空间很大,这样移动记录所花费的时间也越多。
5、为什么综合各项指标来说,经过优化的快速排序是性能最好的排序算法?
(1)从最坏情况来看,归并排序比快速排序好
(2)从最好情况看,两者相当 ?
快速排序:
最好:nlogn | 最坏:n(n-1)/2
(3)从稳定性看,归并排序具有稳定性
(4)从辅助空间上看,归并排序比快速排序略次(空间一般都不是问题)
(5)从内存占用上看,无递归的归并排序比快速排序有优势
待自我论证,使用合适的数据规模
参考文章:https://blog.csdn.net/qq_36770641/article/details/82669788
与各位共勉
数据结构和算法对于程序员的人生来说,那就是两个圆圈的交集部分,用心去掌握它,你的编程之路将会是坦途。
—— 程杰
You got a dream, you gotta protect it. People can’t do something themselves, they wanna tell you can’t do it. If you want something, go get it, Period.
《当幸福来敲门》
